 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Semantic-Guided Image Smoothing Network
Sep 02, 2022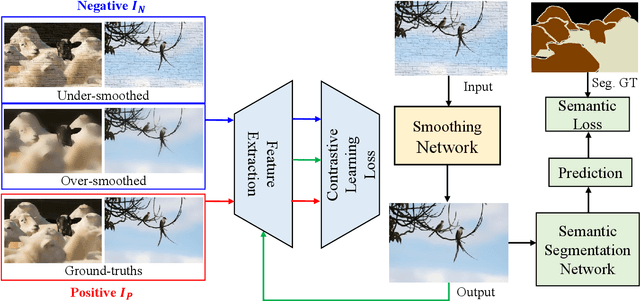
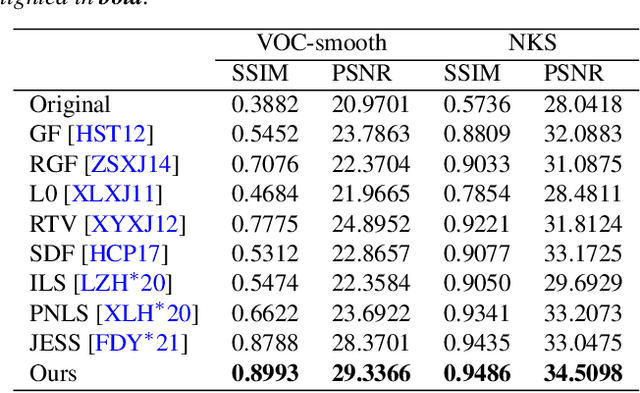
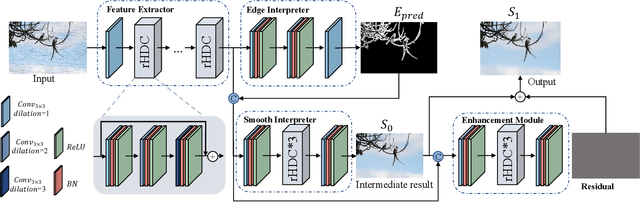

Image smoothing is a fundamental low-level vision task that aims to preserve salient structures of an image while removing insignificant details. Deep learning has been explored in image smoothing to deal with the complex entanglement of semantic structures and trivial details. However, current methods neglect two important facts in smoothing: 1) naive pixel-level regression supervised by the limited number of high-quality smoothing ground-truth could lead to domain shift and cause generalization problems towards real-world images; 2) texture appearance is closely related to object semantics, so that image smoothing requires awareness of semantic difference to apply adaptive smoothing strengths. To address these issues, we propose a novel Contrastive Semantic-Guided Image Smoothing Network (CSGIS-Net) that combines both contrastive prior and semantic prior to facilitate robust image smoothing. The supervision signal is augmented by leveraging undesired smoothing effects as negative teachers, and by incorporating segmentation tasks to encourage semantic distinctiveness. To realize the proposed network, we also enrich the original VOC dataset with texture enhancement and smoothing labels, namely VOC-smooth, which first bridges image smoothing and semantic segmentation. Extensive experiments demonstrate that the proposed CSGIS-Net outperforms state-of-the-art algorithms by a large margin. Code and dataset are available at https://github.com/wangjie6866/CSGIS-Net.
