 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-based Knowledge Distillation with LLM-as-a-Judge
Apr 03, 2026Reinforcement Learning (RL) has been shown to substantially improve the reasoning capability of small and large language models (LLMs), but existing approaches typically rely on verifiable rewards, hence ground truth labels. We propose an RL framework that uses rewards from an LLM that acts as a judge evaluating model outputs over large amounts of unlabeled data, enabling label-free knowledge distillation and replacing the need of ground truth supervision. Notably, the judge operates with a single-token output, making reward computation efficient. When combined with verifiable rewards, our approach yields substantial performance gains across math reasoning benchmarks. These results suggest that LLM-based evaluators can produce effective training signals for RL fine-tuning.
High-fidelity 3D Object Generation from Single Image with RGBN-Volume Gaussian Reconstruction Model
Apr 02, 2025Recently single-view 3D generation via Gaussian splatting has emerged and developed quickly. They learn 3D Gaussians from 2D RGB images generated from pre-trained multi-view diffusion (MVD) models, and have shown a promising avenue for 3D generation through a single image. Despite the current progress, these methods still suffer from the inconsistency jointly caused by the geometric ambiguity in the 2D images, and the lack of structure of 3D Gaussians, leading to distorted and blurry 3D object generation. In this paper, we propose to fix these issues by GS-RGBN, a new RGBN-volume Gaussian Reconstruction Model designed to generate high-fidelity 3D objects from single-view images. Our key insight is a structured 3D representation can simultaneously mitigate the afore-mentioned two issues. To this end, we propose a novel hybrid Voxel-Gaussian representation, where a 3D voxel representation contains explicit 3D geometric information, eliminating the geometric ambiguity from 2D images. It also structures Gaussians during learning so that the optimization tends to find better local optima. Our 3D voxel representation is obtained by a fusion module that aligns RGB features and surface normal features, both of which can be estimated from 2D images. Extensive experiments demonstrate the superiority of our methods over prior works in terms of high-quality reconstruction results, robust generalization, and good efficiency.
Cross-Resolution Land Cover Classification Using Outdated Products and Transformers
Mar 06, 2024



Large-scale high-resolution land cover classification is a prerequisite for constructing Earth system models and addressing ecological and resource issues. Advancements in satellite sensor technology have led to an improvement in spatial resolution and wider coverage areas. Nevertheless, the lack of high-resolution labeled data is still a challenge, hindering the largescale application of land cover classification methods. In this paper, we propose a Transformerbased weakly supervised method for cross-resolution land cover classification using outdated data. First, to capture long-range dependencies without missing the fine-grained details of objects, we propose a U-Net-like Transformer based on a reverse difference mechanism (RDM) using dynamic sparse attention. Second, we propose an anti-noise loss calculation (ANLC) module based on optimal transport (OT). Anti-noise loss calculation identifies confident areas (CA) and vague areas (VA) based on the OT matrix, which relieves the impact of noises in outdated land cover products. By introducing a weakly supervised loss with weights and employing unsupervised loss, the RDM-based U-Net-like Transformer was trained. Remote sensing images with 1 m resolution and the corresponding ground-truths of six states in the United States were employed to validate the performance of the proposed method. The experiments utilized outdated land cover products with 30 m resolution from 2013 as training labels, and produced land cover maps with 1 m resolution from 2017. The results show the superiority of the proposed method compared to state-of-the-art methods. The code is available at https://github.com/yu-ni1989/ANLC-Former.
