 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Multi-Source Domain Adaptation
Nov 05, 2020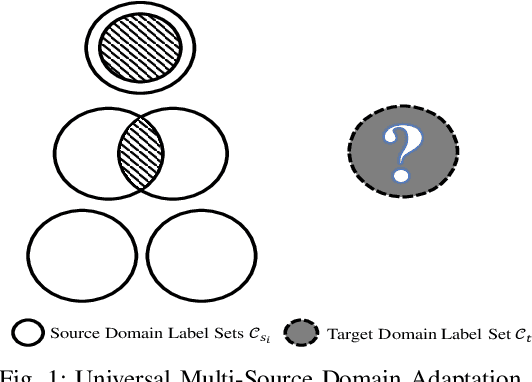
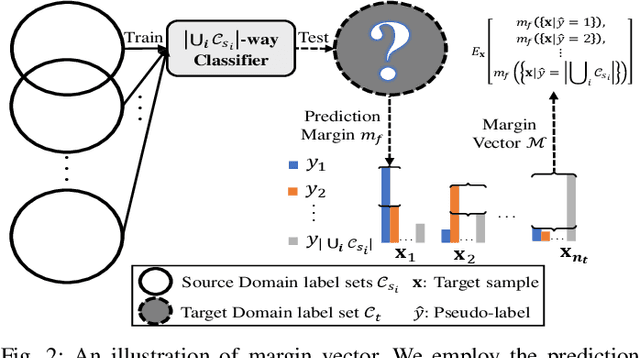
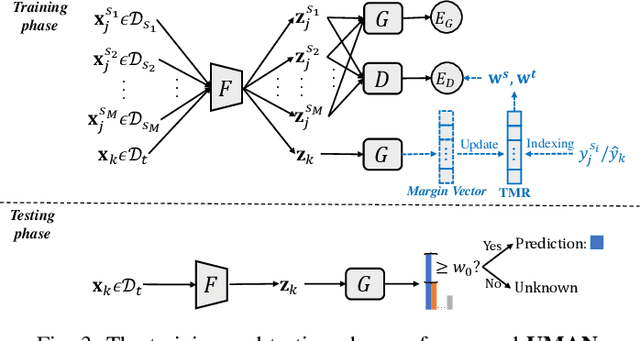
Unsupervised domain adaptation enables intelligent models to transfer knowledge from a labeled source domain to a similar but unlabeled target domain. Recent study reveals that knowledge can be transferred from one source domain to another unknown target domain, called Universal Domain Adaptation (UDA). However, in the real-world application, there are often more than one source domain to be exploited for domain adaptation. In this paper, we formally propose a more general domain adaptation setting, universal multi-source domain adaptation (UMDA), where the label sets of multiple source domains can be different and the label set of target domain is completely unknown. The main challenges in UMDA are to identify the common label set between each source domain and target domain, and to keep the model scalable as the number of source domains increases. To address these challenges, we propose a universal multi-source adaptation network (UMAN) to solve the domain adaptation problem without increasing the complexity of the model in various UMDA settings. In UMAN, we estimate the reliability of each known class in the common label set via the prediction margin, which helps adversarial training to better align the distributions of multiple source domains and target domain in the common label set. Moreover, the theoretical guarantee for UMAN is also provided. Massive experimental results show that existing UDA and multi-source DA (MDA) methods cannot be directly applied to UMDA and the proposed UMAN achieves the state-of-the-art performance in various UMDA settings.
