 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Adaptive Anti-Jamming Channel Access via Deep Q Learning and Coarse-Grained Spectrum Prediction
Feb 07, 2025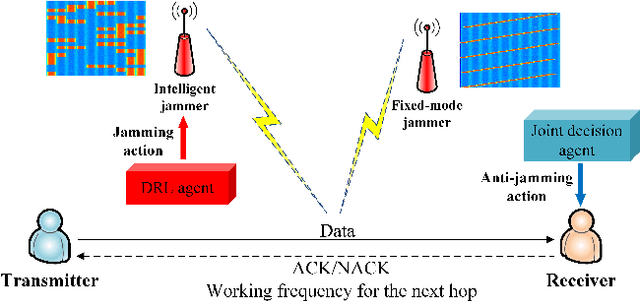
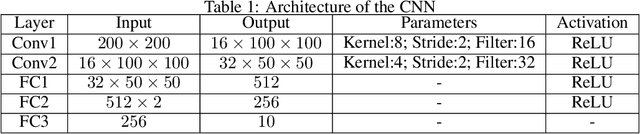
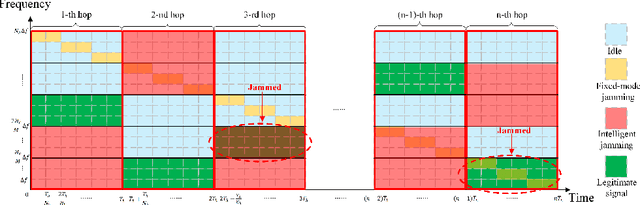
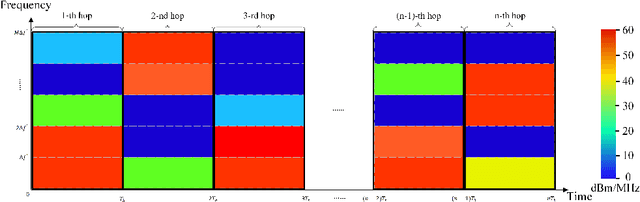
This paper investigates the anti-jamming channel access problem in complex and unknown jamming environments, where the jammer could dynamically adjust its strategies to target different channels. Traditional channel hopping anti-jamming approaches using fixed patterns are ineffective against such dynamic jamming attacks. Although the emerging deep reinforcement learning (DRL) based dynamic channel access approach could achieve the Nash equilibrium under fast-changing jamming attacks, it requires extensive training episodes. To address this issue, we propose a fast adaptive anti-jamming channel access approach guided by the intuition of ``learning faster than the jammer", where a synchronously updated coarse-grained spectrum prediction serves as an auxiliary task for the deep Q learning (DQN) based anti-jamming model. This helps the model identify a superior Q-function compared to standard DRL while significantly reducing the number of training episodes. Numerical results indicate that the proposed approach significantly accelerates the rate of convergence in model training, reducing the required training episodes by up to 70% compared to standard DRL. Additionally, it also achieves a 10% improvement in throughput over NE strategies, owing to the effective use of coarse-grained spectrum prediction.
