 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-DRDNet Semi-supervised Detail-recovery Image Deraining Network via Unpaired Contrastive Learning
Apr 06, 2022
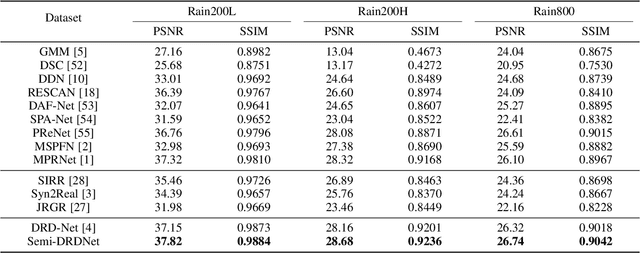
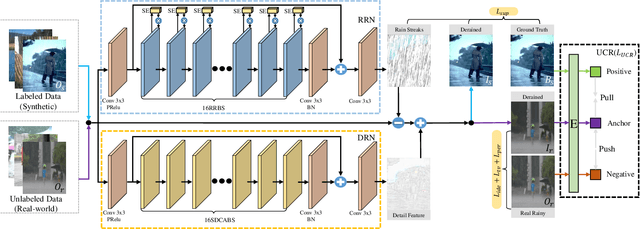

The intricacy of rainy image contents often leads cutting-edge deraining models to image degradation including remnant rain, wrongly-removed details, and distorted appearance. Such degradation is further exacerbated when applying the models trained on synthetic data to real-world rainy images. We raise an intriguing question -- if leveraging both accessible unpaired clean/rainy yet real-world images and additional detail repair guidance, can improve the generalization ability of a deraining model? To answer it, we propose a semi-supervised detail-recovery image deraining network (termed as Semi-DRDNet). Semi-DRDNet consists of three branches: 1) for removing rain streaks without remnants, we present a \textit{squeeze-and-excitation} (SE)-based rain residual network; 2) for encouraging the lost details to return, we construct a \textit{structure detail context aggregation} (SDCAB)-based detail repair network; to our knowledge, this is the first time; and 3) for bridging the domain gap, we develop a novel contrastive regularization network to learn from unpaired positive (clean) and negative (rainy) yet real-world images. As a semi-supervised learning paradigm, Semi-DRDNet operates smoothly on both synthetic and real-world rainy data in terms of deraining robustness and detail accuracy. Comparisons on four datasets show clear visual and numerical improvements of our Semi-DRDNet over thirteen state-of-the-arts.
Direction-aware Feature-level Frequency Decomposition for Single Image Deraining
Jun 15, 2021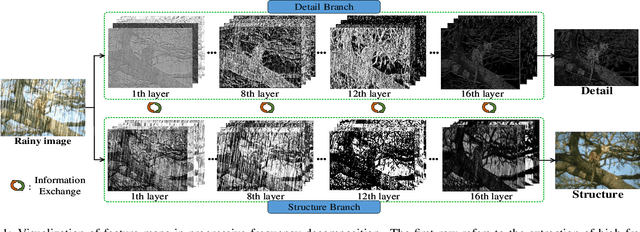
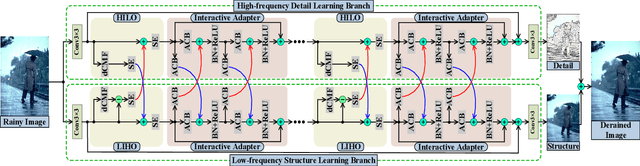
We present a novel direction-aware feature-level frequency decomposition network for single image deraining. Compared with existing solutions, the proposed network has three compelling characteristics. First, unlike previous algorithms, we propose to perform frequency decomposition at feature-level instead of image-level, allowing both low-frequency maps containing structures and high-frequency maps containing details to be continuously refined during the training procedure. Second, we further establish communication channels between low-frequency maps and high-frequency maps to interactively capture structures from high-frequency maps and add them back to low-frequency maps and, simultaneously, extract details from low-frequency maps and send them back to high-frequency maps, thereby removing rain streaks while preserving more delicate features in the input image. Third, different from existing algorithms using convolutional filters consistent in all directions, we propose a direction-aware filter to capture the direction of rain streaks in order to more effectively and thoroughly purge the input images of rain streaks. We extensively evaluate the proposed approach in three representative datasets and experimental results corroborate our approach consistently outperforms state-of-the-art deraining algorithms.
