 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Evolving Reason-Reflect-Rectify for Reflective Visual Generation
May 19, 2026Text-to-Image (T2I) models and Unified Multimodal Models (UMMs) have achieved remarkable progress in visual generation. However, their reliance on a single-pass generation paradigm limits their ability to handle complex prompts requiring iterative refinement. To enable multi-round Reflective Visual Generation (RVG), we formalize the Reason-Reflect-Rectify (R^3) loop as a core framework and introduce R^3-Bench, a benchmark of over 600 expert-annotated instances that quantifies iterative reasoning and rectification capabilities. Evaluation on R^3-Bench reveals a critical gap: while state-of-the-art models can identify generation errors, they fail to generate actionable rectification instructions. To bridge this gap, we propose R^3-Refiner, a dual-stage framework leveraging Group Relative Policy Optimization (GRPO) and a Hierarchical Reward Mechanism (HRM) to better align rectification with reflective reasoning. Experiments show that R^3-Refiner achieves significant improvements on R^3-Bench (+12.0% in Reflective Verdict Score, +9.0% in Rectification Score), and can be seamlessly integrated with various MLLMs to enhance the generation quality of different T2I models on GenEval++ and T2I-CompBench. Code is available at https://github.com/xiaomoguhz/R3-Bench.
DeCLIP: Decoupled Learning for Open-Vocabulary Dense Perception
May 07, 2025Dense visual prediction tasks have been constrained by their reliance on predefined categories, limiting their applicability in real-world scenarios where visual concepts are unbounded. While Vision-Language Models (VLMs) like CLIP have shown promise in open-vocabulary tasks, their direct application to dense prediction often leads to suboptimal performance due to limitations in local feature representation. In this work, we present our observation that CLIP's image tokens struggle to effectively aggregate information from spatially or semantically related regions, resulting in features that lack local discriminability and spatial consistency. To address this issue, we propose DeCLIP, a novel framework that enhances CLIP by decoupling the self-attention module to obtain ``content'' and ``context'' features respectively. The ``content'' features are aligned with image crop representations to improve local discriminability, while ``context'' features learn to retain the spatial correlations under the guidance of vision foundation models, such as DINO. Extensive experiments demonstrate that DeCLIP significantly outperforms existing methods across multiple open-vocabulary dense prediction tasks, including object detection and semantic segmentation. Code is available at \textcolor{magenta}{https://github.com/xiaomoguhz/DeCLIP}.
Multi-path Exploration and Feedback Adjustment for Text-to-Image Person Retrieval
Oct 26, 2024



Text-based person retrieval aims to identify the specific persons using textual descriptions as queries. Existing ad vanced methods typically depend on vision-language pre trained (VLP) models to facilitate effective cross-modal alignment. However, the inherent constraints of VLP mod-els, which include the global alignment biases and insuffi-cient self-feedback regulation, impede optimal retrieval per formance. In this paper, we propose MeFa, a Multi-Pathway Exploration, Feedback, and Adjustment framework, which deeply explores intrinsic feedback of intra and inter-modal to make targeted adjustment, thereby achieving more precise person-text associations. Specifically, we first design an intra modal reasoning pathway that generates hard negative sam ples for cross-modal data, leveraging feedback from these samples to refine intra-modal reasoning, thereby enhancing sensitivity to subtle discrepancies. Subsequently, we intro duce a cross-modal refinement pathway that utilizes both global information and intermodal feedback to refine local in formation, thus enhancing its global semantic representation. Finally, the discriminative clue correction pathway incorpo rates fine-grained features of secondary similarity as discrim inative clues to further mitigate retrieval failures caused by disparities in these features. Experimental results on three public benchmarks demonstrate that MeFa achieves superior person retrieval performance without necessitating additional data or complex structures.