DPNet: Dual-Path Network for Real-time Object Detection with Lightweight Attention
Sep 28, 2022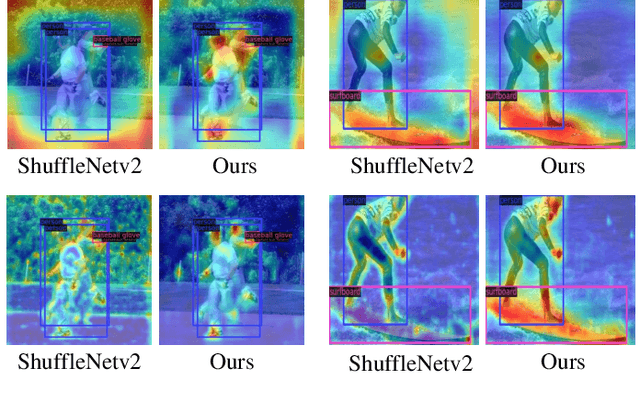
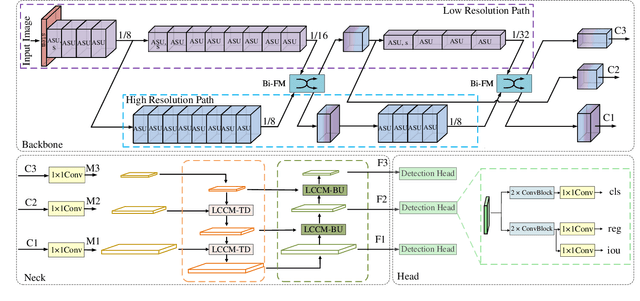
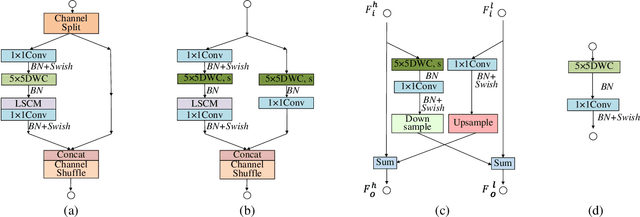
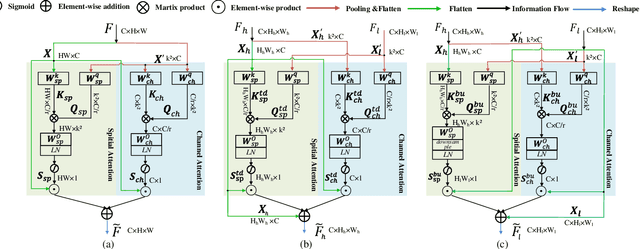
The recent advances of compressing high-accuracy convolution neural networks (CNNs) have witnessed remarkable progress for real-time object detection. To accelerate detection speed, lightweight detectors always have few convolution layers using single-path backbone. Single-path architecture, however, involves continuous pooling and downsampling operations, always resulting in coarse and inaccurate feature maps that are disadvantageous to locate objects. On the other hand, due to limited network capacity, recent lightweight networks are often weak in representing large scale visual data. To address these problems, this paper presents a dual-path network, named DPNet, with a lightweight attention scheme for real-time object detection. The dual-path architecture enables us to parallelly extract high-level semantic features and low-level object details. Although DPNet has nearly duplicated shape with respect to single-path detectors, the computational costs and model size are not significantly increased. To enhance representation capability, a lightweight self-correlation module (LSCM) is designed to capture global interactions, with only few computational overheads and network parameters. In neck, LSCM is extended into a lightweight crosscorrelation module (LCCM), capturing mutual dependencies among neighboring scale features. We have conducted exhaustive experiments on MS COCO and Pascal VOC 2007 datasets. The experimental results demonstrate that DPNet achieves state-of the-art trade-off between detection accuracy and implementation efficiency. Specifically, DPNet achieves 30.5% AP on MS COCO test-dev and 81.5% mAP on Pascal VOC 2007 test set, together mwith nearly 2.5M model size, 1.04 GFLOPs, and 164 FPS and 196 FPS for 320 x 320 input images of two datasets.
DRBANET: A Lightweight Dual-Resolution Network for Semantic Segmentation with Boundary Auxiliary
