 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiCANet: Bi-directional Contextual Aggregating Network for Image Semantic Segmentation
Mar 21, 2020
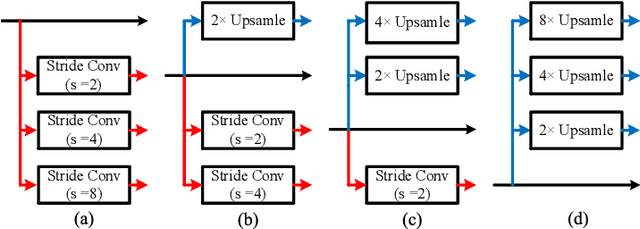
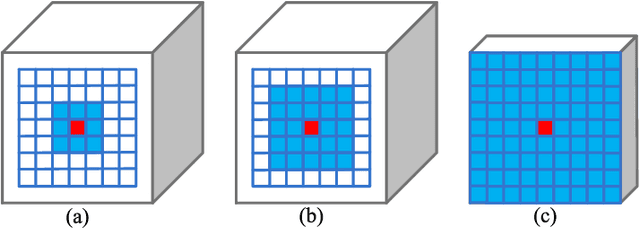

Exploring contextual information in convolution neural networks (CNNs) has gained substantial attention in recent years for semantic segmentation. This paper introduces a Bi-directional Contextual Aggregating Network, called BiCANet, for semantic segmentation. Unlike previous approaches that encode context in feature space, BiCANet aggregates contextual cues from a categorical perspective, which is mainly consist of three parts: contextual condensed projection block (CCPB), bi-directional context interaction block (BCIB), and muti-scale contextual fusion block (MCFB). More specifically, CCPB learns a category-based mapping through a split-transform-merge architecture, which condenses contextual cues with different receptive fields from intermediate layer. BCIB, on the other hand, employs dense skipped-connections to enhance the class-level context exchanging. Finally, MCFB integrates multi-scale contextual cues by investigating short- and long-ranged spatial dependencies. To evaluate BiCANet, we have conducted extensive experiments on three semantic segmentation datasets: PASCAL VOC 2012, Cityscapes, and ADE20K. The experimental results demonstrate that BiCANet outperforms recent state-of-the-art networks without any postprocess techniques. Particularly, BiCANet achieves the mIoU score of 86.7%, 82.4% and 38.66% on PASCAL VOC 2012, Cityscapes and ADE20K testset, respectively.
RSnet: An improvement for Darknet
Jan 16, 2020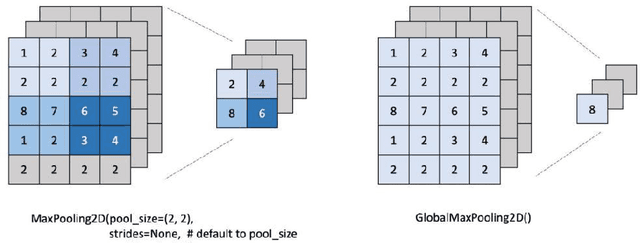

