 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCP-CLIP:A Coarse-to-Fine Framework for Open-Vocabulary Semantic Segmentation with Dual Interaction
Mar 14, 2026The recent years have witnessed the remarkable development for open-vocabulary semantic segmentation (OVSS) using visual-language foundation models, yet still suffer from following fundamental challenges: (1) insufficient cross-modal communications between textual and visual spaces, and (2) significant computational costs from the interactions with massive number of categories. To address these issues, this paper describes a novel coarse-to-fine framework, called DCP-CLIP, for OVSS. Unlike prior efforts that mainly relied on pre-established category content and the inherent spatial-class interaction capability of CLIP, we dynamic constructing category-relevant textual features and explicitly models dual interactions between spatial image features and textual class semantics. Specifically, we first leverage CLIP's open-vocabulary recognition capability to identify semantic categories relevant to the image context, upon which we dynamically generate corresponding textual features to serve as initial textual guidance. Subsequently, we conduct a coarse segmentation by cross-modally integrating semantic information from textual guidance into the visual representations and achieve refined segmentation by integrating spatially enriched features from the encoder to recover fine-grained details and enhance spatial resolution. In final, we leverage spatial information from the segmentation side to refine category predictions for each mask, facilitating more precise semantic labeling. Experiments on multiple OVSS benchmarks demonstrate that DCP-CLIP outperforms existing methods by delivering both higher accuracy and greater efficiency.
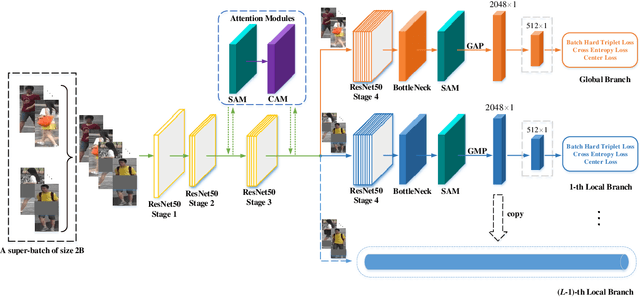
FPB: Feature Pyramid Branch for Person Re-Identification
Aug 04, 2021High performance person Re-Identification (Re-ID) requires the model to focus on both global silhouette and local details of pedestrian. To extract such more representative features, an effective way is to exploit deep models with multiple branches. However, most multi-branch based methods implemented by duplication of part backbone structure normally lead to severe increase of computational cost. In this paper, we propose a lightweight Feature Pyramid Branch (FPB) to extract features from different layers of networks and aggregate them in a bidirectional pyramid structure. Cooperated by attention modules and our proposed cross orthogonality regularization, FPB significantly prompts the performance of backbone network by only introducing less than 1.5M extra parameters. Extensive experimental results on standard benchmark datasets demonstrate that our proposed FPB based model outperforms state-of-the-art methods with obvious margin as well as much less model complexity. FPB borrows the idea of the Feature Pyramid Network (FPN) from prevailing object detection methods. To our best knowledge, it is the first successful application of similar structure in person Re-ID tasks, which empirically proves that pyramid network as affiliated branch could be a potential structure in related feature embedding models. The source code is publicly available at https://github.com/anocodetest1/FPB.git.
