 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSANet: A Semantic-aware Agentic AI Networking Framework for Cross-layer Optimization in 6G
Dec 27, 2025Agentic AI networking (AgentNet) is a novel AI-native networking paradigm in which a large number of specialized AI agents collaborate to perform autonomous decision-making, dynamic environmental adaptation, and complex missions. It has the potential to facilitate real-time network management and optimization functions, including self-configuration, self-optimization, and self-adaptation across diverse and complex environments. This paper proposes SANet, a novel semantic-aware AgentNet architecture for wireless networks that can infer the semantic goal of the user and automatically assign agents associated with different layers of the network to fulfill the inferred goal. Motivated by the fact that AgentNet is a decentralized framework in which collaborating agents may generally have different and even conflicting objectives, we formulate the decentralized optimization of SANet as a multi-agent multi-objective problem, and focus on finding the Pareto-optimal solution for agents with distinct and potentially conflicting objectives. We propose three novel metrics for evaluating SANet. Furthermore, we develop a model partition and sharing (MoPS) framework in which large models, e.g., deep learning models, of different agents can be partitioned into shared and agent-specific parts that are jointly constructed and deployed according to agents' local computational resources. Two decentralized optimization algorithms are proposed. We derive theoretical bounds and prove that there exists a three-way tradeoff among optimization, generalization, and conflicting errors. We develop an open-source RAN and core network-based hardware prototype that implements agents to interact with three different layers of the network. Experimental results show that the proposed framework achieved performance gains of up to 14.61% while requiring only 44.37% of FLOPs required by state-of-the-art algorithms.
Enabling Disaggregated Multi-Stage MLLM Inference via GPU-Internal Scheduling and Resource Sharing
Dec 19, 2025Multimodal large language models (MLLMs) extend LLMs with visual understanding through a three-stage pipeline: multimodal preprocessing, vision encoding, and LLM inference. While these stages enhance capability, they introduce significant system bottlenecks. First, multimodal preprocessing-especially video decoding-often dominates Time-to-First-Token (TTFT). Most systems rely on CPU-based decoding, which severely limits throughput, while existing GPU-based approaches prioritize throughput-oriented parallelism and fail to meet the latency-sensitive requirements of MLLM inference. Second, the vision encoder is a standalone, compute-intensive stage that produces visual embeddings and cannot be co-batched with LLM prefill or decoding. This heterogeneity forces inter-stage blocking and increases token-generation latency. Even when deployed on separate GPUs, these stages underutilize available compute and memory resources, reducing overall utilization and constraining system throughput. To address these challenges, we present FlashCodec and UnifiedServe, two complementary designs that jointly optimize the end-to-end MLLM pipeline. FlashCodec accelerates the multimodal preprocessing stage through collaborative multi-GPU video decoding, reducing decoding latency while preserving high throughput. UnifiedServe optimizes the vision-to-text and inference stages using a logically decoupled their execution to eliminate inter-stage blocking, yet physically sharing GPU resources to maximize GPU system utilization. By carefully orchestrating execution across stages and minimizing interference, UnifiedServe Together, our proposed framework forms an end-to-end optimized stack that can serve up to 3.0$\times$ more requests or enforce 1.5$\times$ tighter SLOs, while achieving up to 4.4$\times$ higher throughput compared to state-of-the-art systems.
Adapting Whisper for Streaming Speech Recognition via Two-Pass Decoding
Jun 13, 2025OpenAI Whisper is a family of robust Automatic Speech Recognition (ASR) models trained on 680,000 hours of audio. However, its encoder-decoder architecture, trained with a sequence-to-sequence objective, lacks native support for streaming ASR. In this paper, we fine-tune Whisper for streaming ASR using the WeNet toolkit by adopting a Unified Two-pass (U2) structure. We introduce an additional Connectionist Temporal Classification (CTC) decoder trained with causal attention masks to generate streaming partial transcripts, while the original Whisper decoder reranks these partial outputs. Our experiments on LibriSpeech and an earnings call dataset demonstrate that, with adequate fine-tuning data, Whisper can be adapted into a capable streaming ASR model. We also introduce a hybrid tokenizer approach, which uses a smaller token space for the CTC decoder while retaining Whisper's original token space for the attention decoder, resulting in improved data efficiency and generalization.
