 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Semantic-Aware Communication Based on Hypergraph Reasoning
Jun 18, 2026Semantic-aware communication has emerged as a transformative paradigm for next-generation communication systems, shifting the fundamental goal from transmitting bit-level symbols to reliably recovering and understanding the semantic meaning of information. Previous studies have demonstrated that representing the semantic content of source messages as graph-based structures can significantly improve communication efficiency and the accuracy of semantic inference at the receiver. However, existing solutions typically employ graphs that capture only pairwise relationships, thereby neglecting higher-order implicit correlations commonly observed in real-world scenarios, such as group interactions, multi-entity associations, and complex relational contexts. This limitation reduces semantic expressiveness and makes semantic inference susceptible to ambiguity and performance degradation, particularly under noisy or corrupted channel conditions. To address these issues, this paper proposes a novel hypergraph-based implicit semantic reasoning framework, HISR, which leverages hypergraphs to represent complex multi-entity relationships among semantic knowledge entities. In HISR, entities and their associated higher-order relations are mapped into dedicated semantic subspaces tailored to distinct relational contexts. This design not only disentangles diverse semantic interactions to mitigate the over-smoothing effects commonly found in traditional graph embedding methods but also enables robust semantic inference even when partial information loss occurs during transmission. Numerical results show that the proposed HISR achieves up to a 36.6% improvement in implicit semantic interpretation accuracy over the state-of-the-art benchmarks.
SANEmerg: An Emergent Communication Framework for Semantic-aware Agentic AI Networking
May 07, 2026Future networking systems are envisioned to become part of an agentic AI-native ecosystem in which a vast number of heterogeneous and specialized AI agents cooperate seamlessly to fulfill complex user requirements in real time. However, traditional networking paradigms are characterized by a rigid decoupling of communication and computation, which often leads to significant inefficiencies in large-scale agentic AI networking (AgentNet) systems. Emergent communication offers a novel solution by enabling autonomous agents that support task-specific signaling protocols for information exchange and collaborative coordination. In this paper, we consider a multi-agent emergent communication framework, tailored for semantic-aware AgentNet systems in which the user's semantic intent can be automatically detected, inferred, and linked to a set of sub-tasks to be assigned to a set of agents. We investigate how communication and signaling protocols can emerge among collaborative agents with computationally bounded intelligence under stringent bandwidth constraints. Our proposed framework, called SANEmerg, is designed to facilitate the emergence of communication for collaborative task fulfillment while adhering to the physical limits of AgentNet. SANEmerg incorporates a bandwidth-adaptable importance-filter that dynamically prioritizes the transmission of higher-contribution message dimensions, ensuring robust performance in bandwidth-limited environments. Furthermore, SANEmerg integrates a complexity-regularizer grounded in the Minimum Description Length (MDL) principle to facilitate the emergence of computationally bounded signaling. Evaluated via an AgentNet prototype and extensive experimentation, SANEmerg demonstrates significant performance improvements over state-of-the-art solutions, achieving superior task accuracy while significantly reducing bandwidth and computational overhead.
On the Rate-Distortion-Complexity Tradeoff for Semantic Communication
Feb 16, 2026Semantic communication is a novel communication paradigm that focuses on conveying the user's intended meaning rather than the bit-wise transmission of source signals. One of the key challenges is to effectively represent and extract the semantic meaning of any given source signals. While deep learning (DL)-based solutions have shown promising results in extracting implicit semantic information from a wide range of sources, existing work often overlooks the high computational complexity inherent in both model training and inference for the DL-based encoder and decoder. To bridge this gap, this paper proposes a rate-distortion-complexity (RDC) framework which extends the classical rate-distortion theory by incorporating the constraints on semantic distance, including both the traditional bit-wise distortion metric and statistical difference-based divergence metric, and complexity measure, adopted from the theory of minimum description length and information bottleneck. We derive the closed-form theoretical results of the minimum achievable rate under given constraints on semantic distance and complexity for both Gaussian and binary semantic sources. Our theoretical results show a fundamental three-way tradeoff among achievable rate, semantic distance, and model complexity. Extensive experiments on real-world image and video datasets validate this tradeoff and further demonstrate that our information-theoretic complexity measure effectively correlates with practical computational costs, guiding efficient system design in resource-constrained scenarios.