Branch-Cooperative OSNet for Person Re-Identification
Jun 12, 2020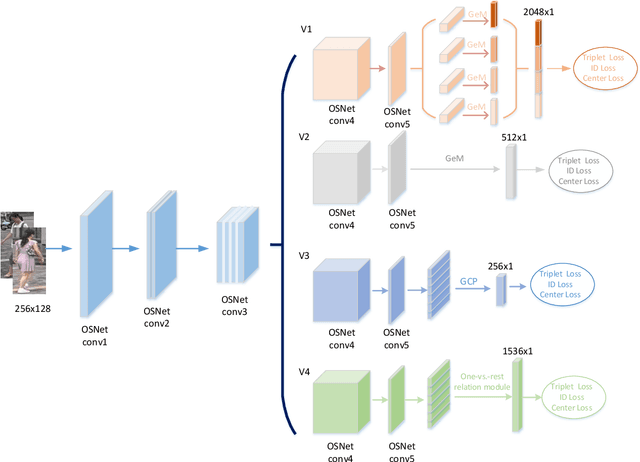
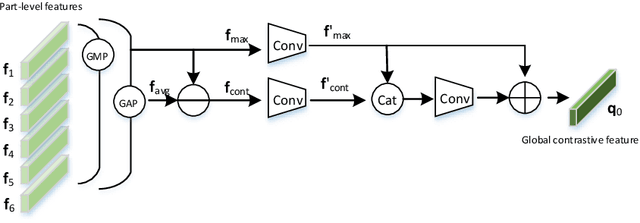
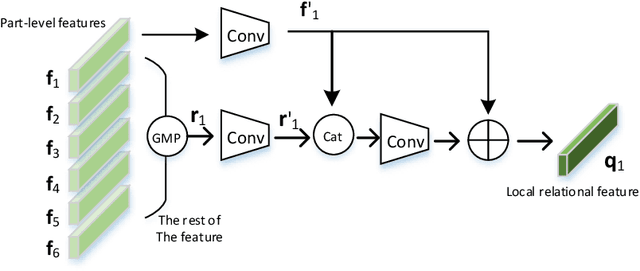
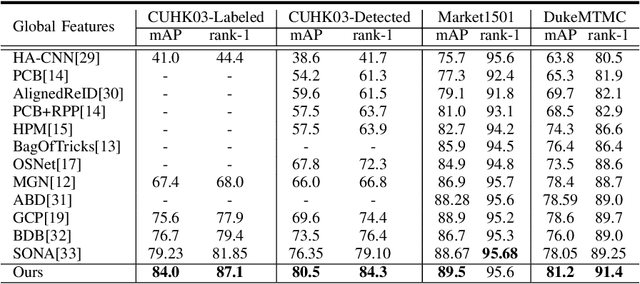
Multi-branch is extensively studied for learning rich feature representation for person re-identification (Re-ID). In this paper, we propose a branch-cooperative architecture over OSNet, termed BC-OSNet, for person Re-ID. By stacking four cooperative branches, namely, a global branch, a local branch, a relational branch and a contrastive branch, we obtain powerful feature representation for person Re-ID. Extensive experiments show that the proposed BC-OSNet achieves state-of-art performance on the three popular datasets, including Market-1501, DukeMTMC-reID and CUHK03. In particular, it achieves mAP of 84.0% and rank-1 accuracy of 87.1% on the CUHK03_labeled.