SANNet: A Semantic-Aware Agentic AI Networking Framework for Multi-Agent Cross-Layer Coordination
May 25, 2025Agentic AI networking (AgentNet) is a novel AI-native networking paradigm that relies on a large number of specialized AI agents to collaborate and coordinate for autonomous decision-making, dynamic environmental adaptation, and complex goal achievement. It has the potential to facilitate real-time network management alongside capabilities for self-configuration, self-optimization, and self-adaptation across diverse and complex networking environments, laying the foundation for fully autonomous networking systems in the future. Despite its promise, AgentNet is still in the early stage of development, and there still lacks an effective networking framework to support automatic goal discovery and multi-agent self-orchestration and task assignment. This paper proposes SANNet, a novel semantic-aware agentic AI networking architecture that can infer the semantic goal of the user and automatically assign agents associated with different layers of a mobile system to fulfill the inferred goal. Motivated by the fact that one of the major challenges in AgentNet is that different agents may have different and even conflicting objectives when collaborating for certain goals, we introduce a dynamic weighting-based conflict-resolving mechanism to address this issue. We prove that SANNet can provide theoretical guarantee in both conflict-resolving and model generalization performance for multi-agent collaboration in dynamic environment. We develop a hardware prototype of SANNet based on the open RAN and 5GS core platform. Our experimental results show that SANNet can significantly improve the performance of multi-agent networking systems, even when agents with conflicting objectives are selected to collaborate for the same goal.
CRA-PCN: Point Cloud Completion with Intra- and Inter-level Cross-Resolution Transformers
Jan 03, 2024



Point cloud completion is an indispensable task for recovering complete point clouds due to incompleteness caused by occlusion, limited sensor resolution, etc. The family of coarse-to-fine generation architectures has recently exhibited great success in point cloud completion and gradually became mainstream. In this work, we unveil one of the key ingredients behind these methods: meticulously devised feature extraction operations with explicit cross-resolution aggregation. We present Cross-Resolution Transformer that efficiently performs cross-resolution aggregation with local attention mechanisms. With the help of our recursive designs, the proposed operation can capture more scales of features than common aggregation operations, which is beneficial for capturing fine geometric characteristics. While prior methodologies have ventured into various manifestations of inter-level cross-resolution aggregation, the effectiveness of intra-level one and their combination has not been analyzed. With unified designs, Cross-Resolution Transformer can perform intra- or inter-level cross-resolution aggregation by switching inputs. We integrate two forms of Cross-Resolution Transformers into one up-sampling block for point generation, and following the coarse-to-fine manner, we construct CRA-PCN to incrementally predict complete shapes with stacked up-sampling blocks. Extensive experiments demonstrate that our method outperforms state-of-the-art methods by a large margin on several widely used benchmarks. Codes are available at https://github.com/EasyRy/CRA-PCN.
Interpretation on Multi-modal Visual Fusion
Aug 19, 2023In this paper, we present an analytical framework and a novel metric to shed light on the interpretation of the multimodal vision community. Our approach involves measuring the proposed semantic variance and feature similarity across modalities and levels, and conducting semantic and quantitative analyses through comprehensive experiments. Specifically, we investigate the consistency and speciality of representations across modalities, evolution rules within each modality, and the collaboration logic used when optimizing a multi-modality model. Our studies reveal several important findings, such as the discrepancy in cross-modal features and the hybrid multi-modal cooperation rule, which highlights consistency and speciality simultaneously for complementary inference. Through our dissection and findings on multi-modal fusion, we facilitate a rethinking of the reasonability and necessity of popular multi-modal vision fusion strategies. Furthermore, our work lays the foundation for designing a trustworthy and universal multi-modal fusion model for a variety of tasks in the future.
