 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DGS-CD: 3D Gaussian Splatting-based Change Detection for Physical Object Rearrangement
Nov 06, 2024We present 3DGS-CD, the first 3D Gaussian Splatting (3DGS)-based method for detecting physical object rearrangements in 3D scenes. Our approach estimates 3D object-level changes by comparing two sets of unaligned images taken at different times. Leveraging 3DGS's novel view rendering and EfficientSAM's zero-shot segmentation capabilities, we detect 2D object-level changes, which are then associated and fused across views to estimate 3D changes. Our method can detect changes in cluttered environments using sparse post-change images within as little as 18s, using as few as a single new image. It does not rely on depth input, user instructions, object classes, or object models -- An object is recognized simply if it has been re-arranged. Our approach is evaluated on both public and self-collected real-world datasets, achieving up to 14% higher accuracy and three orders of magnitude faster performance compared to the state-of-the-art radiance-field-based change detection method. This significant performance boost enables a broad range of downstream applications, where we highlight three key use cases: object reconstruction, robot workspace reset, and 3DGS model update. Our code and data will be made available at https://github.com/520xyxyzq/3DGS-CD.
gsplat: An Open-Source Library for Gaussian Splatting
Sep 10, 2024gsplat is an open-source library designed for training and developing Gaussian Splatting methods. It features a front-end with Python bindings compatible with the PyTorch library and a back-end with highly optimized CUDA kernels. gsplat offers numerous features that enhance the optimization of Gaussian Splatting models, which include optimization improvements for speed, memory, and convergence times. Experimental results demonstrate that gsplat achieves up to 10% less training time and 4x less memory than the original implementation. Utilized in several research projects, gsplat is actively maintained on GitHub. Source code is available at https://github.com/nerfstudio-project/gsplat under Apache License 2.0. We welcome contributions from the open-source community.
Fast Sparse View Guided NeRF Update for Object Reconfigurations
Mar 16, 2024Neural Radiance Field (NeRF), as an implicit 3D scene representation, lacks inherent ability to accommodate changes made to the initial static scene. If objects are reconfigured, it is difficult to update the NeRF to reflect the new state of the scene without time-consuming data re-capturing and NeRF re-training. To address this limitation, we develop the first update method for NeRFs to physical changes. Our method takes only sparse new images (e.g. 4) of the altered scene as extra inputs and update the pre-trained NeRF in around 1 to 2 minutes. Particularly, we develop a pipeline to identify scene changes and update the NeRF accordingly. Our core idea is the use of a second helper NeRF to learn the local geometry and appearance changes, which sidesteps the optimization difficulties in direct NeRF fine-tuning. The interpolation power of the helper NeRF is the key to accurately reconstruct the un-occluded objects regions under sparse view supervision. Our method imposes no constraints on NeRF pre-training, and requires no extra user input or explicit semantic priors. It is an order of magnitude faster than re-training NeRF from scratch while maintaining on-par and even superior performance.