OV-DQUO: Open-Vocabulary DETR with Denoising Text Query Training and Open-World Unknown Objects Supervision
May 28, 2024



Open-Vocabulary Detection (OVD) aims to detect objects from novel categories beyond the base categories on which the detector is trained. However, existing open-vocabulary detectors trained on known category data tend to assign higher confidence to trained categories and confuse novel categories with background. To resolve this, we propose OV-DQUO, an \textbf{O}pen-\textbf{V}ocabulary DETR with \textbf{D}enoising text \textbf{Q}uery training and open-world \textbf{U}nknown \textbf{O}bjects supervision. Specifically, we introduce a wildcard matching method that enables the detector to learn from pairs of unknown objects recognized by the open-world detector and text embeddings with general semantics, mitigating the confidence bias between base and novel categories. Additionally, we propose a denoising text query training strategy that synthesizes additional noisy query-box pairs from open-world unknown objects to trains the detector through contrastive learning, enhancing its ability to distinguish novel objects from the background. We conducted extensive experiments on the challenging OV-COCO and OV-LVIS benchmarks, achieving new state-of-the-art results of 45.6 AP50 and 39.3 mAP on novel categories respectively, without the need for additional training data. Models and code are released at https://github.com/xiaomoguhz/OV-DQUO
ParaFormer: Parallel Attention Transformer for Efficient Feature Matching
Mar 10, 2023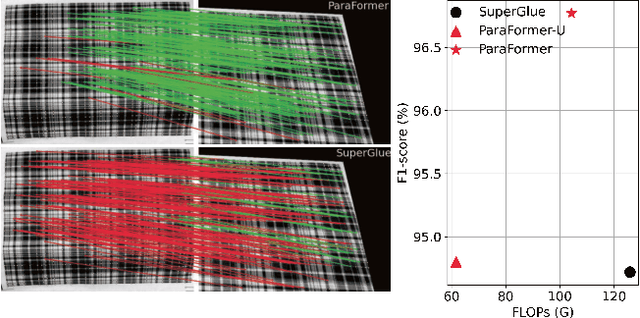
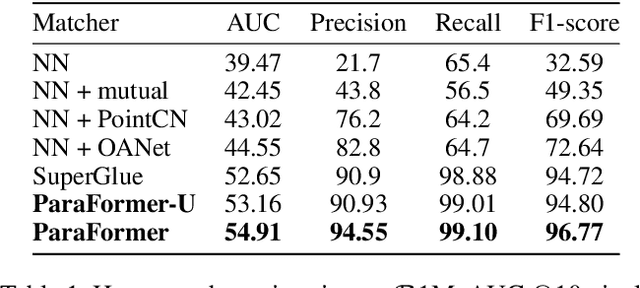
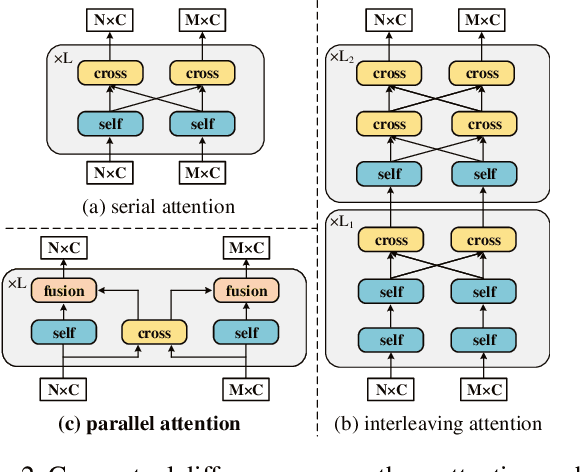
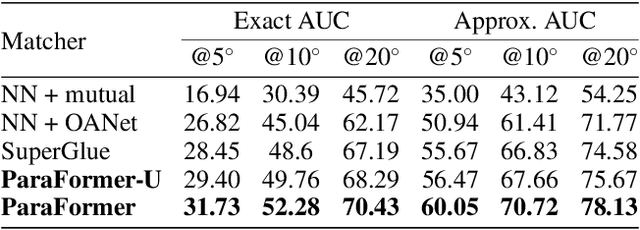
Heavy computation is a bottleneck limiting deep-learningbased feature matching algorithms to be applied in many realtime applications. However, existing lightweight networks optimized for Euclidean data cannot address classical feature matching tasks, since sparse keypoint based descriptors are expected to be matched. This paper tackles this problem and proposes two concepts: 1) a novel parallel attention model entitled ParaFormer and 2) a graph based U-Net architecture with attentional pooling. First, ParaFormer fuses features and keypoint positions through the concept of amplitude and phase, and integrates self- and cross-attention in a parallel manner which achieves a win-win performance in terms of accuracy and efficiency. Second, with U-Net architecture and proposed attentional pooling, the ParaFormer-U variant significantly reduces computational complexity, and minimize performance loss caused by downsampling. Sufficient experiments on various applications, including homography estimation, pose estimation, and image matching, demonstrate that ParaFormer achieves state-of-the-art performance while maintaining high efficiency. The efficient ParaFormer-U variant achieves comparable performance with less than 50% FLOPs of the existing attention-based models.