SeedFormer: Patch Seeds based Point Cloud Completion with Upsample Transformer
Jul 21, 2022
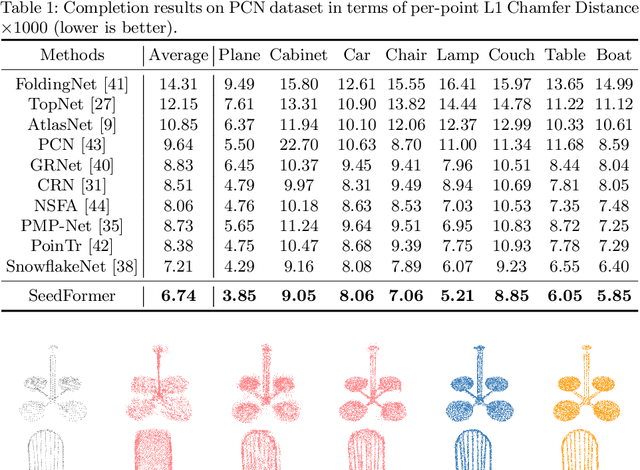
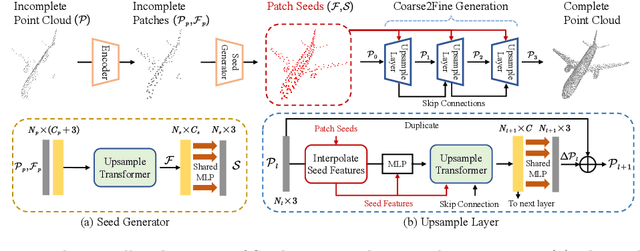
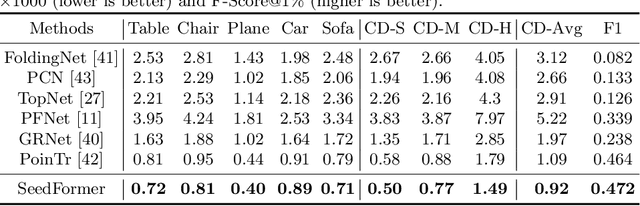
Point cloud completion has become increasingly popular among generation tasks of 3D point clouds, as it is a challenging yet indispensable problem to recover the complete shape of a 3D object from its partial observation. In this paper, we propose a novel SeedFormer to improve the ability of detail preservation and recovery in point cloud completion. Unlike previous methods based on a global feature vector, we introduce a new shape representation, namely Patch Seeds, which not only captures general structures from partial inputs but also preserves regional information of local patterns. Then, by integrating seed features into the generation process, we can recover faithful details for complete point clouds in a coarse-to-fine manner. Moreover, we devise an Upsample Transformer by extending the transformer structure into basic operations of point generators, which effectively incorporates spatial and semantic relationships between neighboring points. Qualitative and quantitative evaluations demonstrate that our method outperforms state-of-the-art completion networks on several benchmark datasets. Our code is available at https://github.com/hrzhou2/seedformer.
AGConv: Adaptive Graph Convolution on 3D Point Clouds
Jun 09, 2022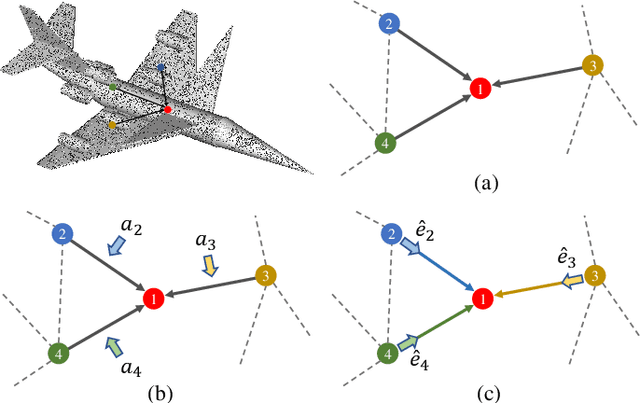


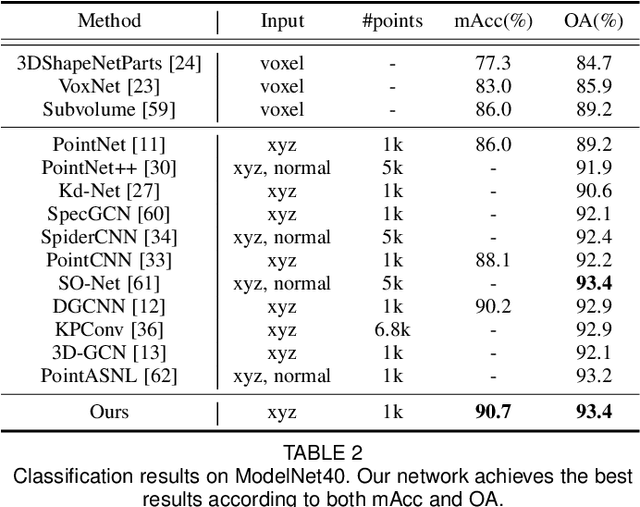
Convolution on 3D point clouds is widely researched yet far from perfect in geometric deep learning. The traditional wisdom of convolution characterises feature correspondences indistinguishably among 3D points, arising an intrinsic limitation of poor distinctive feature learning. In this paper, we propose Adaptive Graph Convolution (AGConv) for wide applications of point cloud analysis. AGConv generates adaptive kernels for points according to their dynamically learned features. Compared with the solution of using fixed/isotropic kernels, AGConv improves the flexibility of point cloud convolutions, effectively and precisely capturing the diverse relations between points from different semantic parts. Unlike the popular attentional weight schemes, AGConv implements the adaptiveness inside the convolution operation instead of simply assigning different weights to the neighboring points. Extensive evaluations clearly show that our method outperforms state-of-the-arts of point cloud classification and segmentation on various benchmark datasets.Meanwhile, AGConv can flexibly serve more point cloud analysis approaches to boost their performance. To validate its flexibility and effectiveness, we explore AGConv-based paradigms of completion, denoising, upsampling, registration and circle extraction, which are comparable or even superior to their competitors. Our code is available at https://github.com/hrzhou2/AdaptConv-master.