Investigating Capsule Networks with Dynamic Routing for Text Classification
Sep 03, 2018
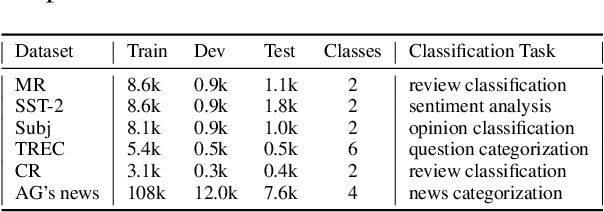
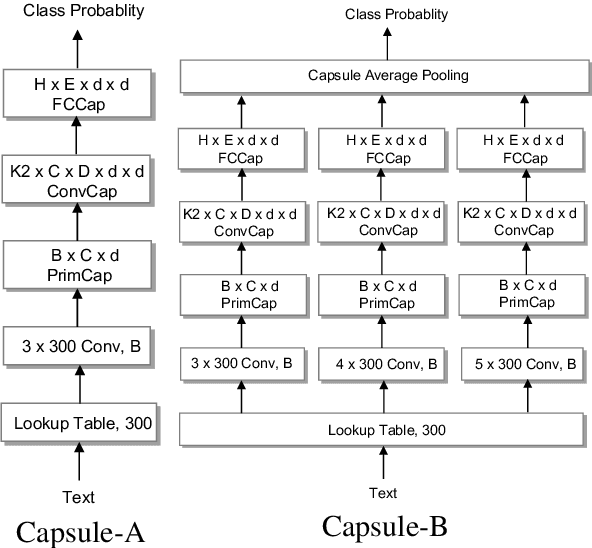
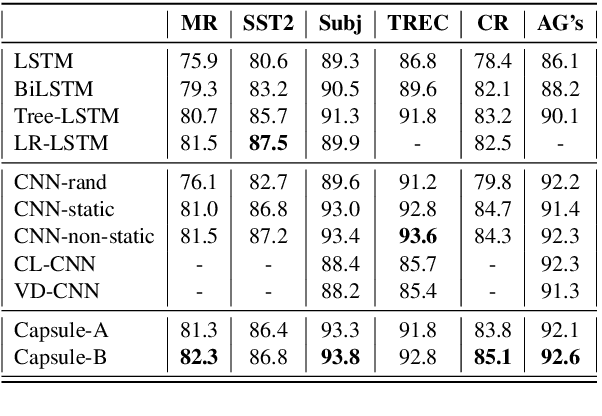
In this study, we explore capsule networks with dynamic routing for text classification. We propose three strategies to stabilize the dynamic routing process to alleviate the disturbance of some noise capsules which may contain "background" information or have not been successfully trained. A series of experiments are conducted with capsule networks on six text classification benchmarks. Capsule networks achieve state of the art on 4 out of 6 datasets, which shows the effectiveness of capsule networks for text classification. We additionally show that capsule networks exhibit significant improvement when transfer single-label to multi-label text classification over strong baseline methods. To the best of our knowledge, this is the first work that capsule networks have been empirically investigated for text modeling.
ARBEE: Towards Automated Recognition of Bodily Expression of Emotion In the Wild
Aug 28, 2018
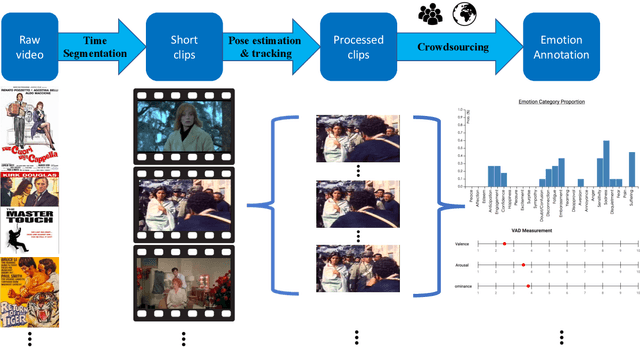
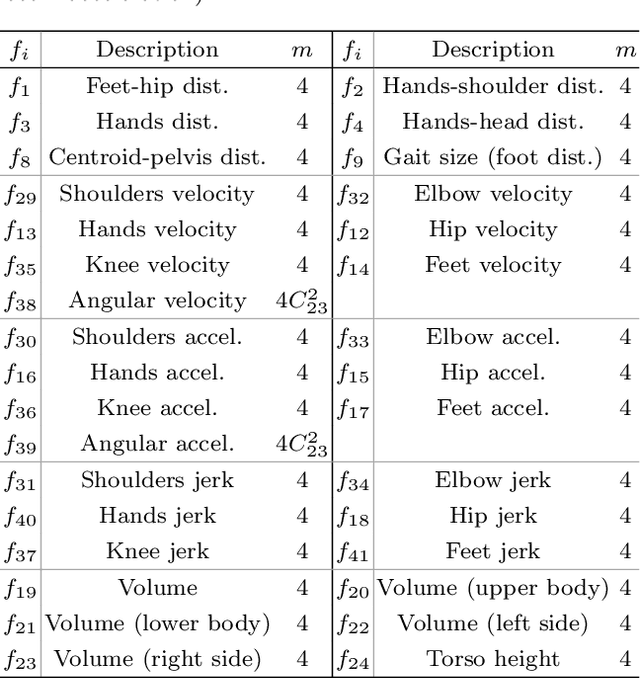
Humans are arguably innately prepared to possess the ability to comprehend others' emotional expressions from subtle body movements. A number of robotic applications become possible if robots or computers can be empowered with this capability. Recognizing human bodily expression automatically in unconstrained situations, however, is daunting due to the lack of a full understanding about relationship between body movements and emotional expressions. The current research, as a multidisciplinary effort among computer and information sciences, psychology, and statistics, proposes a scalable and reliable crowdsourcing approach for collecting in-the-wild perceived emotion data for computers to learn to recognize body languages of humans. To do this, a large and growing annotated dataset with 9,876 body movements video clips and 13,239 human characters, named BoLD (Body Language Dataset), has been created. Comprehensive statistical analysis revealed many interesting insights from the dataset. A system to model the emotional expressions based on bodily movements, named ARBEE (Automated Recognition of Bodily Expression of Emotion), has also been developed and evaluated. Our feature analysis shows the effectiveness of Laban Movement Analysis (LMA) features in characterizing arousal. Our experiments using a deep model further demonstrate computability of bodily expression. The dataset and findings presented in this work will likely serve as a launchpad for multiple future discoveries in body language understanding that will make future robots more useful as they interact and collaborate with humans.