Diversity-Achieving Slow-DropBlock Network for Person Re-Identification
Feb 09, 2020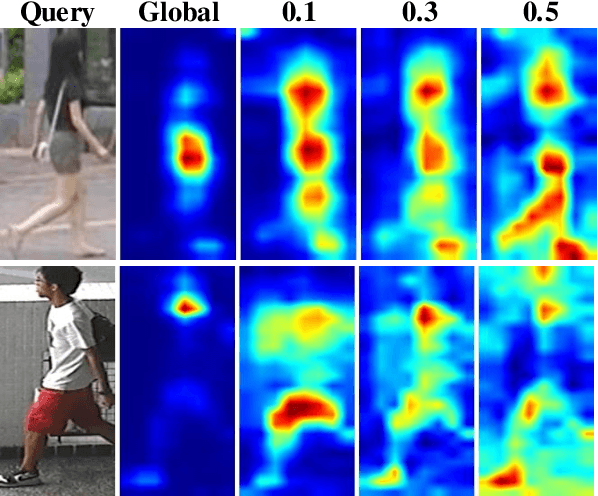

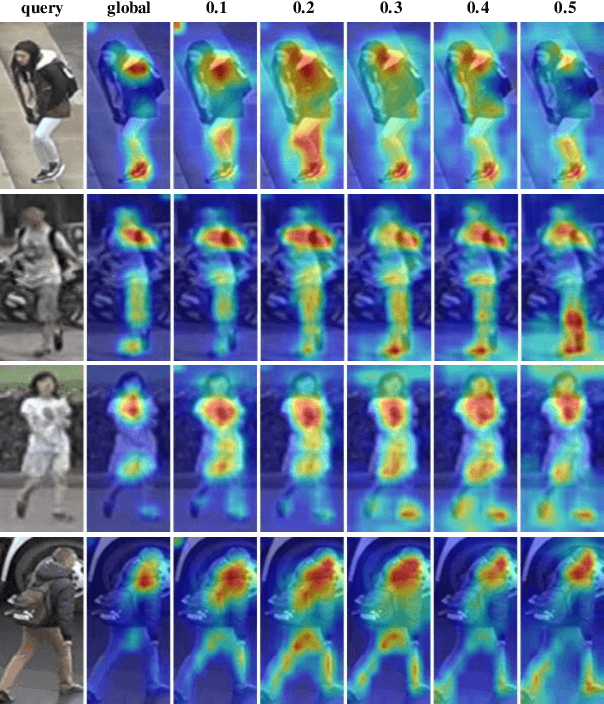
A big challenge of person re-identification (Re-ID) using a multi-branch network architecture is to learn diverse features from the ID-labeled dataset. The 2-branch Batch DropBlock (BDB) network was recently proposed for achieving diversity between the global branch and the feature-dropping branch. In this paper, we propose to move the dropping operation from the intermediate feature layer towards the input (image dropping). Since it may drop a large portion of input images, this makes the training hard to converge. Hence, we propose a novel double-batch-split co-training approach for remedying this problem. In particular, we show that the feature diversity can be well achieved with the use of multiple dropping branches by setting individual dropping ratio for each branch. Empirical evidence demonstrates that the proposed method performs superior to BDB on popular person Re-ID datasets, including Market-1501, DukeMTMC-reID and CUHK03 and the use of more dropping branches can further boost the performance.
Learning Diverse Features with Part-Level Resolution for Person Re-Identification
Jan 21, 2020



Learning diverse features is key to the success of person re-identification. Various part-based methods have been extensively proposed for learning local representations, which, however, are still inferior to the best-performing methods for person re-identification. This paper proposes to construct a strong lightweight network architecture, termed PLR-OSNet, based on the idea of Part-Level feature Resolution over the Omni-Scale Network (OSNet) for achieving feature diversity. The proposed PLR-OSNet has two branches, one branch for global feature representation and the other branch for local feature representation. The local branch employs a uniform partition strategy for part-level feature resolution but produces only a single identity-prediction loss, which is in sharp contrast to the existing part-based methods. Empirical evidence demonstrates that the proposed PLR-OSNet achieves state-of-the-art performance on popular person Re-ID datasets, including Market1501, DukeMTMC-reID and CUHK03, despite its small model size.