Towards Robust Part-aware Instance Segmentation for Industrial Bin Picking
Mar 05, 2022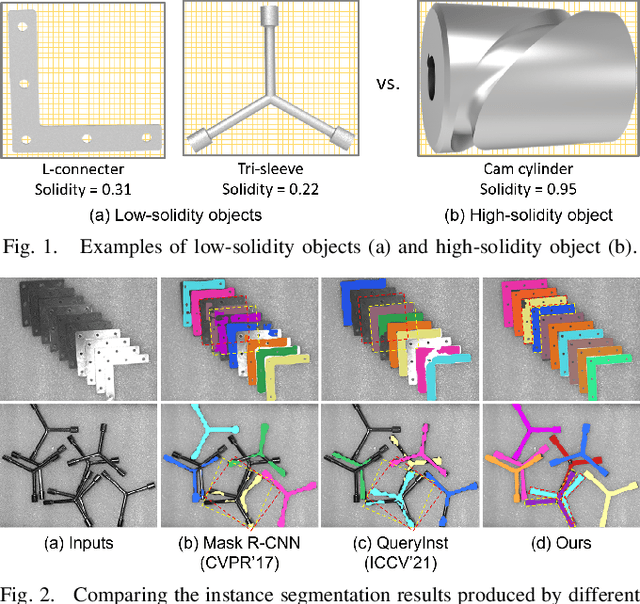

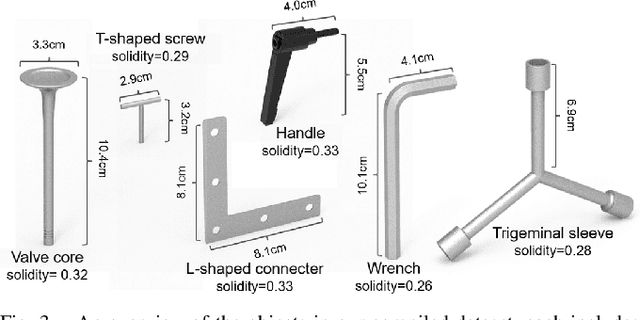
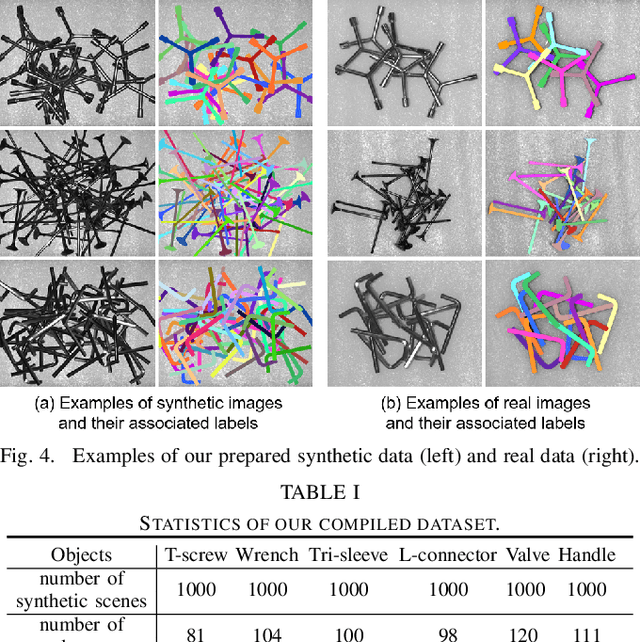
Industrial bin picking is a challenging task that requires accurate and robust segmentation of individual object instances. Particularly, industrial objects can have irregular shapes, that is, thin and concave, whereas in bin-picking scenarios, objects are often closely packed with strong occlusion. To address these challenges, we formulate a novel part-aware instance segmentation pipeline. The key idea is to decompose industrial objects into correlated approximate convex parts and enhance the object-level segmentation with part-level segmentation. We design a part-aware network to predict part masks and part-to-part offsets, followed by a part aggregation module to assemble the recognized parts into instances. To guide the network learning, we also propose an automatic label decoupling scheme to generate ground-truth part-level labels from instance-level labels. Finally, we contribute the first instance segmentation dataset, which contains a variety of industrial objects that are thin and have non-trivial shapes. Extensive experimental results on various industrial objects demonstrate that our method can achieve the best segmentation results compared with the state-of-the-art approaches.
When A Conventional Filter Meets Deep Learning: Basis Composition Learning on Image Filters
Mar 01, 2022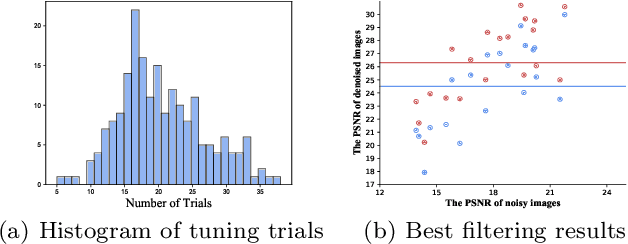
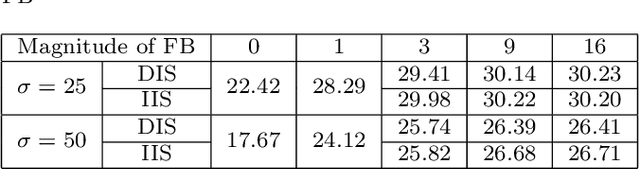
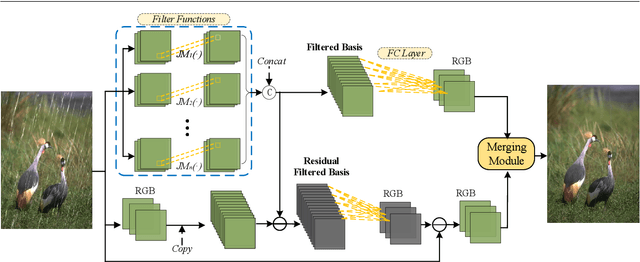
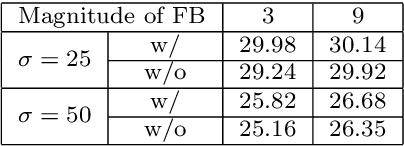
Image filters are fast, lightweight and effective, which make these conventional wisdoms preferable as basic tools in vision tasks. In practical scenarios, users have to tweak parameters multiple times to obtain satisfied results. This inconvenience heavily discounts the efficiency and user experience. We propose basis composition learning on single image filters to automatically determine their optimal formulas. The feasibility is based on a two-step strategy: first, we build a set of filtered basis (FB) consisting of approximations under selected parameter configurations; second, a dual-branch composition module is proposed to learn how the candidates in FB are combined to better approximate the target image. Our method is simple yet effective in practice; it renders filters to be user-friendly and benefits fundamental low-level vision problems including denoising, deraining and texture removal. Extensive experiments demonstrate that our method achieves an appropriate balance among the performance, time complexity and memory efficiency.