DPNet: Dual-Path Network for Real-time Object Detection with Lightweight Attention
Sep 28, 2022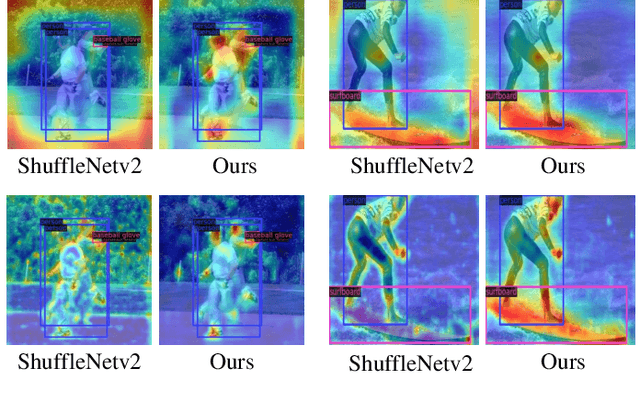
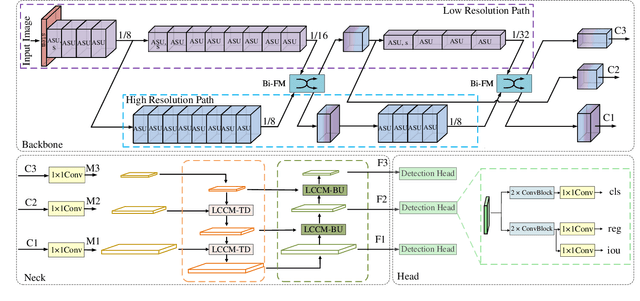
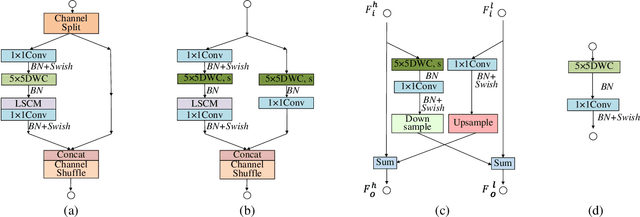
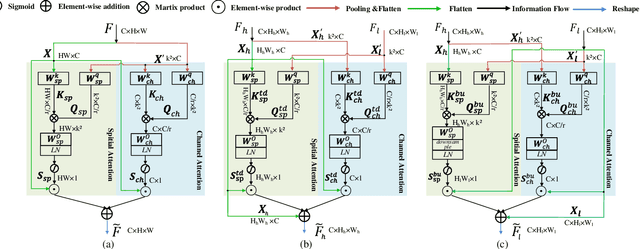
The recent advances of compressing high-accuracy convolution neural networks (CNNs) have witnessed remarkable progress for real-time object detection. To accelerate detection speed, lightweight detectors always have few convolution layers using single-path backbone. Single-path architecture, however, involves continuous pooling and downsampling operations, always resulting in coarse and inaccurate feature maps that are disadvantageous to locate objects. On the other hand, due to limited network capacity, recent lightweight networks are often weak in representing large scale visual data. To address these problems, this paper presents a dual-path network, named DPNet, with a lightweight attention scheme for real-time object detection. The dual-path architecture enables us to parallelly extract high-level semantic features and low-level object details. Although DPNet has nearly duplicated shape with respect to single-path detectors, the computational costs and model size are not significantly increased. To enhance representation capability, a lightweight self-correlation module (LSCM) is designed to capture global interactions, with only few computational overheads and network parameters. In neck, LSCM is extended into a lightweight crosscorrelation module (LCCM), capturing mutual dependencies among neighboring scale features. We have conducted exhaustive experiments on MS COCO and Pascal VOC 2007 datasets. The experimental results demonstrate that DPNet achieves state-of the-art trade-off between detection accuracy and implementation efficiency. Specifically, DPNet achieves 30.5% AP on MS COCO test-dev and 81.5% mAP on Pascal VOC 2007 test set, together mwith nearly 2.5M model size, 1.04 GFLOPs, and 164 FPS and 196 FPS for 320 x 320 input images of two datasets.
