 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Smaller-Norm-Less-Informative Assumption in Channel Pruning of Convolution Layers
Paper and Code
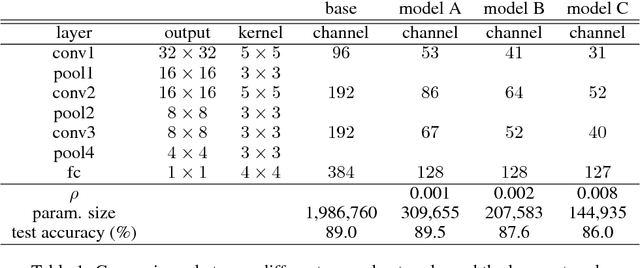
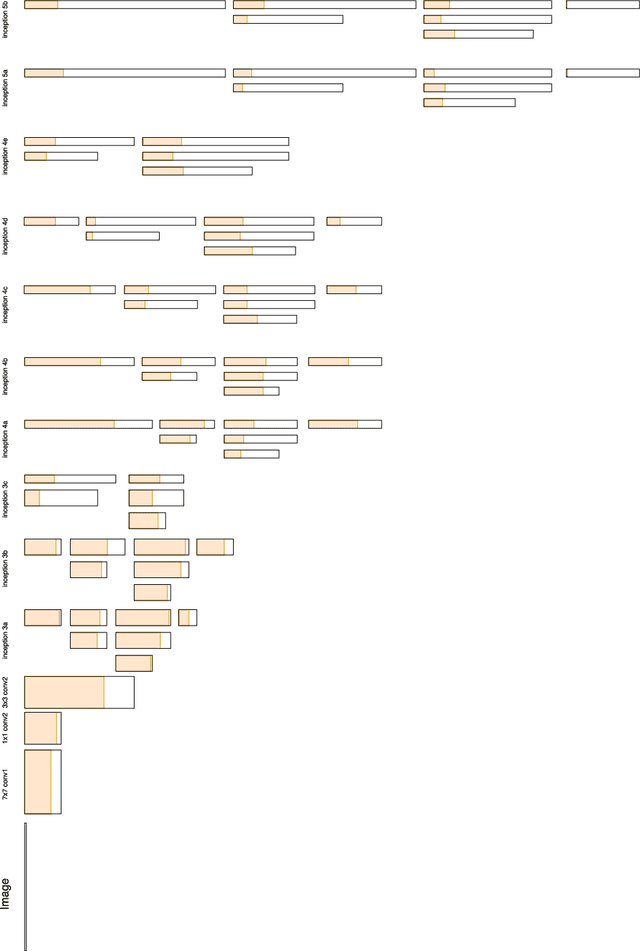
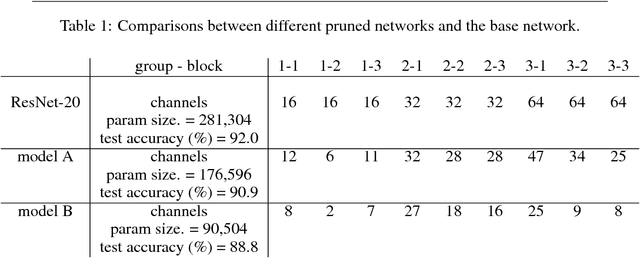
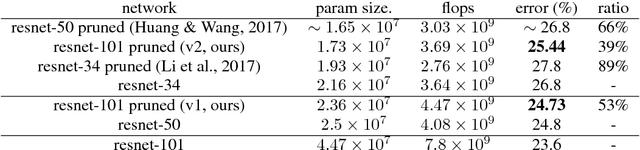
Model pruning has become a useful technique that improves the computational efficiency of deep learning, making it possible to deploy solutions in resource-limited scenarios. A widely-used practice in relevant work assumes that a smaller-norm parameter or feature plays a less informative role at the inference time. In this paper, we propose a channel pruning technique for accelerating the computations of deep convolutional neural networks (CNNs) that does not critically rely on this assumption. Instead, it focuses on direct simplification of the channel-to-channel computation graph of a CNN without the need of performing a computationally difficult and not-always-useful task of making high-dimensional tensors of CNN structured sparse. Our approach takes two stages: first to adopt an end-to- end stochastic training method that eventually forces the outputs of some channels to be constant, and then to prune those constant channels from the original neural network by adjusting the biases of their impacting layers such that the resulting compact model can be quickly fine-tuned. Our approach is mathematically appealing from an optimization perspective and easy to reproduce. We experimented our approach through several image learning benchmarks and demonstrate its interesting aspects and competitive performance.