Investigating Capsule Networks with Dynamic Routing for Text Classification
Sep 03, 2018
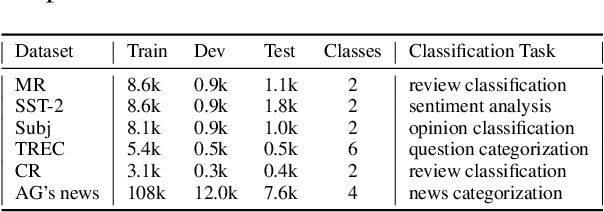
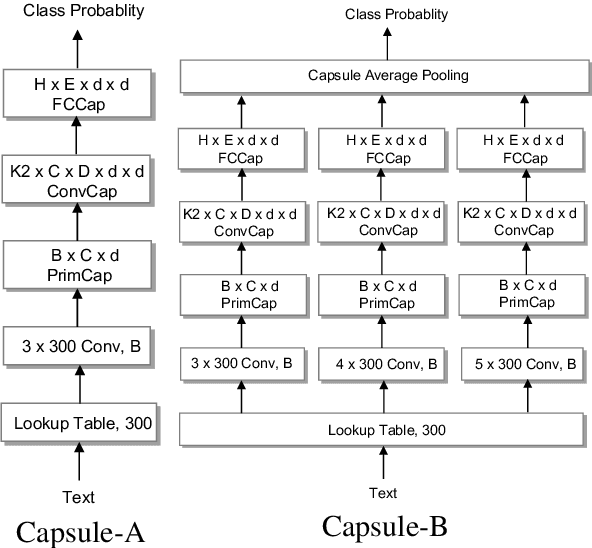
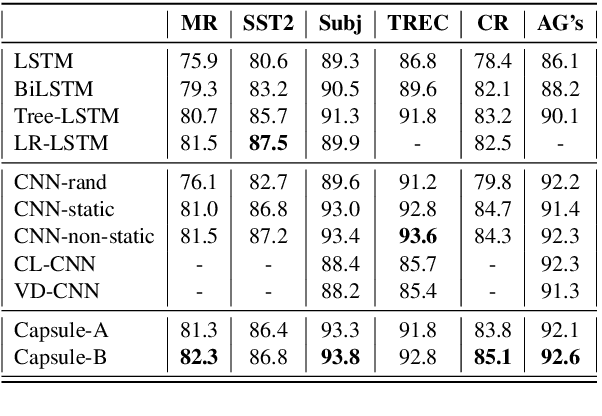
In this study, we explore capsule networks with dynamic routing for text classification. We propose three strategies to stabilize the dynamic routing process to alleviate the disturbance of some noise capsules which may contain "background" information or have not been successfully trained. A series of experiments are conducted with capsule networks on six text classification benchmarks. Capsule networks achieve state of the art on 4 out of 6 datasets, which shows the effectiveness of capsule networks for text classification. We additionally show that capsule networks exhibit significant improvement when transfer single-label to multi-label text classification over strong baseline methods. To the best of our knowledge, this is the first work that capsule networks have been empirically investigated for text modeling.
Fast Dynamic Routing Based on Weighted Kernel Density Estimation
Sep 01, 2018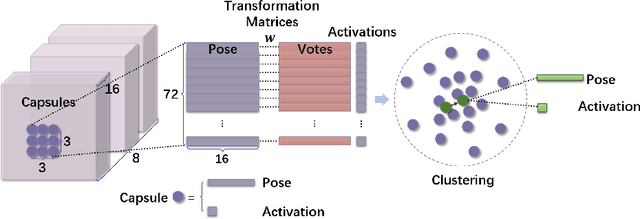


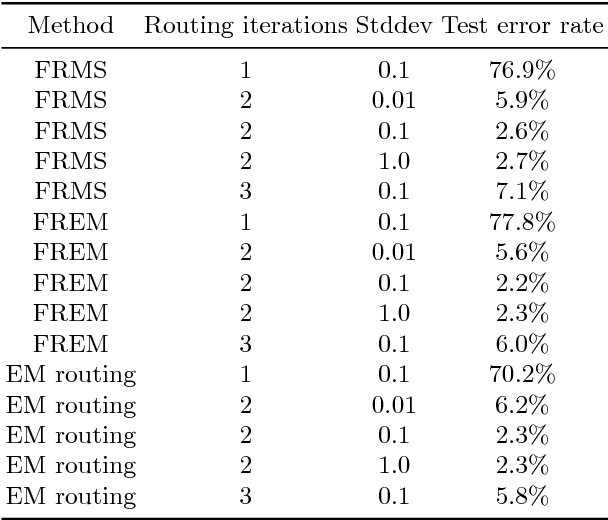
Capsules as well as dynamic routing between them are most recently proposed structures for deep neural networks. A capsule groups data into vectors or matrices as poses rather than conventional scalars to represent specific properties of target instance. Besides of pose, a capsule should be attached with a probability (often denoted as activation) for its presence. The dynamic routing helps capsules achieve more generalization capacity with many fewer model parameters. However, the bottleneck that prevents widespread applications of capsule is the expense of computation during routing. To address this problem, we generalize existing routing methods within the framework of weighted kernel density estimation, and propose two fast routing methods with different optimization strategies. Our methods prompt the time efficiency of routing by nearly 40\% with negligible performance degradation. By stacking a hybrid of convolutional layers and capsule layers, we construct a network architecture to handle inputs at a resolution of $64\times{64}$ pixels. The proposed models achieve a parallel performance with other leading methods in multiple benchmarks.