Oct 31, 2021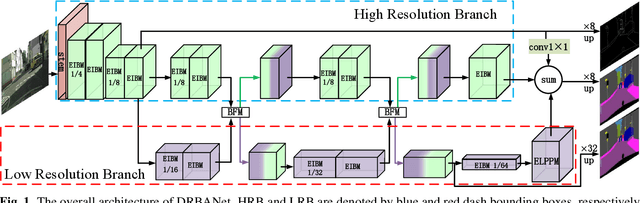
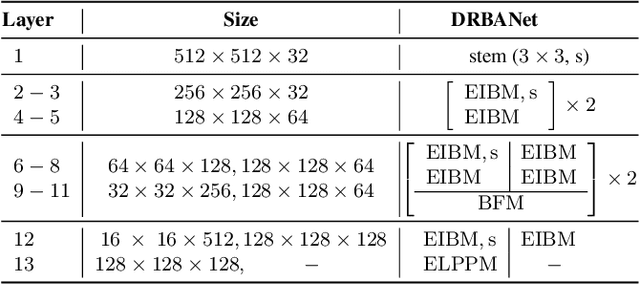
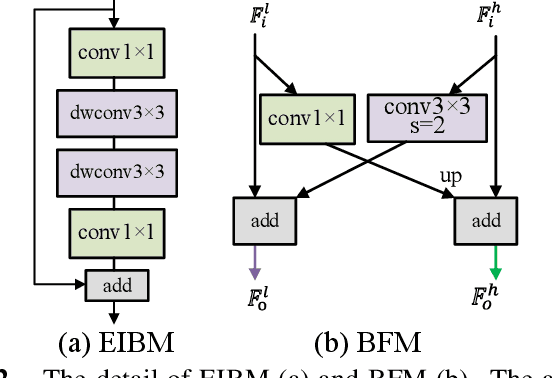
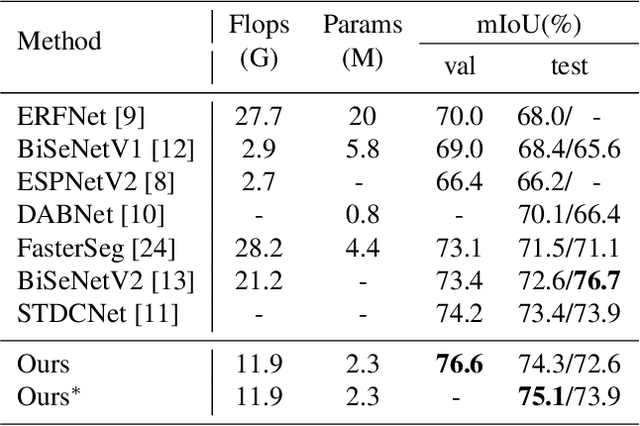
Due to the powerful ability to encode image details and semantics, many lightweight dual-resolution networks have been proposed in recent years. However, most of them ignore the benefit of boundary information. This paper introduces a lightweight dual-resolution network, called DRBANet, aiming to refine semantic segmentation results with the aid of boundary information. DRBANet adopts dual parallel architecture, including: high resolution branch (HRB) and low resolution branch (LRB). Specifically, HRB mainly consists of a set of Efficient Inverted Bottleneck Modules (EIBMs), which learn feature representations with larger receptive fields. LRB is composed of a series of EIBMs and an Extremely Lightweight Pyramid Pooling Module (ELPPM), where ELPPM is utilized to capture multi-scale context through hierarchical residual connections. Finally, a boundary supervision head is designed to capture object boundaries in HRB. Extensive experiments on Cityscapes and CamVid datasets demonstrate that our method achieves promising trade-off between segmentation accuracy and running efficiency.
DPNET: Dual-Path Network for Efficient Object Detectioj with Lightweight Self-Attention
Oct 31, 2021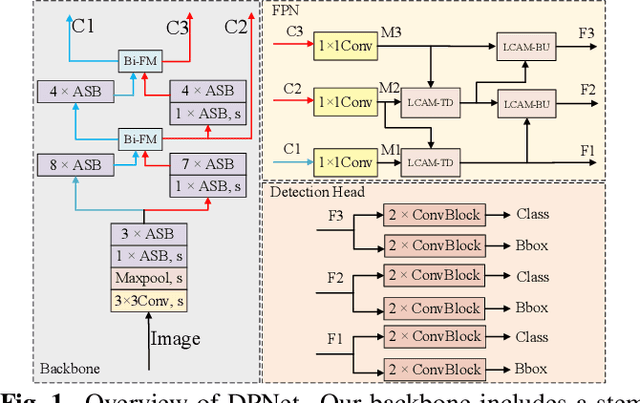
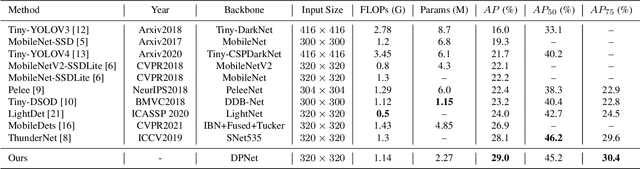
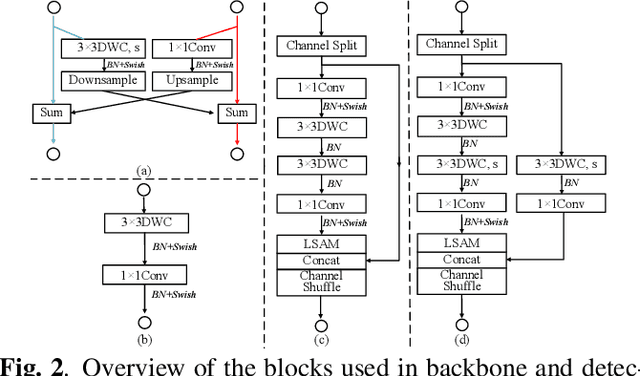
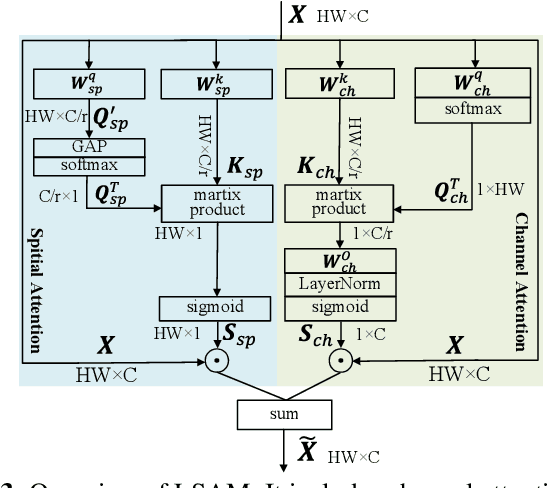
Object detection often costs a considerable amount of computation to get satisfied performance, which is unfriendly to be deployed in edge devices. To address the trade-off between computational cost and detection accuracy, this paper presents a dual path network, named DPNet, for efficient object detection with lightweight self-attention. In backbone, a single input/output lightweight self-attention module (LSAM) is designed to encode global interactions between different positions. LSAM is also extended into a multiple-inputs