Detecting Comma-shaped Clouds for Severe Weather Forecasting using Shape and Motion
Jun 06, 2018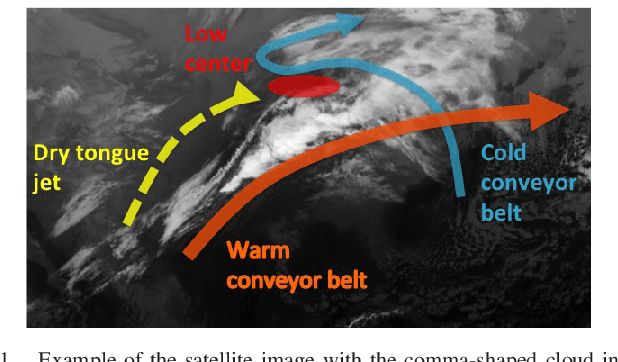

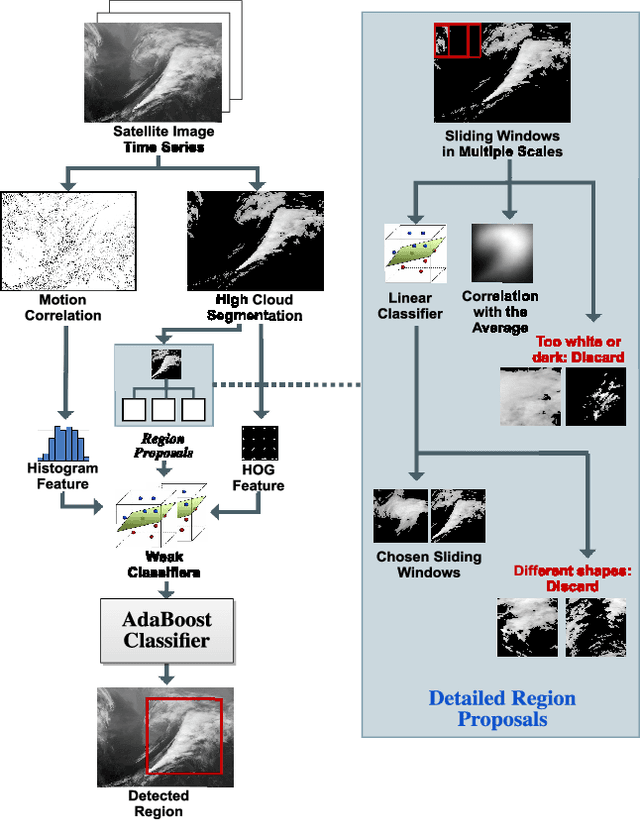
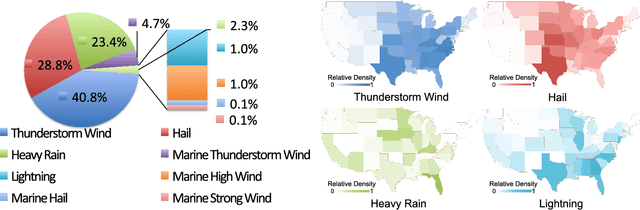
Meteorologists use shapes and movements of clouds in satellite images as indicators of several major types of severe storms. Satellite imaginary data are in increasingly higher resolution, both spatially and temporally, making it impossible for humans to fully leverage the data in their forecast. Automatic satellite imagery analysis methods that can find storm-related cloud patterns as soon as they are detectable are in demand. We propose a machine learning and pattern recognition based approach to detect "comma-shaped" clouds in satellite images, which are specific cloud distribution patterns strongly associated with the cyclone formulation. In order to detect regions with the targeted movement patterns, our method is trained on manually annotated cloud examples represented by both shape and motion-sensitive features. Sliding windows in different scales are used to ensure that dense clouds will be captured, and we implement effective selection rules to shrink the region of interest among these sliding windows. Finally, we evaluate the method on a hold-out annotated comma-shaped cloud dataset and cross-match the results with recorded storm events in the severe weather database. The validated utility and accuracy of our method suggest a high potential for assisting meteorologists in weather forecasting.