MBA-RainGAN: Multi-branch Attention Generative Adversarial Network for Mixture of Rain Removal from Single Images
May 23, 2020


Rain severely hampers the visibility of scene objects when images are captured through glass in heavily rainy days. We observe three intriguing phenomenons that, 1) rain is a mixture of raindrops, rain streaks and rainy haze; 2) the depth from the camera determines the degrees of object visibility, where objects nearby and faraway are visually blocked by rain streaks and rainy haze, respectively; and 3) raindrops on the glass randomly affect the object visibility of the whole image space. We for the first time consider that, the overall visibility of objects is determined by the mixture of rain (MOR). However, existing solutions and established datasets lack full consideration of the MOR. In this work, we first formulate a new rain imaging model; by then, we enrich the popular RainCityscapes by considering raindrops, named RainCityscapes++. Furthermore, we propose a multi-branch attention generative adversarial network (termed an MBA-RainGAN) to fully remove the MOR. The experiment shows clear visual and numerical improvements of our approach over the state-of-the-arts on RainCityscapes++. The code and dataset will be available.
DRD-Net: Detail-recovery Image Deraining via Context Aggregation Networks
Aug 28, 2019

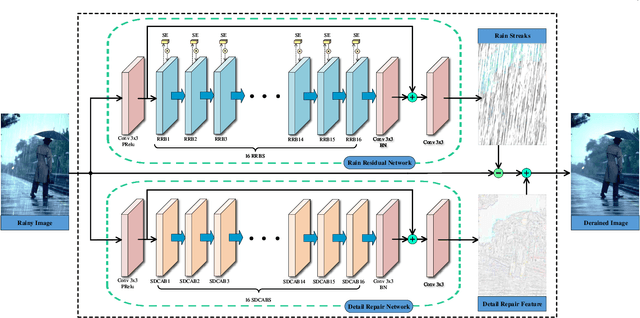
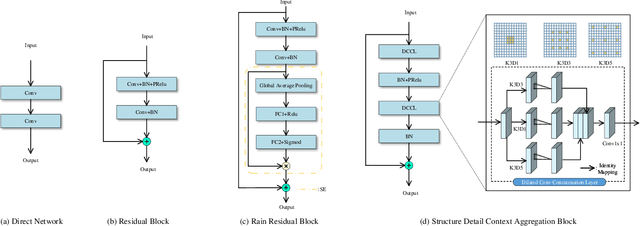
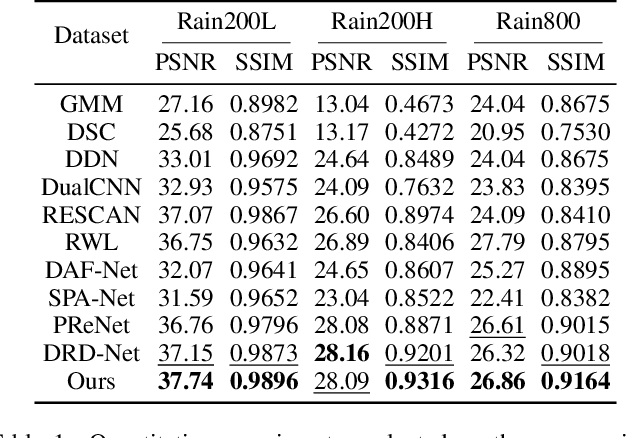
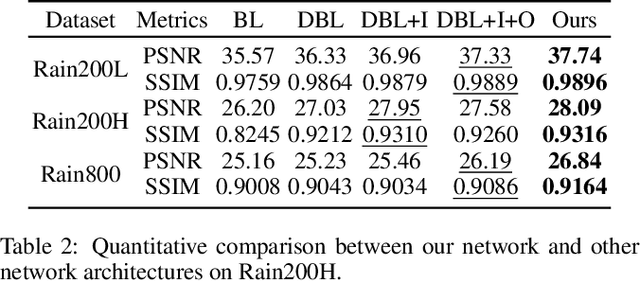
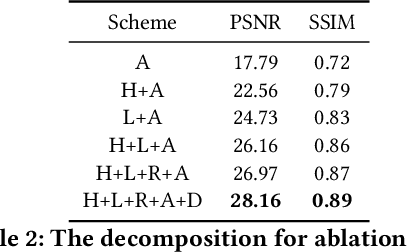
Image deraining is a fundamental, yet not well-solved problem in computer vision and graphics. The traditional image deraining approaches commonly behave ineffectively in medium and heavy rain removal, while the learning-based ones lead to image degradations such as the loss of image details, halo artifacts and/or color distortion. Unlike existing image deraining approaches that lack the detail-recovery mechanism, we propose an end-to-end detail-recovery image deraining network (termed a DRD-Net) for single images. We for the first time introduce two sub-networks with a comprehensive loss function which synergize to derain and recover the lost details caused by deraining. We have three key contributions. First, we present a rain residual network to remove rain streaks from the rainy images, which combines the squeeze-and-excitation (SE) operation with residual blocks to make full advantage of spatial contextual information. Second, we design a new connection style block, named structure detail context aggregation block (SDCAB), which aggregates context feature information and has a large reception field. Third, benefiting from the SDCAB, we construct a detail repair network to encourage the lost details to return for eliminating image degradations. We have validated our approach on four recognized datasets (three synthetic and one real-world). Both quantitative and qualitative comparisons show that our approach outperforms the state-of-the-art deraining methods in terms of the deraining robustness and detail accuracy. The source code has been available for public evaluation and use on GitHub.