Adaptive Graph Convolution for Point Cloud Analysis
Aug 19, 2021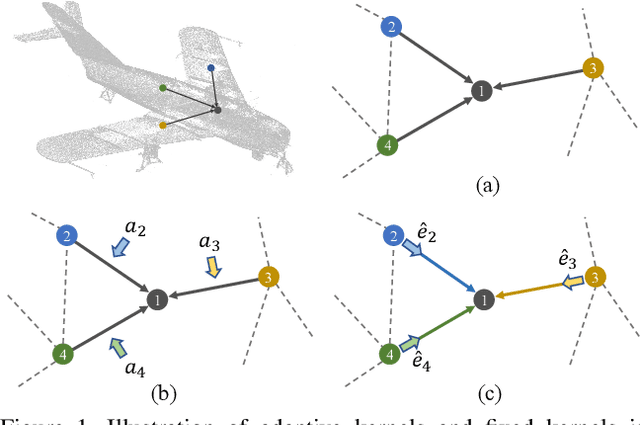
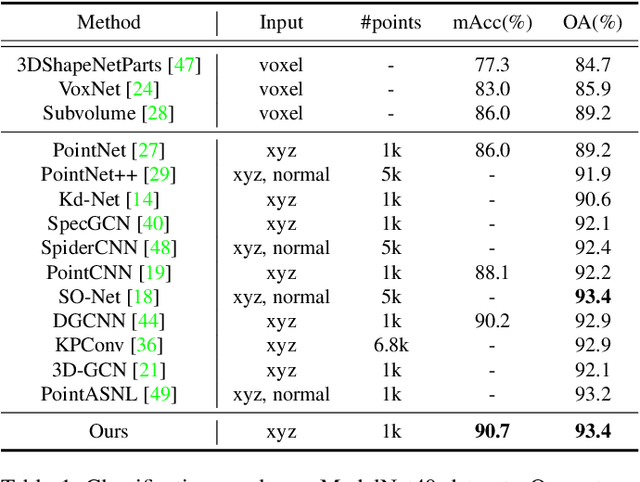


Convolution on 3D point clouds that generalized from 2D grid-like domains is widely researched yet far from perfect. The standard convolution characterises feature correspondences indistinguishably among 3D points, presenting an intrinsic limitation of poor distinctive feature learning. In this paper, we propose Adaptive Graph Convolution (AdaptConv) which generates adaptive kernels for points according to their dynamically learned features. Compared with using a fixed/isotropic kernel, AdaptConv improves the flexibility of point cloud convolutions, effectively and precisely capturing the diverse relations between points from different semantic parts. Unlike popular attentional weight schemes, the proposed AdaptConv implements the adaptiveness inside the convolution operation instead of simply assigning different weights to the neighboring points. Extensive qualitative and quantitative evaluations show that our method outperforms state-of-the-art point cloud classification and segmentation approaches on several benchmark datasets. Our code is available at https://github.com/hrzhou2/AdaptConv-master.