Rethinking the Smaller-Norm-Less-Informative Assumption in Channel Pruning of Convolution Layers
Feb 02, 2018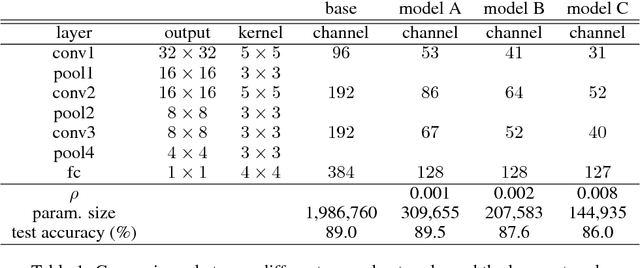
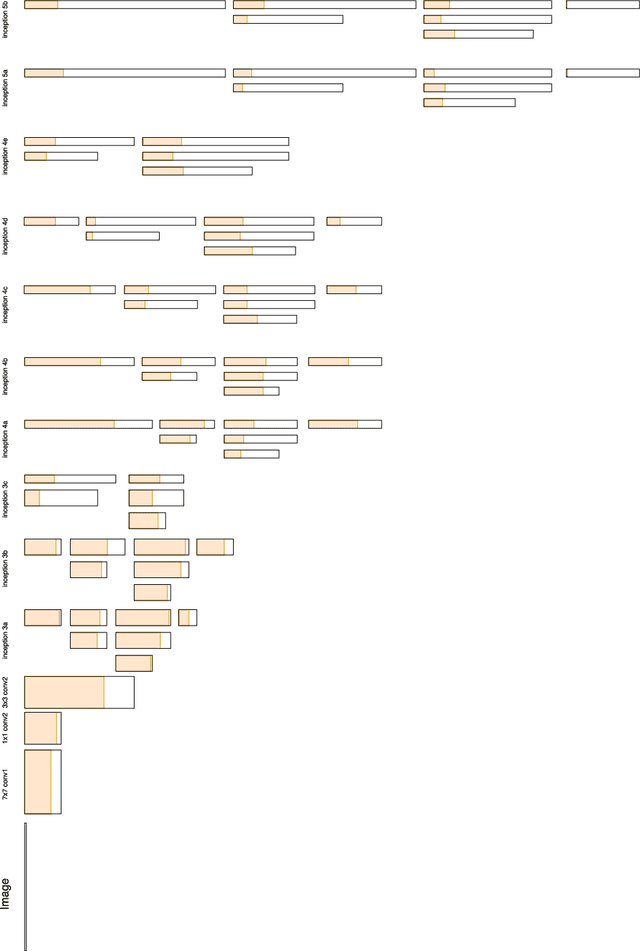
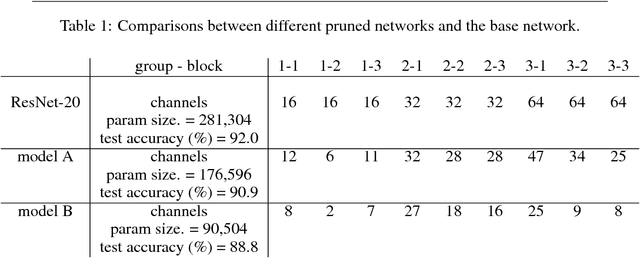
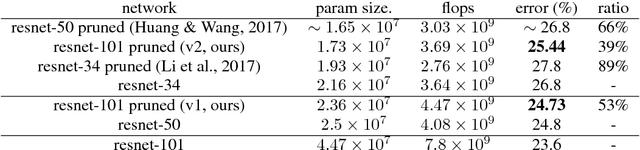
Model pruning has become a useful technique that improves the computational efficiency of deep learning, making it possible to deploy solutions in resource-limited scenarios. A widely-used practice in relevant work assumes that a smaller-norm parameter or feature plays a less informative role at the inference time. In this paper, we propose a channel pruning technique for accelerating the computations of deep convolutional neural networks (CNNs) that does not critically rely on this assumption. Instead, it focuses on direct simplification of the channel-to-channel computation graph of a CNN without the need of performing a computationally difficult and not-always-useful task of making high-dimensional tensors of CNN structured sparse. Our approach takes two stages: first to adopt an end-to- end stochastic training method that eventually forces the outputs of some channels to be constant, and then to prune those constant channels from the original neural network by adjusting the biases of their impacting layers such that the resulting compact model can be quickly fine-tuned. Our approach is mathematically appealing from an optimization perspective and easy to reproduce. We experimented our approach through several image learning benchmarks and demonstrate its interesting aspects and competitive performance.