version in feature pyramid network (FPN), which is employed to capture cross-resolution dependencies in two paths. Extensive experiments on the COCO dataset demonstrate that our method achieves state-of-the-art detection results. More specifically, DPNet obtains 29.0% AP on COCO test-dev, with only 1.14 GFLOPs and 2.27M model size for a 320x320 image.
Universal Multi-Source Domain Adaptation
Nov 05, 2020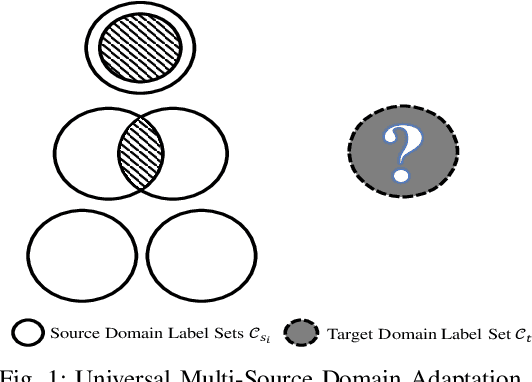
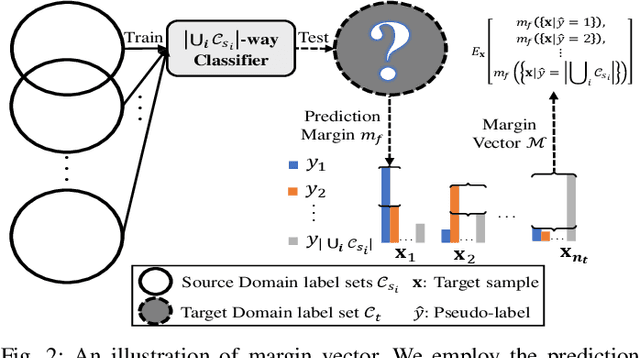
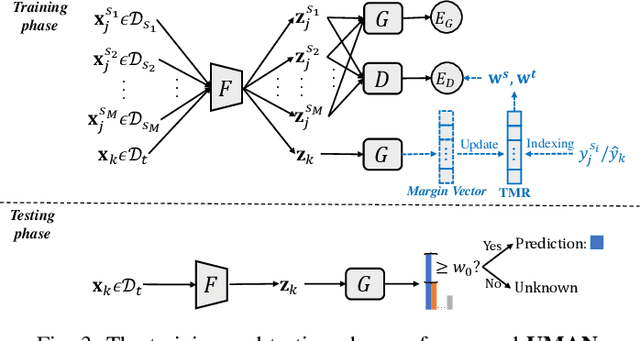
Unsupervised domain adaptation enables intelligent models to transfer knowledge from a labeled source domain to a similar but unlabeled target domain. Recent study reveals that knowledge can be transferred from one source domain to another unknown target domain, called Universal Domain Adaptation (UDA). However, in the real-world application, there are often more than one source domain to be exploited for domain adaptation. In this paper, we formally propose a more general domain adaptation setting, universal multi-source domain adaptation (UMDA), where the label sets of multiple source domains can be different and the label set of target domain is completely unknown. The main challenges in UMDA are to identify the common label set between each source domain and target domain, and to keep the model scalable as the number of source domains increases. To address these challenges, we propose a universal multi-source adaptation network (UMAN) to solve the domain adaptation problem without increasing the complexity of the model in various UMDA settings. In UMAN, we estimate the reliability of each known class in the common label set via the prediction margin, which helps adversarial training to better align the distributions of multiple source domains and target domain in the common label set. Moreover, the theoretical guarantee for UMAN is also provided. Massive experimental results show that existing UDA and multi-source DA (MDA) methods cannot be directly applied to UMDA and the proposed UMAN achieves the state-of-the-art performance in various UMDA settings.