Tracking Deformable Parts via Dynamic Conditional Random Fields
Oct 30, 2013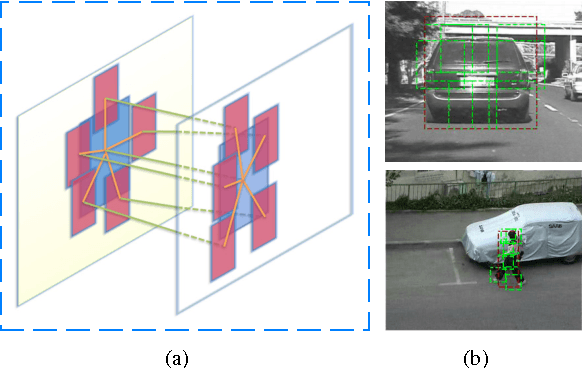

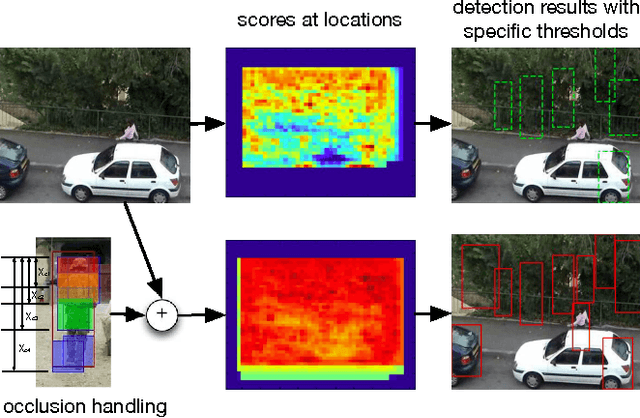
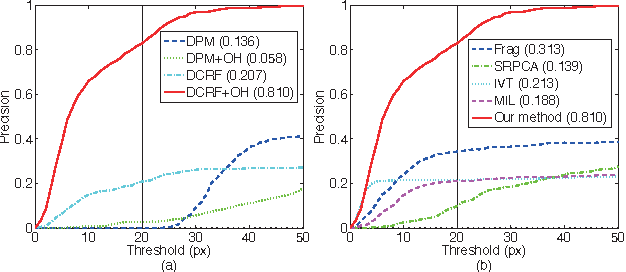
Despite the success of many advanced tracking methods in this area, tracking targets with drastic variation of appearance such as deformation, view change and partial occlusion in video sequences is still a challenge in practical applications. In this letter, we take these serious tracking problems into account simultaneously, proposing a dynamic graph based model to track object and its deformable parts at multiple resolutions. The method introduces well learned structural object detection models into object tracking applications as prior knowledge to deal with deformation and view change. Meanwhile, it explicitly formulates partial occlusion by integrating spatial potentials and temporal potentials with an unparameterized occlusion handling mechanism in the dynamic conditional random field framework. Empirical results demonstrate that the method outperforms state-of-the-art trackers on different challenging video sequences.