FPB: Feature Pyramid Branch for Person Re-Identification
Aug 04, 2021High performance person Re-Identification (Re-ID) requires the model to focus on both global silhouette and local details of pedestrian. To extract such more representative features, an effective way is to exploit deep models with multiple branches. However, most multi-branch based methods implemented by duplication of part backbone structure normally lead to severe increase of computational cost. In this paper, we propose a lightweight Feature Pyramid Branch (FPB) to extract features from different layers of networks and aggregate them in a bidirectional pyramid structure. Cooperated by attention modules and our proposed cross orthogonality regularization, FPB significantly prompts the performance of backbone network by only introducing less than 1.5M extra parameters. Extensive experimental results on standard benchmark datasets demonstrate that our proposed FPB based model outperforms state-of-the-art methods with obvious margin as well as much less model complexity. FPB borrows the idea of the Feature Pyramid Network (FPN) from prevailing object detection methods. To our best knowledge, it is the first successful application of similar structure in person Re-ID tasks, which empirically proves that pyramid network as affiliated branch could be a potential structure in related feature embedding models. The source code is publicly available at https://github.com/anocodetest1/FPB.git.
TEA: Temporal Excitation and Aggregation for Action Recognition
Apr 03, 2020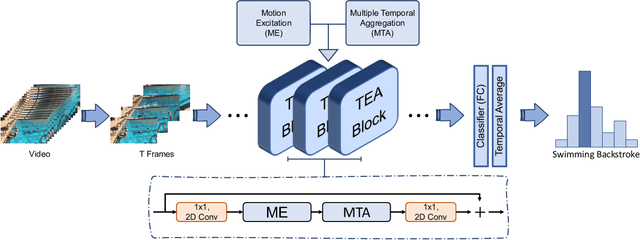
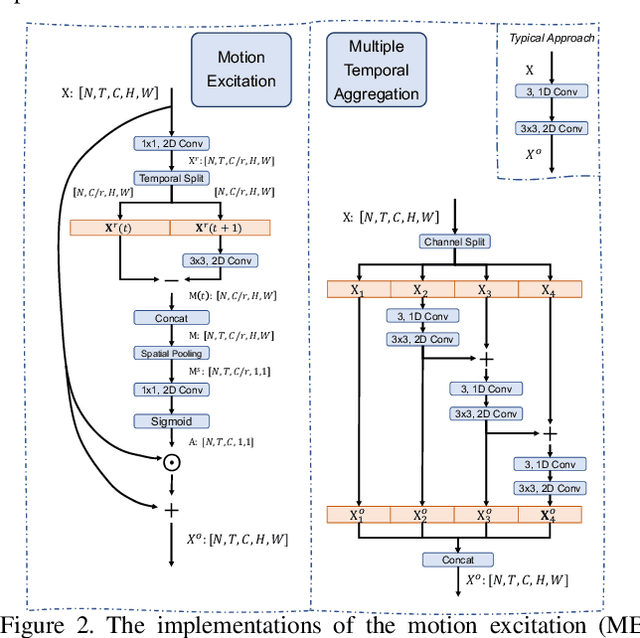
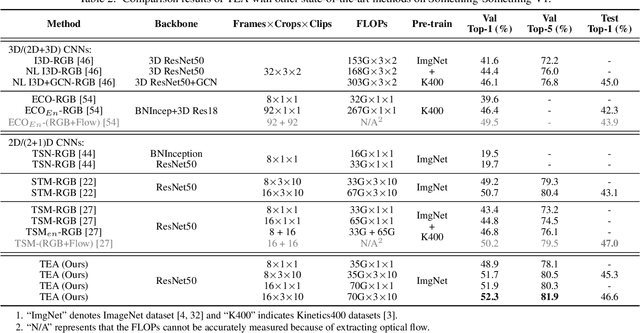
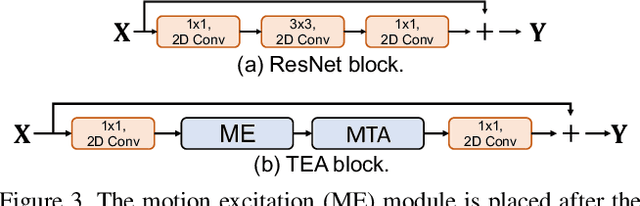
Temporal modeling is key for action recognition in videos. It normally considers both short-range motions and long-range aggregations. In this paper, we propose a Temporal Excitation and Aggregation (TEA) block, including a motion excitation (ME) module and a multiple temporal aggregation (MTA) module, specifically designed to capture both short- and long-range temporal evolution. In particular, for short-range motion modeling, the ME module calculates the feature-level temporal differences from spatiotemporal features. It then utilizes the differences to excite the motion-sensitive channels of the features. The long-range temporal aggregations in previous works are typically achieved by stacking a large number of local temporal