Unveiling Class-Labeling Structure for Universal Domain Adaptation
Oct 10, 2020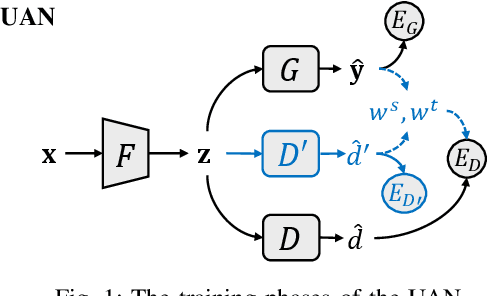
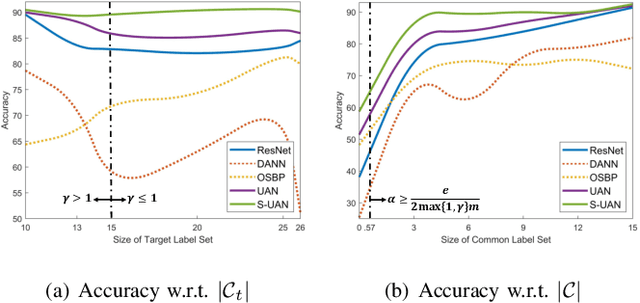
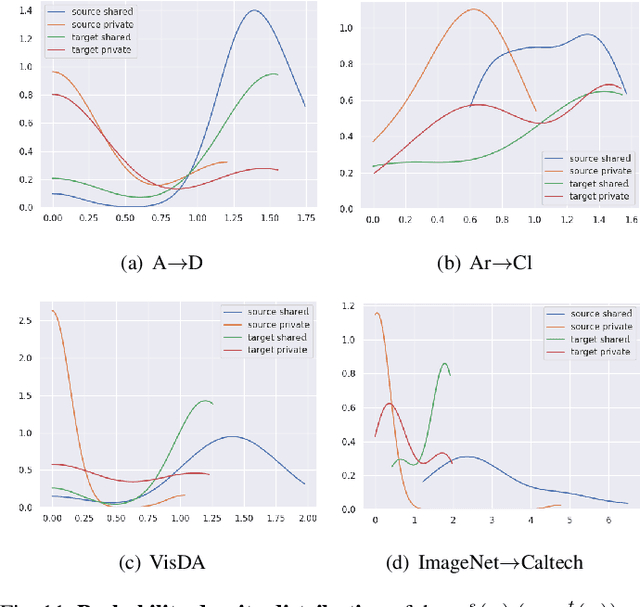
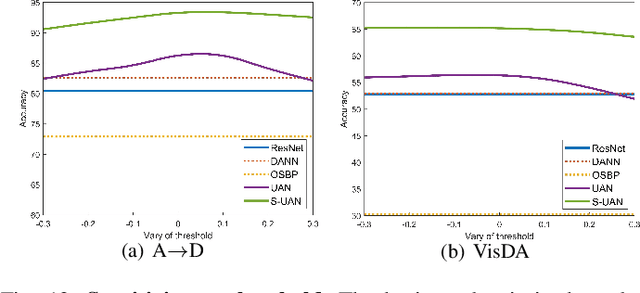
As a more practical setting for unsupervised domain adaptation, Universal Domain Adaptation (UDA) is recently introduced, where the target label set is unknown. One of the big challenges in UDA is how to determine the common label set shared by source and target domains, as there is simply no labeling available in the target domain. In this paper, we employ a probabilistic approach for locating the common label set, where each source class may come from the common label set with a probability. In particular, we propose a novel approach for evaluating the probability of each source class from the common label set, where this probability is computed by the prediction margin accumulated over the whole target domain. Then, we propose a simple universal adaptation network (S-UAN) by incorporating the probabilistic structure for the common label set. Finally, we analyse the generalization bound focusing on the common label set and explore the properties on the target risk for UDA. Extensive experiments indicate that S-UAN works well in different UDA settings and outperforms the state-of-the-art methods by large margins.