HoGS: Homophily-Oriented Graph Synthesis for Local Differentially Private GNN Training
Feb 09, 2026Graph neural networks (GNNs) have demonstrated remarkable performance in various graph-based machine learning tasks by effectively modeling high-order interactions between nodes. However, training GNNs without protection may leak sensitive personal information in graph data, including links and node features. Local differential privacy (LDP) is an advanced technique for protecting data privacy in decentralized networks. Unfortunately, existing local differentially private GNNs either only preserve link privacy or suffer significant utility loss in the process of preserving link and node feature privacy. In this paper, we propose an effective LDP framework, called HoGS, which trains GNNs with link and feature protection by generating a synthetic graph. Concretely, HoGS first collects the link and feature information of the graph under LDP, and then utilizes the phenomenon of homophily in graph data to reconstruct the graph structure and node features separately, thereby effectively mitigating the negative impact of LDP on the downstream GNN training. We theoretically analyze the privacy guarantee of HoGS and conduct experiments using the generated synthetic graph as input to various state-of-the-art GNN architectures. Experimental results on three real-world datasets show that HoGS significantly outperforms baseline methods in the accuracy of training GNNs.
SANet: A Semantic-aware Agentic AI Networking Framework for Cross-layer Optimization in 6G
Dec 27, 2025Agentic AI networking (AgentNet) is a novel AI-native networking paradigm in which a large number of specialized AI agents collaborate to perform autonomous decision-making, dynamic environmental adaptation, and complex missions. It has the potential to facilitate real-time network management and optimization functions, including self-configuration, self-optimization, and self-adaptation across diverse and complex environments. This paper proposes SANet, a novel semantic-aware AgentNet architecture for wireless networks that can infer the semantic goal of the user and automatically assign agents associated with different layers of the network to fulfill the inferred goal. Motivated by the fact that AgentNet is a decentralized framework in which collaborating agents may generally have different and even conflicting objectives, we formulate the decentralized optimization of SANet as a multi-agent multi-objective problem, and focus on finding the Pareto-optimal solution for agents with distinct and potentially conflicting objectives. We propose three novel metrics for evaluating SANet. Furthermore, we develop a model partition and sharing (MoPS) framework in which large models, e.g., deep learning models, of different agents can be partitioned into shared and agent-specific parts that are jointly constructed and deployed according to agents' local computational resources. Two decentralized optimization algorithms are proposed. We derive theoretical bounds and prove that there exists a three-way tradeoff among optimization, generalization, and conflicting errors. We develop an open-source RAN and core network-based hardware prototype that implements agents to interact with three different layers of the network. Experimental results show that the proposed framework achieved performance gains of up to 14.61% while requiring only 44.37% of FLOPs required by state-of-the-art algorithms.
Robust Federated Learning against Model Perturbation in Edge Networks
May 30, 2025Federated Learning (FL) is a promising paradigm for realizing edge intelligence, allowing collaborative learning among distributed edge devices by sharing models instead of raw data. However, the shared models are often assumed to be ideal, which would be inevitably violated in practice due to various perturbations, leading to significant performance degradation. To overcome this challenge, we propose a novel method, termed Sharpness-Aware Minimization-based Robust Federated Learning (SMRFL), which aims to improve model robustness against perturbations by exploring the geometrical property of the model landscape. Specifically, SMRFL solves a min-max optimization problem that promotes model convergence towards a flat minimum by minimizing the maximum loss within a neighborhood of the model parameters. In this way, model sensitivity to perturbations is reduced, and robustness is enhanced since models in the neighborhood of the flat minimum also enjoy low loss values. The theoretical result proves that SMRFL can converge at the same rate as FL without perturbations. Extensive experimental results show that SMRFL significantly enhances robustness against perturbations compared to three baseline methods on two real-world datasets under three perturbation scenarios.
SANNet: A Semantic-Aware Agentic AI Networking Framework for Multi-Agent Cross-Layer Coordination
May 25, 2025Agentic AI networking (AgentNet) is a novel AI-native networking paradigm that relies on a large number of specialized AI agents to collaborate and coordinate for autonomous decision-making, dynamic environmental adaptation, and complex goal achievement. It has the potential to facilitate real-time network management alongside capabilities for self-configuration, self-optimization, and self-adaptation across diverse and complex networking environments, laying the foundation for fully autonomous networking systems in the future. Despite its promise, AgentNet is still in the early stage of development, and there still lacks an effective networking framework to support automatic goal discovery and multi-agent self-orchestration and task assignment. This paper proposes SANNet, a novel semantic-aware agentic AI networking architecture that can infer the semantic goal of the user and automatically assign agents associated with different layers of a mobile system to fulfill the inferred goal. Motivated by the fact that one of the major challenges in AgentNet is that different agents may have different and even conflicting objectives when collaborating for certain goals, we introduce a dynamic weighting-based conflict-resolving mechanism to address this issue. We prove that SANNet can provide theoretical guarantee in both conflict-resolving and model generalization performance for multi-agent collaboration in dynamic environment. We develop a hardware prototype of SANNet based on the open RAN and 5GS core platform. Our experimental results show that SANNet can significantly improve the performance of multi-agent networking systems, even when agents with conflicting objectives are selected to collaborate for the same goal.