convolutions. Each convolution processes a local temporal window at a time. In contrast, the MTA module proposes to deform the local convolution to a group of sub-convolutions, forming a hierarchical residual architecture. Without introducing additional parameters, the features will be processed with a series of sub-convolutions, and each frame could complete multiple temporal aggregations with neighborhoods. The final equivalent receptive field of temporal dimension is accordingly enlarged, which is capable of modeling the long-range temporal relationship over distant frames. The two components of the TEA block are complementary in temporal modeling. Finally, our approach achieves impressive results at low FLOPs on several action recognition benchmarks, such as Kinetics, Something-Something, HMDB51, and UCF101, which confirms its effectiveness and efficiency.
BiCANet: Bi-directional Contextual Aggregating Network for Image Semantic Segmentation
Mar 21, 2020
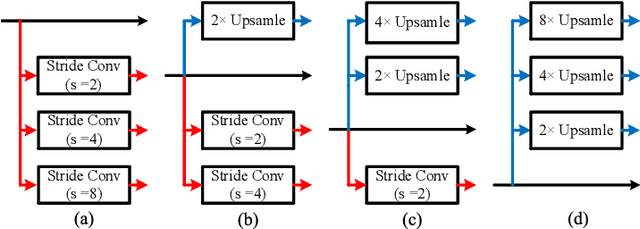
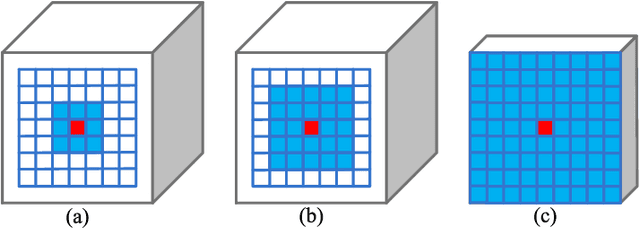

Exploring contextual information in convolution neural networks (CNNs) has gained substantial attention in recent years for semantic segmentation. This paper introduces a Bi-directional Contextual Aggregating Network, called BiCANet, for semantic segmentation. Unlike previous approaches that encode context in feature space, BiCANet aggregates contextual cues from a categorical perspective, which is mainly consist of three parts: contextual condensed projection block (CCPB), bi-directional context interaction block (BCIB), and muti-scale contextual fusion block (MCFB). More specifically, CCPB learns a category-based mapping through a split-transform-merge architecture, which condenses contextual cues with different receptive fields from intermediate layer. BCIB, on the other hand, employs dense skipped-connections to enhance the class-level context exchanging. Finally, MCFB integrates multi-scale contextual cues by investigating short- and long-ranged spatial dependencies. To evaluate BiCANet, we have conducted extensive experiments on three semantic segmentation datasets: PASCAL VOC 2012, Cityscapes, and ADE20K. The experimental results demonstrate that BiCANet outperforms recent state-of-the-art networks without any postprocess techniques. Particularly, BiCANet achieves the mIoU score of 86.7%, 82.4% and 38.66% on PASCAL VOC 2012, Cityscapes and ADE20K testset, respectively.