Branch-Cooperative OSNet for Person Re-Identification
Jun 12, 2020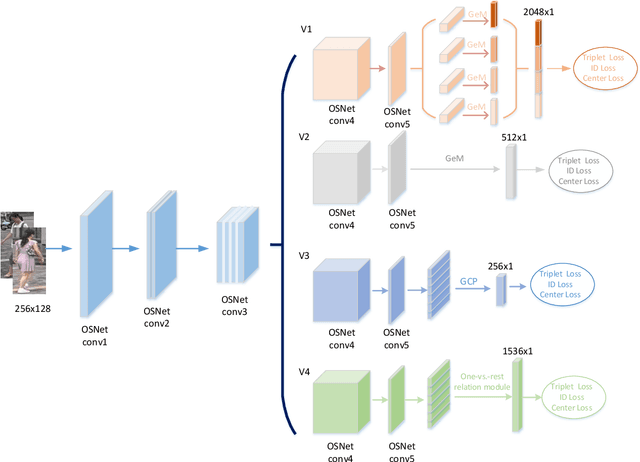
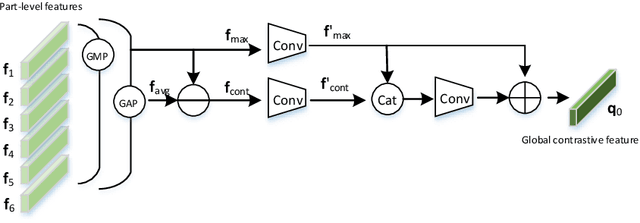
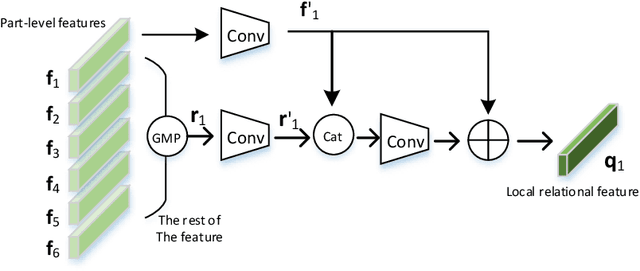
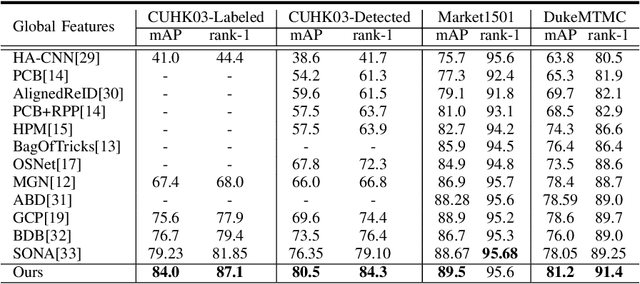
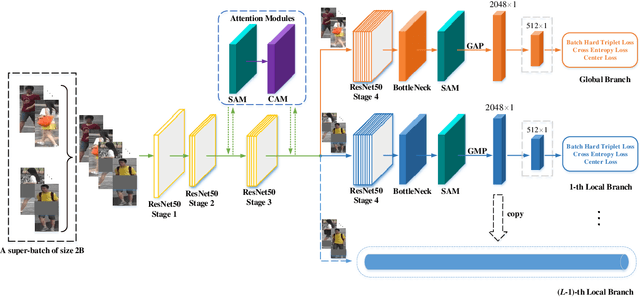
Multi-branch is extensively studied for learning rich feature representation for person re-identification (Re-ID). In this paper, we propose a branch-cooperative architecture over OSNet, termed BC-OSNet, for person Re-ID. By stacking four cooperative branches, namely, a global branch, a local branch, a relational branch and a contrastive branch, we obtain powerful feature representation for person Re-ID. Extensive experiments show that the proposed BC-OSNet achieves state-of-art performance on the three popular datasets, including Market-1501, DukeMTMC-reID and CUHK03. In particular, it achieves mAP of 84.0% and rank-1 accuracy of 87.1% on the CUHK03_labeled.