Active Learning of Strict Partial Orders: A Case Study on Concept Prerequisite Relations
Jan 19, 2018
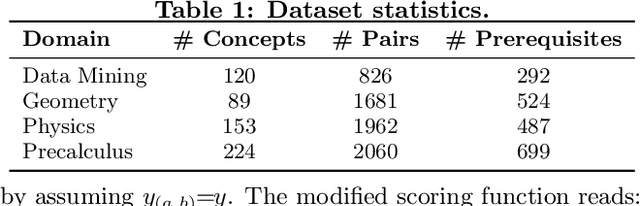
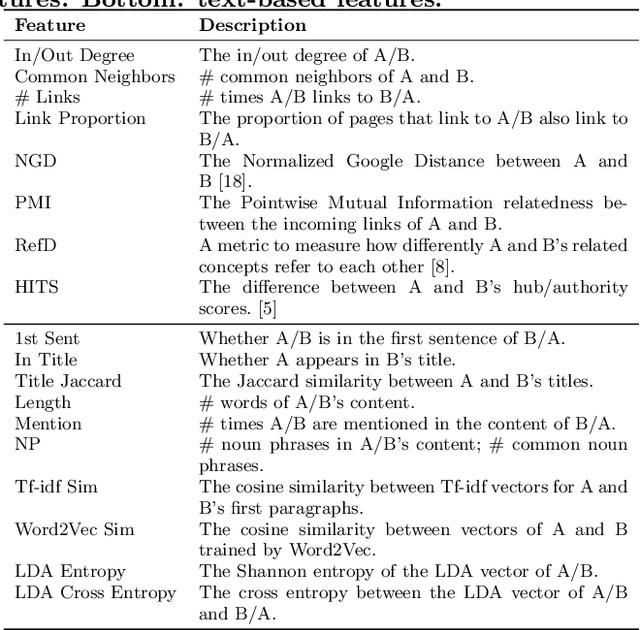
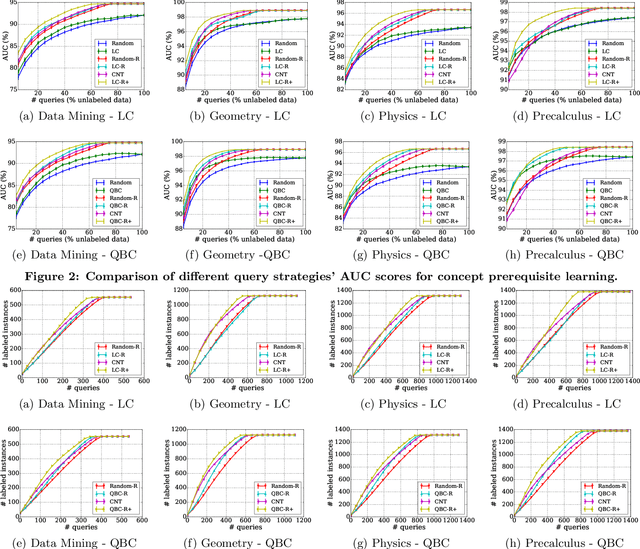
Strict partial order is a mathematical structure commonly seen in relational data. One obstacle to extracting such type of relations at scale is the lack of large-scale labels for building effective data-driven solutions. We develop an active learning framework for mining such relations subject to a strict order. Our approach incorporates relational reasoning not only in finding new unlabeled pairs whose labels can be deduced from an existing label set, but also in devising new query strategies that consider the relational structure of labels. Our experiments on concept prerequisite relations show our proposed framework can substantially improve the classification performance with the same query budget compared to other baseline approaches.