Unveiling Class-Labeling Structure for Universal Domain Adaptation
Oct 10, 2020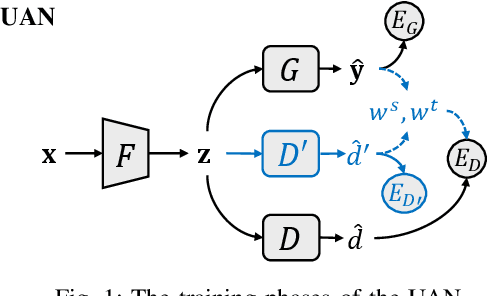
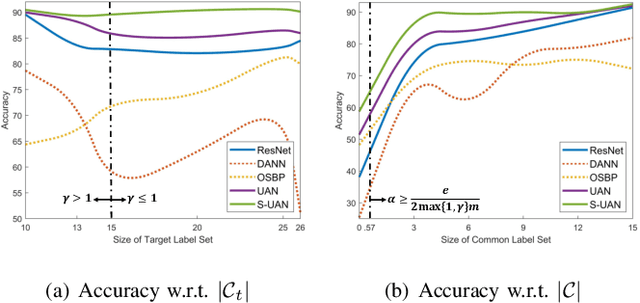
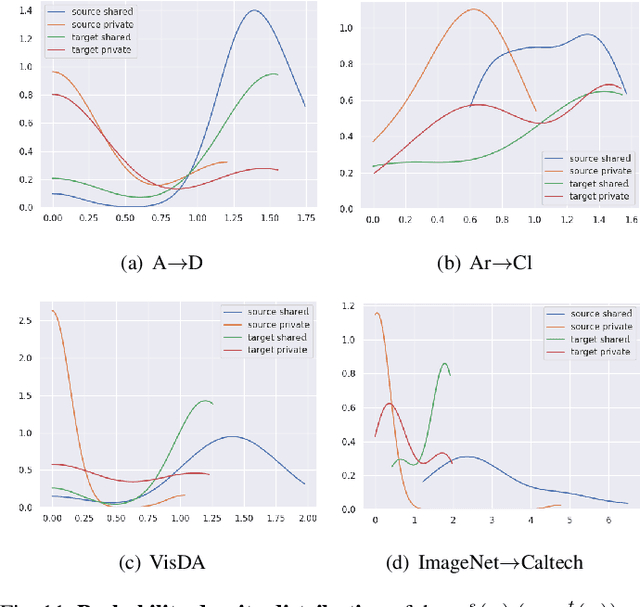
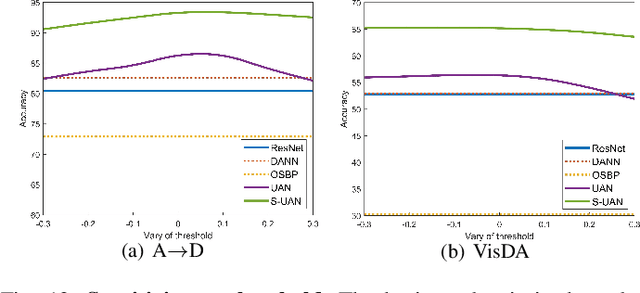
As a more practical setting for unsupervised domain adaptation, Universal Domain Adaptation (UDA) is recently introduced, where the target label set is unknown. One of the big challenges in UDA is how to determine the common label set shared by source and target domains, as there is simply no labeling available in the target domain. In this paper, we employ a probabilistic approach for locating the common label set, where each source class may come from the common label set with a probability. In particular, we propose a novel approach for evaluating the probability of each source class from the common label set, where this probability is computed by the prediction margin accumulated over the whole target domain. Then, we propose a simple universal adaptation network (S-UAN) by incorporating the probabilistic structure for the common label set. Finally, we analyse the generalization bound focusing on the common label set and explore the properties on the target risk for UDA. Extensive experiments indicate that S-UAN works well in different UDA settings and outperforms the state-of-the-art methods by large margins.
Metric-Learning-Assisted Domain Adaptation
Apr 25, 2020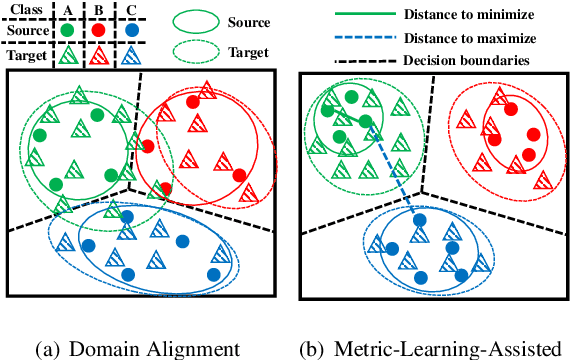
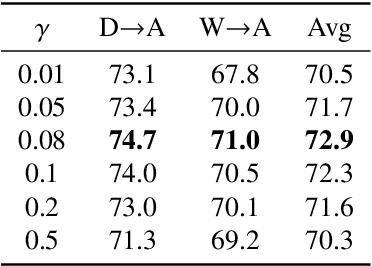
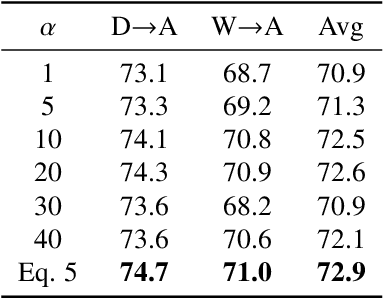
Domain alignment (DA) has been widely used in unsupervised domain adaptation. Many existing DA methods assume that a low source risk, together with the alignment of distributions of source and target, means a low target risk. In this paper, we show that this does not always hold. We thus propose a novel metric-learning-assisted domain adaptation (MLA-DA) method, which employs a novel triplet loss for helping better feature alignment. Experimental results show that the use of proposed triplet loss can achieve clearly better results. We also demonstrate the performance improvement of MLA-DA on all four standard benchmarks compared with the state-of-the-art unsupervised domain adaptation methods. Furthermore, MLA-DA shows stable performance in robust experiments.