RainDiffusion:When Unsupervised Learning Meets Diffusion Models for Real-world Image Deraining
Jan 23, 2023
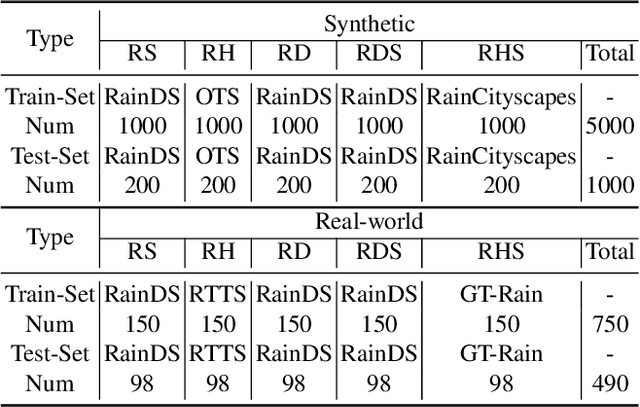
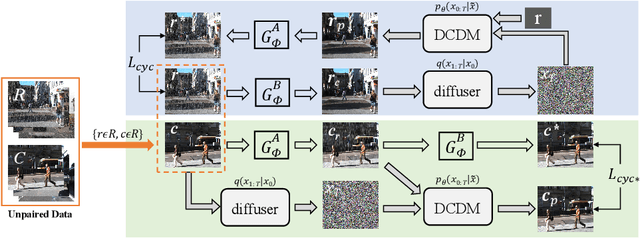
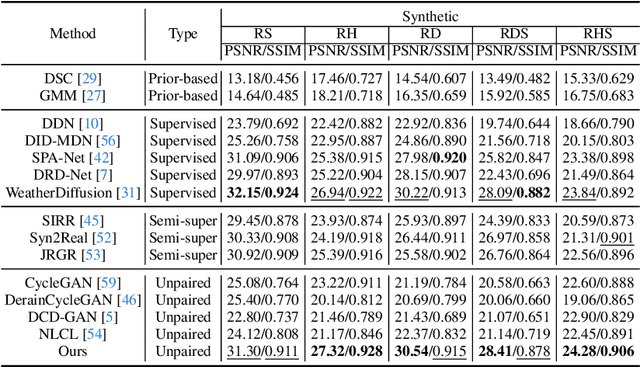
What will happen when unsupervised learning meets diffusion models for real-world image deraining? To answer it, we propose RainDiffusion, the first unsupervised image deraining paradigm based on diffusion models. Beyond the traditional unsupervised wisdom of image deraining, RainDiffusion introduces stable training of unpaired real-world data instead of weakly adversarial training. RainDiffusion consists of two cooperative branches: Non-diffusive Translation Branch (NTB) and Diffusive Translation Branch (DTB). NTB exploits a cycle-consistent architecture to bypass the difficulty in unpaired training of standard diffusion models by generating initial clean/rainy image pairs. DTB leverages two conditional diffusion modules to progressively refine the desired output with initial image pairs and diffusive generative prior, to obtain a better generalization ability of deraining and rain generation. Rain-Diffusion is a non adversarial training paradigm, serving as a new standard bar for real-world image deraining. Extensive experiments confirm the superiority of our RainDiffusion over un/semi-supervised methods and show its competitive advantages over fully-supervised ones.
ImLiDAR: Cross-Sensor Dynamic Message Propagation Network for 3D Object Detection
Nov 17, 2022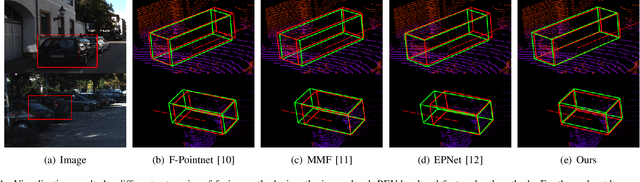
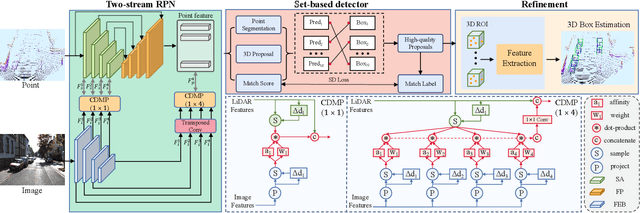
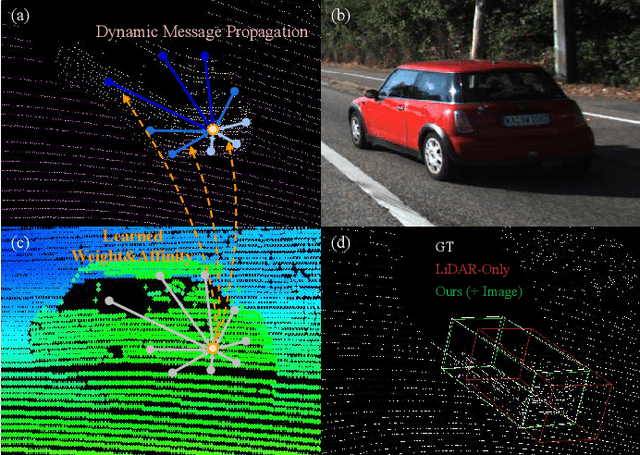
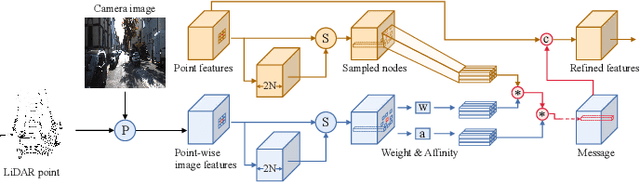
LiDAR and camera, as two different sensors, supply geometric (point clouds) and semantic (RGB images) information of 3D scenes. However, it is still challenging for existing methods to fuse data from the two cross sensors, making them complementary for quality 3D object detection (3OD). We propose ImLiDAR, a new 3OD paradigm to narrow the cross-sensor discrepancies by progressively fusing the multi-scale features of camera Images and LiDAR point clouds. ImLiDAR enables to provide the detection head with cross-sensor yet robustly fused features. To achieve this, two core designs exist in ImLiDAR. First, we propose a cross-sensor dynamic message propagation module to combine the best of the multi-scale image and point features. Second, we raise a direct set prediction problem that allows designing an effective set-based detector to tackle the inconsistency of the classification and localization confidences, and the sensitivity of hand-tuned hyperparameters. Besides, the novel set-based detector can be detachable and easily integrated into various detection networks. Comparisons on both the KITTI and SUN-RGBD datasets show clear visual and numerical improvements of our ImLiDAR over twenty-three state-of-the-art 3OD methods.
