 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Imitation Learning via Next-Token Prediction
Aug 28, 2024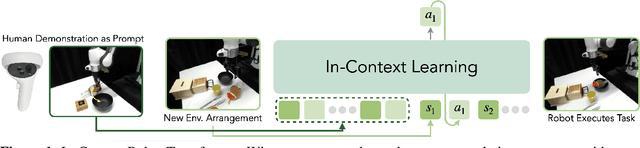
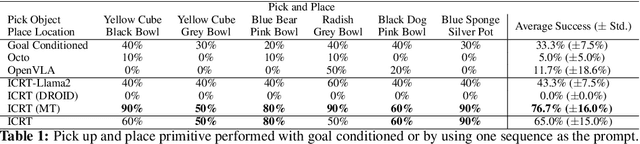
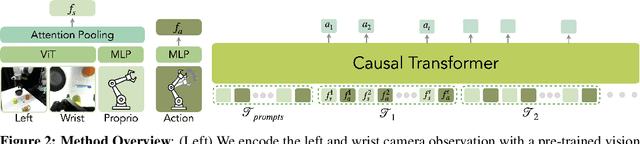
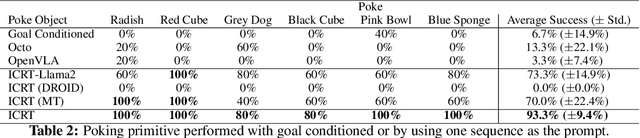
We explore how to enhance next-token prediction models to perform in-context imitation learning on a real robot, where the robot executes new tasks by interpreting contextual information provided during the input phase, without updating its underlying policy parameters. We propose In-Context Robot Transformer (ICRT), a causal transformer that performs autoregressive prediction on sensorimotor trajectories without relying on any linguistic data or reward function. This formulation enables flexible and training-free execution of new tasks at test time, achieved by prompting the model with sensorimotor trajectories of the new task composing of image observations, actions and states tuples, collected through human teleoperation. Experiments with a Franka Emika robot demonstrate that the ICRT can adapt to new tasks specified by prompts, even in environment configurations that differ from both the prompt and the training data. In a multitask environment setup, ICRT significantly outperforms current state-of-the-art next-token prediction models in robotics on generalizing to unseen tasks. Code, checkpoints and data are available on https://icrt.dev/
A Touch, Vision, and Language Dataset for Multimodal Alignment
Feb 20, 2024Touch is an important sensing modality for humans, but it has not yet been incorporated into a multimodal generative language model. This is partially due to the difficulty of obtaining natural language labels for tactile data and the complexity of aligning tactile readings with both visual observations and language descriptions. As a step towards bridging that gap, this work introduces a new dataset of 44K in-the-wild vision-touch pairs, with English language labels annotated by humans (10%) and textual pseudo-labels from GPT-4V (90%). We use this dataset to train a vision-language-aligned tactile encoder for open-vocabulary classification and a touch-vision-language (TVL) model for text generation using the trained encoder. Results suggest that by incorporating touch, the TVL model improves (+29% classification accuracy) touch-vision-language alignment over existing models trained on any pair of those modalities. Although only a small fraction of the dataset is human-labeled, the TVL model demonstrates improved visual-tactile understanding over GPT-4V (+12%) and open-source vision-language models (+32%) on a new touch-vision understanding benchmark. Code and data: https://tactile-vlm.github.io.
IIFL: Implicit Interactive Fleet Learning from Heterogeneous Human Supervisors
Jun 27, 2023



Imitation learning has been applied to a range of robotic tasks, but can struggle when (1) robots encounter edge cases that are not represented in the training data (distribution shift) or (2) the human demonstrations are heterogeneous: taking different paths around an obstacle, for instance (multimodality). Interactive fleet learning (IFL) mitigates distribution shift by allowing robots to access remote human teleoperators during task execution and learn from them over time, but is not equipped to handle multimodality. Recent work proposes Implicit Behavior Cloning (IBC), which is able to represent multimodal demonstrations using energy-based models (EBMs). In this work, we propose addressing both multimodality and distribution shift with Implicit Interactive Fleet Learning (IIFL), the first extension of implicit policies to interactive imitation learning (including the single-robot, single-human setting). IIFL quantifies uncertainty using a novel application of Jeffreys divergence to EBMs. While IIFL is more computationally expensive than explicit methods, results suggest that IIFL achieves 4.5x higher return on human effort in simulation experiments and an 80% higher success rate in a physical block pushing task over (Explicit) IFL, IBC, and other baselines when human supervision is heterogeneous.
Efficient Preference-Based Reinforcement Learning Using Learned Dynamics Models
Jan 11, 2023



Preference-based reinforcement learning (PbRL) can enable robots to learn to perform tasks based on an individual's preferences without requiring a hand-crafted reward function. However, existing approaches either assume access to a high-fidelity simulator or analytic model or take a model-free approach that requires extensive, possibly unsafe online environment interactions. In this paper, we study the benefits and challenges of using a learned dynamics model when performing PbRL. In particular, we provide evidence that a learned dynamics model offers the following benefits when performing PbRL: (1) preference elicitation and policy optimization require significantly fewer environment interactions than model-free PbRL, (2) diverse preference queries can be synthesized safely and efficiently as a byproduct of standard model-based RL, and (3) reward pre-training based on suboptimal demonstrations can be performed without any environmental interaction. Our paper provides empirical evidence that learned dynamics models enable robots to learn customized policies based on user preferences in ways that are safer and more sample efficient than prior preference learning approaches.
Learning to Efficiently Plan Robust Frictional Multi-Object Grasps
Oct 13, 2022

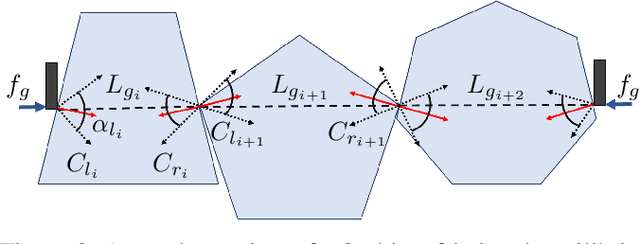

We consider a decluttering problem where multiple rigid convex polygonal objects rest in randomly placed positions and orientations on a planar surface and must be efficiently transported to a packing box using both single and multi-object grasps. Prior work considered frictionless multi-object grasping. In this paper, we introduce friction to increase picks per hour. We train a neural network using real examples to plan robust multi-object grasps. In physical experiments, we find an 11.7% increase in success rates, a 1.7x increase in picks per hour, and an 8.2x decrease in grasp planning time compared to prior work on multi-object grasping. Videos are available at https://youtu.be/pEZpHX5FZIs.