Refine-Net: Normal Refinement Neural Network for Noisy Point Clouds
Mar 23, 2022


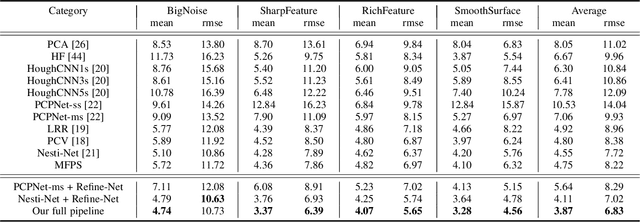
Point normal, as an intrinsic geometric property of 3D objects, not only serves conventional geometric tasks such as surface consolidation and reconstruction, but also facilitates cutting-edge learning-based techniques for shape analysis and generation. In this paper, we propose a normal refinement network, called Refine-Net, to predict accurate normals for noisy point clouds. Traditional normal estimation wisdom heavily depends on priors such as surface shapes or noise distributions, while learning-based solutions settle for single types of hand-crafted features. Differently, our network is designed to refine the initial normal of each point by extracting additional information from multiple feature representations. To this end, several feature modules are developed and incorporated into Refine-Net by a novel connection module. Besides the overall network architecture of Refine-Net, we propose a new multi-scale fitting patch selection scheme for the initial normal estimation, by absorbing geometry domain knowledge. Also, Refine-Net is a generic normal estimation framework: 1) point normals obtained from other methods can be further refined, and 2) any feature module related to the surface geometric structures can be potentially integrated into the framework. Qualitative and quantitative evaluations demonstrate the clear superiority of Refine-Net over the state-of-the-arts on both synthetic and real-scanned datasets. Our code is available at https://github.com/hrzhou2/refinenet.
Boundary Distribution Estimation to Precise Object Detection
Nov 02, 2021
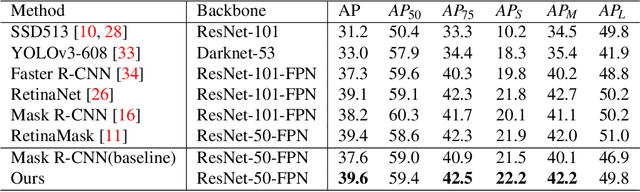
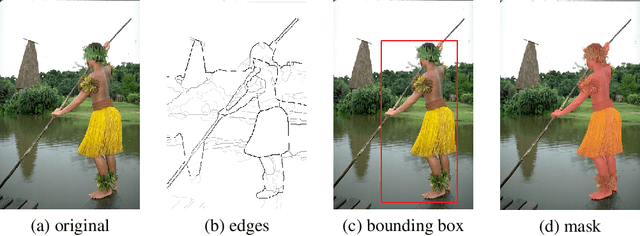
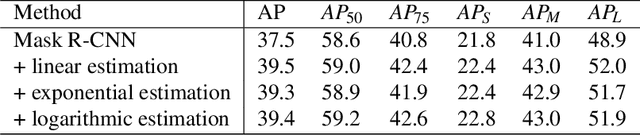
In principal modern detectors, the task of object localization is implemented by the box subnet which concentrates on bounding box regression. The box subnet customarily predicts the position of the object by regressing box center position and scaling factors. Although this approach is frequently adopted, we observe that the result of localization remains defective, which makes the performance of the detector unsatisfactory. In this paper, we prove the flaws in the previous method through theoretical analysis and experimental verification and propose a novel solution to detect objects precisely. Rather than plainly focusing on center and size, our approach refines the edges of the bounding box on previous localization results by estimating the distribution at the boundary of the object. Experimental results have shown the potentiality and generalization of our proposed method.