Towards Agentic AI Networking in 6G: A Generative Foundation Model-as-Agent Approach
Mar 20, 2025The promising potential of AI and network convergence in improving networking performance and enabling new service capabilities has recently attracted significant interest. Existing network AI solutions, while powerful, are mainly built based on the close-loop and passive learning framework, resulting in major limitations in autonomous solution finding and dynamic environmental adaptation. Agentic AI has recently been introduced as a promising solution to address the above limitations and pave the way for true generally intelligent and beneficial AI systems. The key idea is to create a networking ecosystem to support a diverse range of autonomous and embodied AI agents in fulfilling their goals. In this paper, we focus on the novel challenges and requirements of agentic AI networking. We propose AgentNet, a novel framework for supporting interaction, collaborative learning, and knowledge transfer among AI agents. We introduce a general architectural framework of AgentNet and then propose a generative foundation model (GFM)-based implementation in which multiple GFM-as-agents have been created as an interactive knowledge-base to bootstrap the development of embodied AI agents according to different task requirements and environmental features. We consider two application scenarios, digital-twin-based industrial automation and metaverse-based infotainment system, to describe how to apply AgentNet for supporting efficient task-driven collaboration and interaction among AI agents.
VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
Mar 09, 2025Large vision-language models (LVLMs) have demonstrated remarkable achievements, yet the generation of non-factual responses remains prevalent in fact-seeking question answering (QA). Current multimodal fact-seeking benchmarks primarily focus on comparing model outputs to ground truth answers, providing limited insights into the performance of modality-specific modules. To bridge this gap, we introduce VisualSimpleQA, a multimodal fact-seeking benchmark with two key features. First, it enables streamlined and decoupled evaluation of LVLMs in visual and linguistic modalities. Second, it incorporates well-defined difficulty criteria to guide human annotation and facilitates the extraction of a challenging subset, VisualSimpleQA-hard. Experiments on 15 LVLMs show that even state-of-the-art models such as GPT-4o achieve merely 60%+ correctness in multimodal fact-seeking QA on VisualSimpleQA and 30%+ on VisualSimpleQA-hard. Furthermore, the decoupled evaluation across these models highlights substantial opportunities for improvement in both visual and linguistic modules. The dataset is available at https://huggingface.co/datasets/WYLing/VisualSimpleQA.
Joint Source-Channel Coding: Fundamentals and Recent Progress in Practical Designs
Sep 26, 2024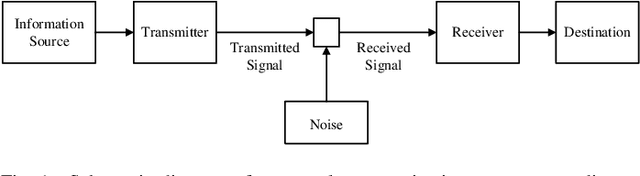

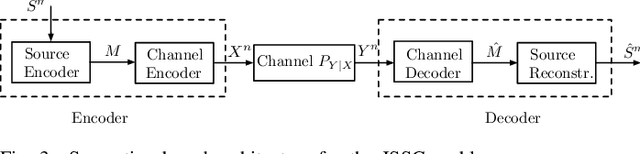

Semantic- and task-oriented communication has emerged as a promising approach to reducing the latency and bandwidth requirements of next-generation mobile networks by transmitting only the most relevant information needed to complete a specific task at the receiver. This is particularly advantageous for machine-oriented communication of high data rate content, such as images and videos, where the goal is rapid and accurate inference, rather than perfect signal reconstruction. While semantic- and task-oriented compression can be implemented in conventional communication systems, joint source-channel coding (JSCC) offers an alternative end-to-end approach by optimizing compression and channel coding together, or even directly mapping the source signal to the modulated waveform. Although all digital communication systems today rely on separation, thanks to its modularity, JSCC is known to achieve higher performance in finite blocklength scenarios, and to avoid cliff and the levelling-off effects in time-varying channel scenarios. This article provides an overview of the information theoretic foundations of JSCC, surveys practical JSCC designs over the decades, and discusses the reasons for their limited adoption in practical systems. We then examine the recent resurgence of JSCC, driven by the integration of deep learning techniques, particularly through DeepJSCC, highlighting its many surprising advantages in various scenarios. Finally, we discuss why it may be time to reconsider today's strictly separate architectures, and reintroduce JSCC to enable high-fidelity, low-latency communications in critical applications such as autonomous driving, drone surveillance, or wearable systems.