 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Class-Labeling Structure for Universal Domain Adaptation
Paper and Code
Oct 10, 2020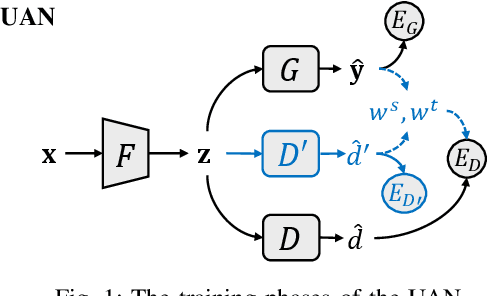
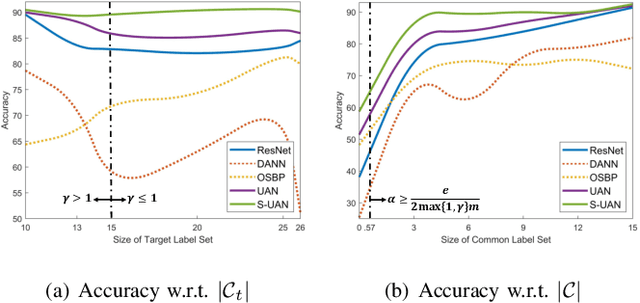
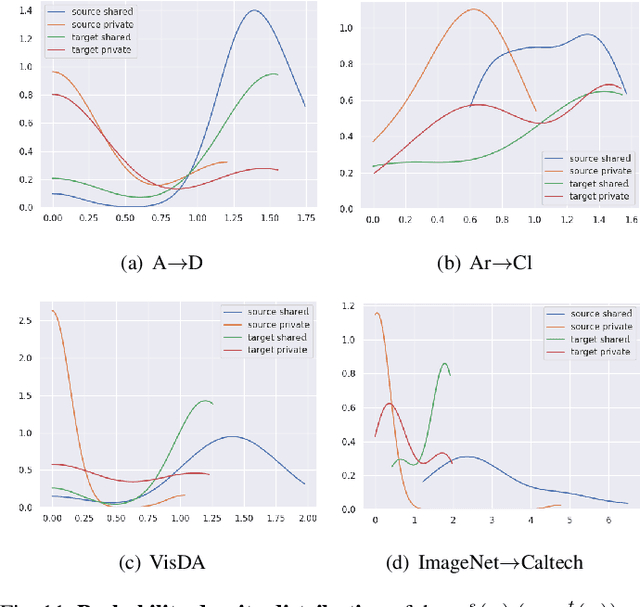
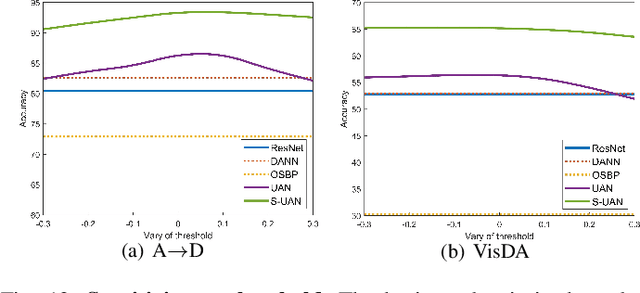
As a more practical setting for unsupervised domain adaptation, Universal Domain Adaptation (UDA) is recently introduced, where the target label set is unknown. One of the big challenges in UDA is how to determine the common label set shared by source and target domains, as there is simply no labeling available in the target domain. In this paper, we employ a probabilistic approach for locating the common label set, where each source class may come from the common label set with a probability. In particular, we propose a novel approach for evaluating the probability of each source class from the common label set, where this probability is computed by the prediction margin accumulated over the whole target domain. Then, we propose a simple universal adaptation network (S-UAN) by incorporating the probabilistic structure for the common label set. Finally, we analyse the generalization bound focusing on the common label set and explore the properties on the target risk for UDA. Extensive experiments indicate that S-UAN works well in different UDA settings and outperforms the state-of-the-art methods by large margins.