FDDWNet: A Lightweight Convolutional Neural Network for Real-time Sementic Segmentation
Nov 08, 2019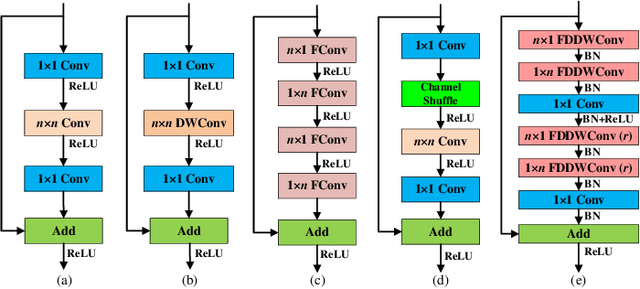
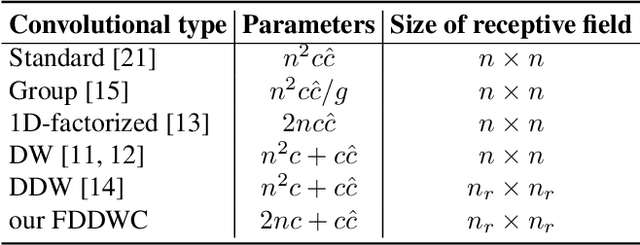
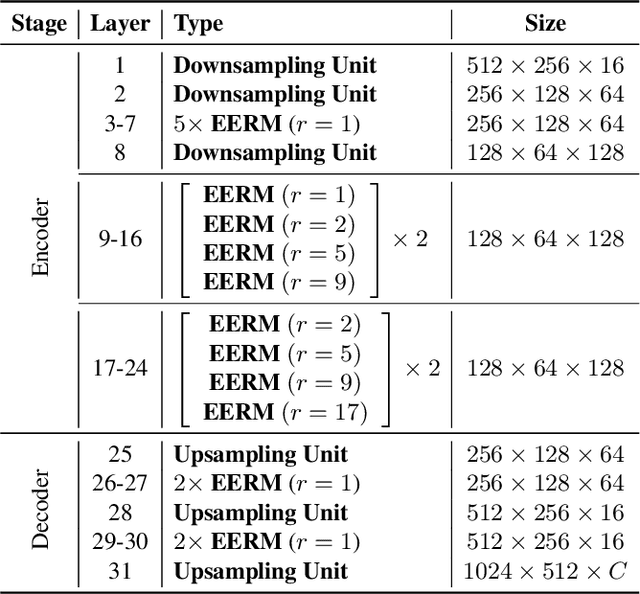

This paper introduces a lightweight convolutional neural network, called FDDWNet, for real-time accurate semantic segmentation. In contrast to recent advances of lightweight networks that prefer to utilize shallow structure, FDDWNet makes an effort to design more deeper network architecture, while maintains faster inference speed and higher segmentation accuracy. Our network uses factorized dilated depth-wise separable convolutions (FDDWC) to learn feature representations from different scale receptive fields with fewer model parameters. Additionally, FDDWNet has multiple branches of skipped connections to gather context cues from intermediate convolution layers. The experiments show that FDDWNet only has 0.8M model size, while achieves 60 FPS running speed on a single RTX 2080Ti GPU with a 1024x512 input image. The comprehensive experiments demonstrate that our model achieves state-of-the-art results in terms of available speed and accuracy trade-off on CityScapes and CamVid datasets.