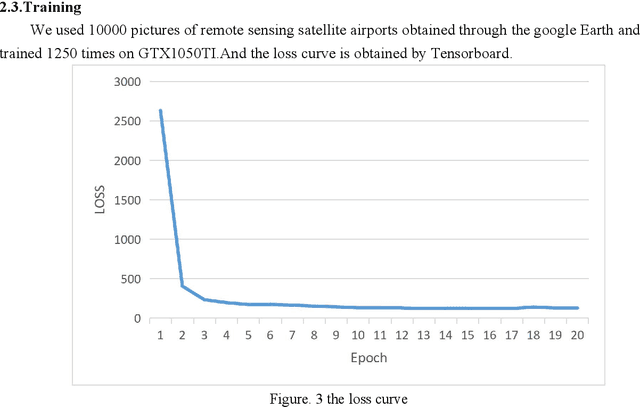
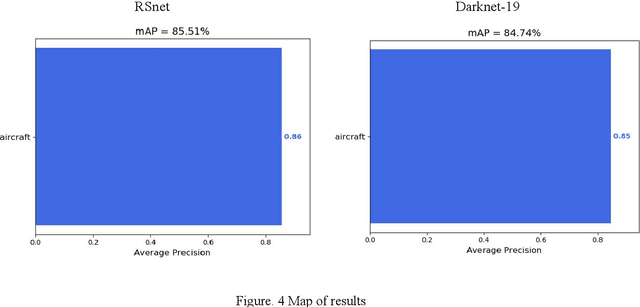
Recently, when we used this method to identify aircraft targets in remote sensing images, we found that there are some defects in our own YOLOv2 and Darknet-19 network. Characteristic in the images we identified are not very clear, thats why we couldn't get some much more good results. Then we replaced the maxpooling in the yolov3 network as the global maxpooling. Under the same test conditions, we got a higher. It achieves 76.9 AP50 in 100 ms on a GTX1050TI, compared to 80.5 AP50 in 627 ms by our net. Map.86% of Map was obtained by the improved network, higher than the former.
FDDWNet: A Lightweight Convolutional Neural Network for Real-time Sementic Segmentation
Nov 08, 2019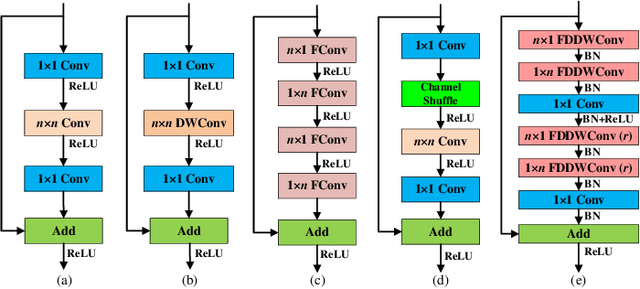
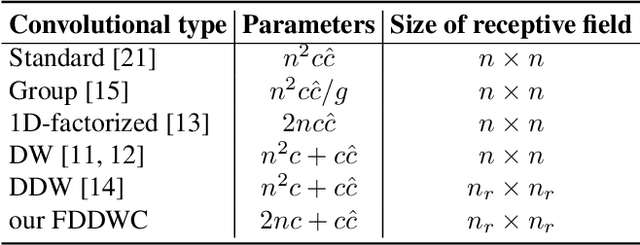
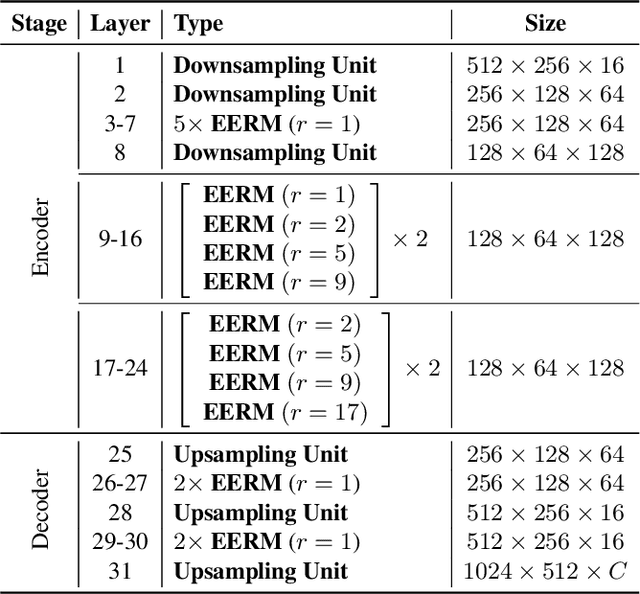

This paper introduces a lightweight convolutional neural network, called FDDWNet, for real-time accurate semantic segmentation. In contrast to recent advances of lightweight networks that prefer to utilize shallow structure, FDDWNet makes an effort to design more deeper network architecture, while maintains faster inference speed and higher segmentation accuracy. Our network uses factorized dilated depth-wise separable convolutions (FDDWC) to learn feature representations from different scale receptive fields with fewer model parameters. Additionally, FDDWNet has multiple branches of skipped connections to gather context cues from intermediate convolution layers. The experiments show that FDDWNet only has 0.8M model size, while achieves 60 FPS running speed on a single RTX 2080Ti GPU with a 1024x512 input image. The comprehensive experiments demonstrate that our model achieves state-of-the-art results in terms of available speed and accuracy trade-off on CityScapes and CamVid datasets.