Metric-Learning-Assisted Domain Adaptation
Apr 25, 2020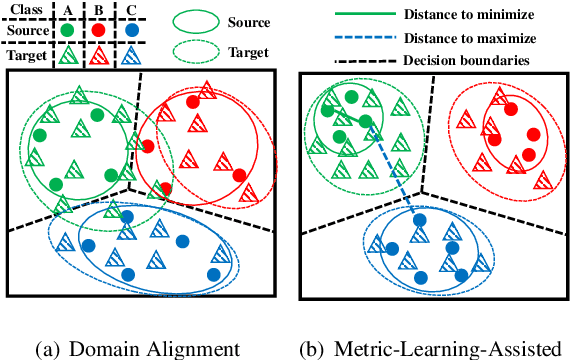
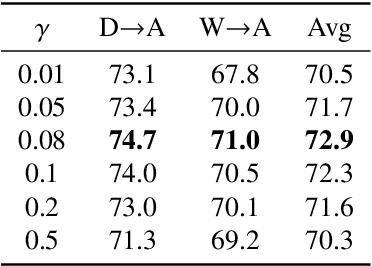
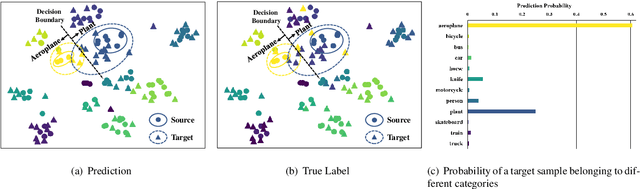
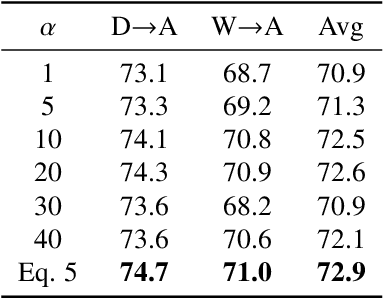
Domain alignment (DA) has been widely used in unsupervised domain adaptation. Many existing DA methods assume that a low source risk, together with the alignment of distributions of source and target, means a low target risk. In this paper, we show that this does not always hold. We thus propose a novel metric-learning-assisted domain adaptation (MLA-DA) method, which employs a novel triplet loss for helping better feature alignment. Experimental results show that the use of proposed triplet loss can achieve clearly better results. We also demonstrate the performance improvement of MLA-DA on all four standard benchmarks compared with the state-of-the-art unsupervised domain adaptation methods. Furthermore, MLA-DA shows stable performance in robust experiments.
BiCANet: Bi-directional Contextual Aggregating Network for Image Semantic Segmentation
Mar 21, 2020
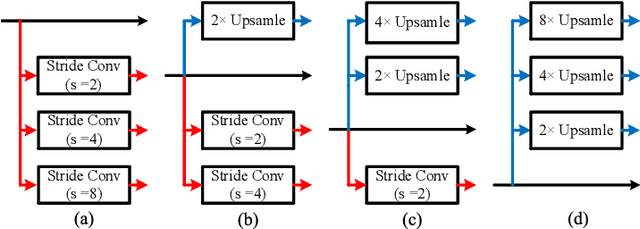

Exploring contextual information in convolution neural networks (CNNs) has gained substantial attention in recent years for semantic segmentation. This paper introduces a Bi-directional Contextual Aggregating Network, called BiCANet, for semantic segmentation. Unlike previous approaches that encode context in feature space, BiCANet aggregates contextual cues from a categorical perspective, which is mainly consist of three parts: contextual condensed projection block (CCPB), bi-directional context interaction block (BCIB), and muti-scale contextual fusion block (MCFB). More specifically, CCPB learns a category-based mapping through a split-transform-merge architecture, which condenses contextual cues with different receptive fields from intermediate layer. BCIB, on the other hand, employs dense skipped-connections to enhance the class-level context exchanging. Finally, MCFB integrates multi-scale contextual cues by investigating short- and long-ranged spatial dependencies. To evaluate BiCANet, we have conducted extensive experiments on three semantic segmentation datasets: PASCAL VOC 2012, Cityscapes, and ADE20K. The experimental results demonstrate that BiCANet outperforms recent state-of-the-art networks without any postprocess techniques. Particularly, BiCANet achieves the mIoU score of 86.7%, 82.4% and 38.66% on PASCAL VOC 2012, Cityscapes and ADE20K testset, respectively.