PSFormer: Point Transformer for 3D Salient Object Detection
Oct 28, 2022
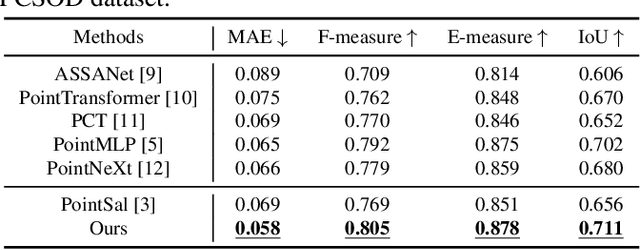
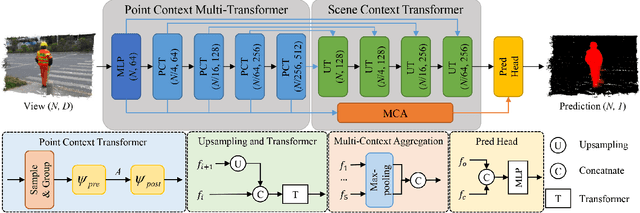
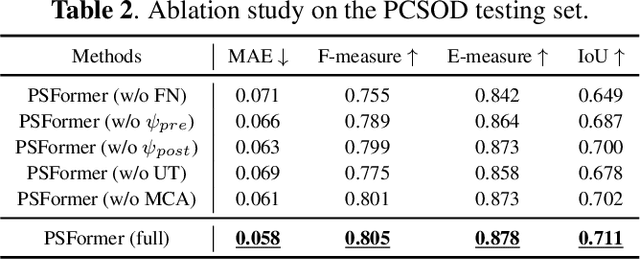
We propose PSFormer, an effective point transformer model for 3D salient object detection. PSFormer is an encoder-decoder network that takes full advantage of transformers to model the contextual information in both multi-scale point- and scene-wise manners. In the encoder, we develop a Point Context Transformer (PCT) module to capture region contextual features at the point level; PCT contains two different transformers to excavate the relationship among points. In the decoder, we develop a Scene Context Transformer (SCT) module to learn context representations at the scene level; SCT contains both Upsampling-and-Transformer blocks and Multi-context Aggregation units to integrate the global semantic and multi-level features from the encoder into the global scene context. Experiments show clear improvements of PSFormer over its competitors and validate that PSFormer is more robust to challenging cases such as small objects, multiple objects, and objects with complex structures.
Semi-MoreGAN: A New Semi-supervised Generative Adversarial Network for Mixture of Rain Removal
Apr 28, 2022

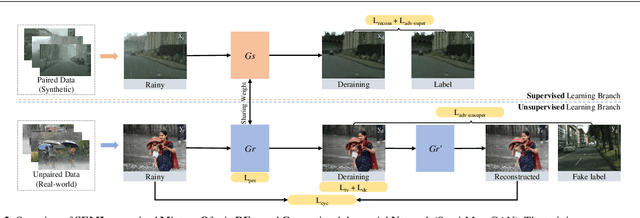
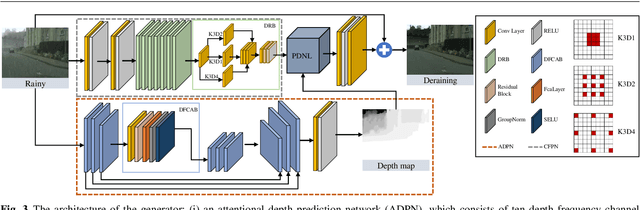
Rain is one of the most common weather which can completely degrade the image quality and interfere with the performance of many computer vision tasks, especially under heavy rain conditions. We observe that: (i) rain is a mixture of rain streaks and rainy haze; (ii) the scene depth determines the intensity of rain streaks and the transformation into the rainy haze; (iii) most existing deraining methods are only trained on synthetic rainy images, and hence generalize poorly to the real-world scenes. Motivated by these observations, we propose a new SEMI-supervised Mixture Of rain REmoval Generative Adversarial Network (Semi-MoreGAN), which consists of four key modules: (I) a novel attentional depth prediction network to provide precise depth estimation; (ii) a context feature prediction network composed of several well-designed detailed residual blocks to produce detailed image context features; (iii) a pyramid depth-guided non-local network to effectively integrate the image context with the depth information, and produce the final rain-free images; and (iv) a comprehensive semi-supervised loss function to make the model not limited to synthetic datasets but generalize smoothly to real-world heavy rainy scenes. Extensive experiments show clear improvements of our approach over twenty representative state-of-the-arts on both synthetic and real-world rainy images.