Aggregated Wasserstein Metric and State Registration for Hidden Markov Models
Nov 19, 2017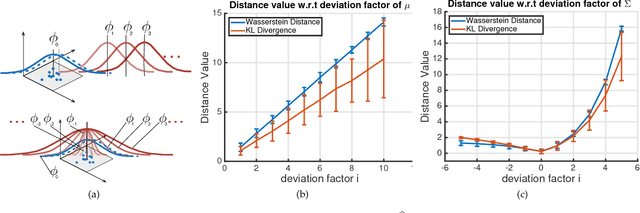

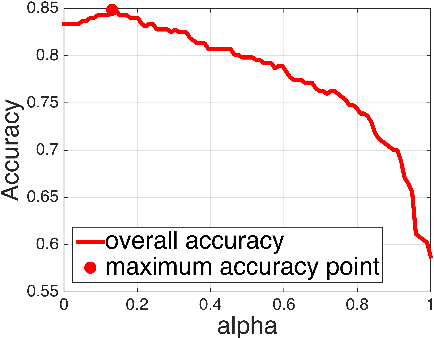

We propose a framework, named Aggregated Wasserstein, for computing a dissimilarity measure or distance between two Hidden Markov Models with state conditional distributions being Gaussian. For such HMMs, the marginal distribution at any time position follows a Gaussian mixture distribution, a fact exploited to softly match, aka register, the states in two HMMs. We refer to such HMMs as Gaussian mixture model-HMM (GMM-HMM). The registration of states is inspired by the intrinsic relationship of optimal transport and the Wasserstein metric between distributions. Specifically, the components of the marginal GMMs are matched by solving an optimal transport problem where the cost between components is the Wasserstein metric for Gaussian distributions. The solution of the optimization problem is a fast approximation to the Wasserstein metric between two GMMs. The new Aggregated Wasserstein distance is a semi-metric and can be computed without generating Monte Carlo samples. It is invariant to relabeling or permutation of states. The distance is defined meaningfully even for two HMMs that are estimated from data of different dimensionality, a situation that can arise due to missing variables. This distance quantifies the dissimilarity of GMM-HMMs by measuring both the difference between the two marginal GMMs and that between the two transition matrices. Our new distance is tested on tasks of retrieval, classification, and t-SNE visualization of time series. Experiments on both synthetic and real data have demonstrated its advantages in terms of accuracy as well as efficiency in comparison with existing distances based on the Kullback-Leibler divergence.
Fast Discrete Distribution Clustering Using Wasserstein Barycenter with Sparse Support
Jan 09, 2017
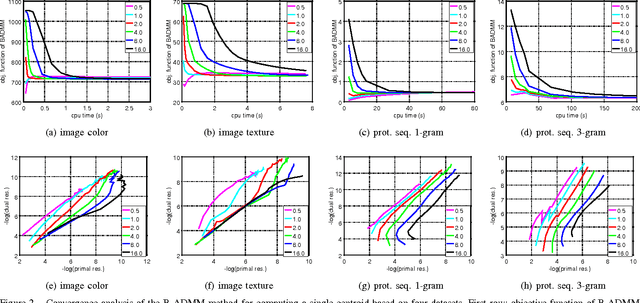

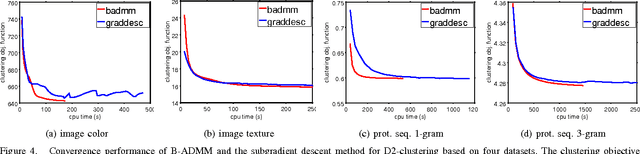
In a variety of research areas, the weighted bag of vectors and the histogram are widely used descriptors for complex objects. Both can be expressed as discrete distributions. D2-clustering pursues the minimum total within-cluster variation for a set of discrete distributions subject to the Kantorovich-Wasserstein metric. D2-clustering has a severe scalability issue, the bottleneck being the computation of a centroid distribution, called Wasserstein barycenter, that minimizes its sum of squared distances to the cluster members. In this paper, we develop a modified Bregman ADMM approach for computing the approximate discrete Wasserstein barycenter of large clusters. In the case when the support points of the barycenters are unknown and have low cardinality, our method achieves high accuracy empirically at a much reduced computational cost. The strengths and weaknesses of our method and its alternatives are examined through experiments, and we recommend scenarios for their respective usage. Moreover, we develop both serial and parallelized versions of the algorithm. By experimenting with large-scale data, we demonstrate the computational efficiency of the new methods and investigate their convergence properties and numerical stability. The clustering results obtained on several datasets in different domains are highly competitive in comparison with some widely used methods in the corresponding areas.