Diversity-Achieving Slow-DropBlock Network for Person Re-Identification
Feb 09, 2020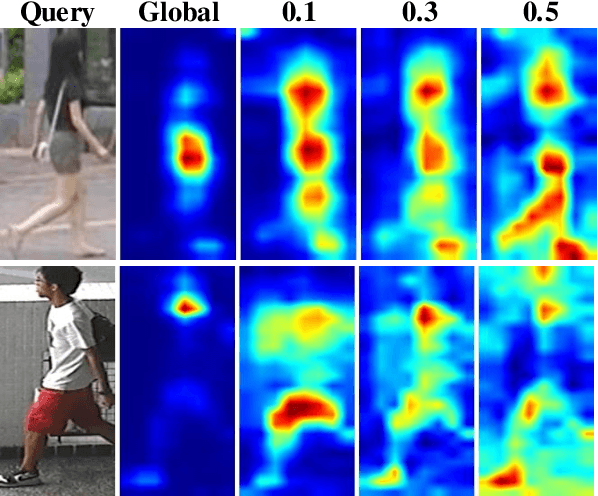

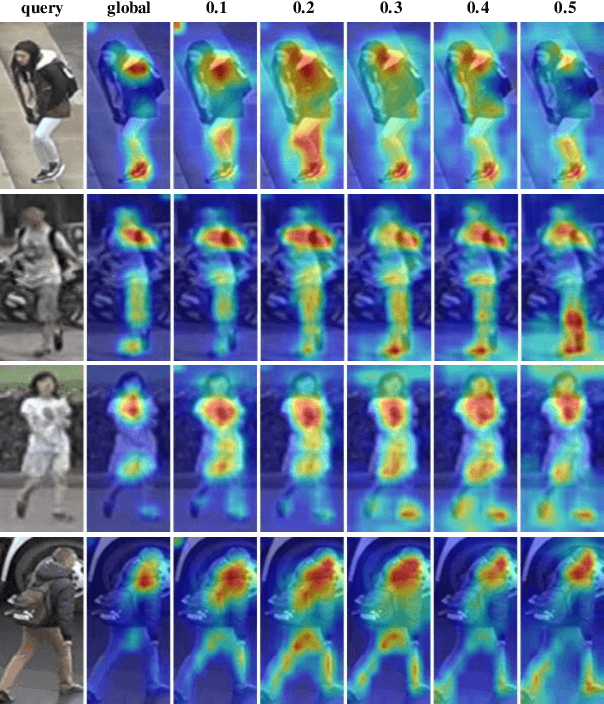
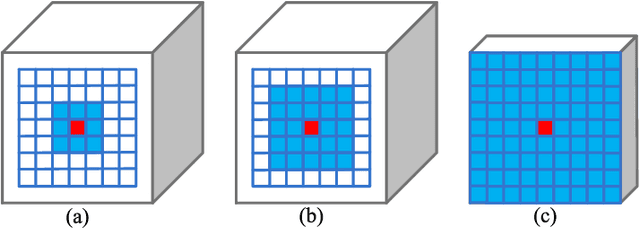
A big challenge of person re-identification (Re-ID) using a multi-branch network architecture is to learn diverse features from the ID-labeled dataset. The 2-branch Batch DropBlock (BDB) network was recently proposed for achieving diversity between the global branch and the feature-dropping branch. In this paper, we propose to move the dropping operation from the intermediate feature layer towards the input (image dropping). Since it may drop a large portion of input images, this makes the training hard to converge. Hence, we propose a novel double-batch-split co-training approach for remedying this problem. In particular, we show that the feature diversity can be well achieved with the use of multiple dropping branches by setting individual dropping ratio for each branch. Empirical evidence demonstrates that the proposed method performs superior to BDB on popular person Re-ID datasets, including Market-1501, DukeMTMC-reID and CUHK03 and the use of more dropping branches can further boost the performance.