Semi-DRDNet Semi-supervised Detail-recovery Image Deraining Network via Unpaired Contrastive Learning
Apr 06, 2022
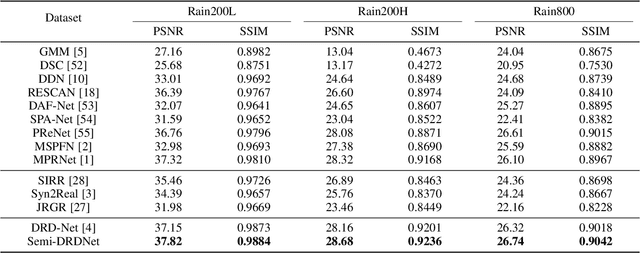
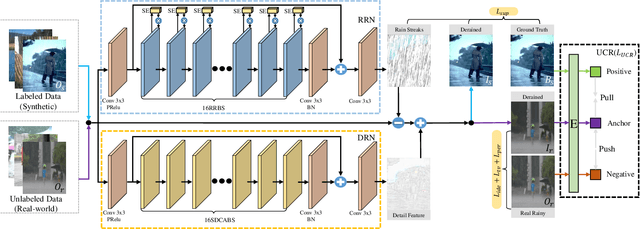

The intricacy of rainy image contents often leads cutting-edge deraining models to image degradation including remnant rain, wrongly-removed details, and distorted appearance. Such degradation is further exacerbated when applying the models trained on synthetic data to real-world rainy images. We raise an intriguing question -- if leveraging both accessible unpaired clean/rainy yet real-world images and additional detail repair guidance, can improve the generalization ability of a deraining model? To answer it, we propose a semi-supervised detail-recovery image deraining network (termed as Semi-DRDNet). Semi-DRDNet consists of three branches: 1) for removing rain streaks without remnants, we present a \textit{squeeze-and-excitation} (SE)-based rain residual network; 2) for encouraging the lost details to return, we construct a \textit{structure detail context aggregation} (SDCAB)-based detail repair network; to our knowledge, this is the first time; and 3) for bridging the domain gap, we develop a novel contrastive regularization network to learn from unpaired positive (clean) and negative (rainy) yet real-world images. As a semi-supervised learning paradigm, Semi-DRDNet operates smoothly on both synthetic and real-world rainy data in terms of deraining robustness and detail accuracy. Comparisons on four datasets show clear visual and numerical improvements of our Semi-DRDNet over thirteen state-of-the-arts.
MBA-RainGAN: Multi-branch Attention Generative Adversarial Network for Mixture of Rain Removal from Single Images
May 23, 2020


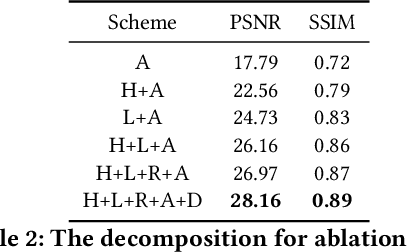
Rain severely hampers the visibility of scene objects when images are captured through glass in heavily rainy days. We observe three intriguing phenomenons that, 1) rain is a mixture of raindrops, rain streaks and rainy haze; 2) the depth from the camera determines the degrees of object visibility, where objects nearby and faraway are visually blocked by rain streaks and rainy haze, respectively; and 3) raindrops on the glass randomly affect the object visibility of the whole image space. We for the first time consider that, the overall visibility of objects is determined by the mixture of rain (MOR). However, existing solutions and established datasets lack full consideration of the MOR. In this work, we first formulate a new rain imaging model; by then, we enrich the popular RainCityscapes by considering raindrops, named RainCityscapes++. Furthermore, we propose a multi-branch attention generative adversarial network (termed an MBA-RainGAN) to fully remove the MOR. The experiment shows clear visual and numerical improvements of our approach over the state-of-the-arts on RainCityscapes++. The code and dataset will be available.