Direction-aware Feature-level Frequency Decomposition for Single Image Deraining
Jun 15, 2021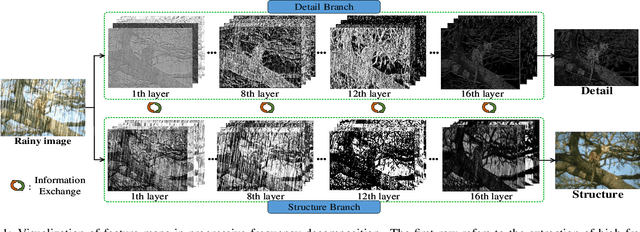
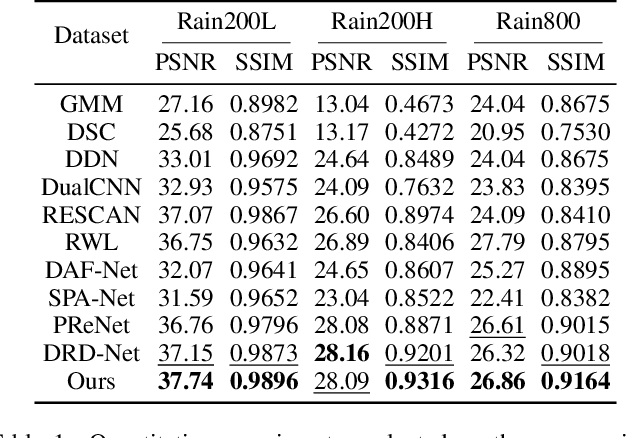
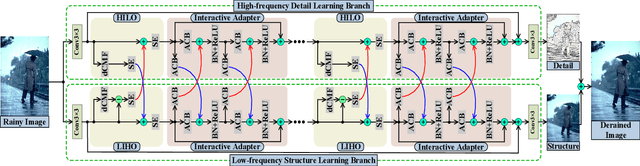
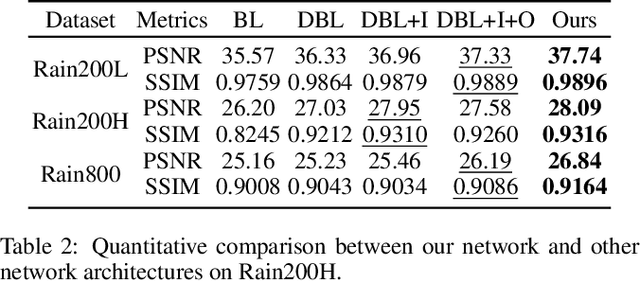
We present a novel direction-aware feature-level frequency decomposition network for single image deraining. Compared with existing solutions, the proposed network has three compelling characteristics. First, unlike previous algorithms, we propose to perform frequency decomposition at feature-level instead of image-level, allowing both low-frequency maps containing structures and high-frequency maps containing details to be continuously refined during the training procedure. Second, we further establish communication channels between low-frequency maps and high-frequency maps to interactively capture structures from high-frequency maps and add them back to low-frequency maps and, simultaneously, extract details from low-frequency maps and send them back to high-frequency maps, thereby removing rain streaks while preserving more delicate features in the input image. Third, different from existing algorithms using convolutional filters consistent in all directions, we propose a direction-aware filter to capture the direction of rain streaks in order to more effectively and thoroughly purge the input images of rain streaks. We extensively evaluate the proposed approach in three representative datasets and experimental results corroborate our approach consistently outperforms state-of-the-art deraining algorithms.
MBA-RainGAN: Multi-branch Attention Generative Adversarial Network for Mixture of Rain Removal from Single Images
May 23, 2020


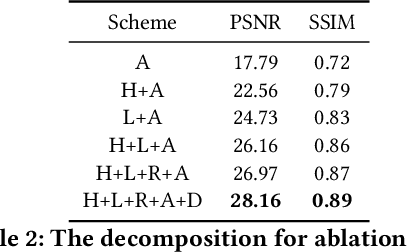
Rain severely hampers the visibility of scene objects when images are captured through glass in heavily rainy days. We observe three intriguing phenomenons that, 1) rain is a mixture of raindrops, rain streaks and rainy haze; 2) the depth from the camera determines the degrees of object visibility, where objects nearby and faraway are visually blocked by rain streaks and rainy haze, respectively; and 3) raindrops on the glass randomly affect the object visibility of the whole image space. We for the first time consider that, the overall visibility of objects is determined by the mixture of rain (MOR). However, existing solutions and established datasets lack full consideration of the MOR. In this work, we first formulate a new rain imaging model; by then, we enrich the popular RainCityscapes by considering raindrops, named RainCityscapes++. Furthermore, we propose a multi-branch attention generative adversarial network (termed an MBA-RainGAN) to fully remove the MOR. The experiment shows clear visual and numerical improvements of our approach over the state-of-the-arts on RainCityscapes++. The code and dataset will be available.