Convolutional Neural Network with Median Layers for Denoising Salt-and-Pepper Contaminations
Aug 18, 2019
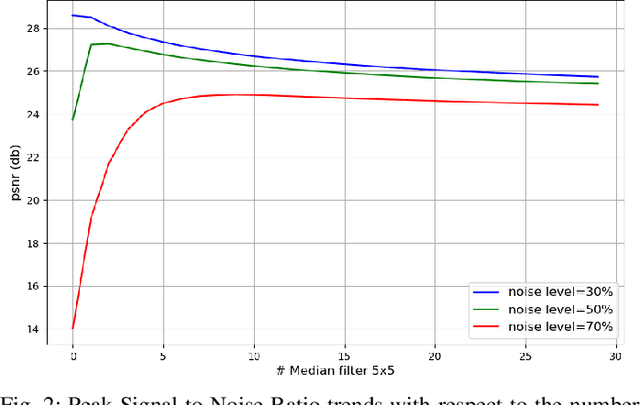
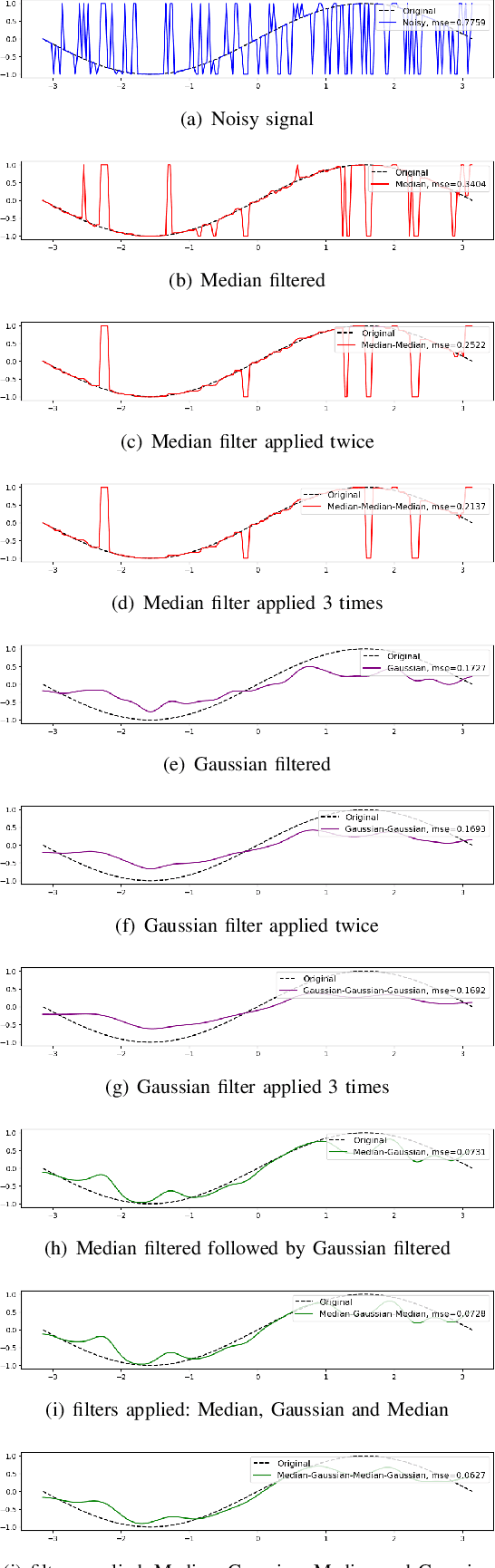
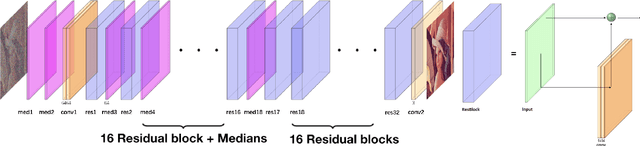
We propose a deep fully convolutional neural network with a new type of layer, named median layer, to restore images contaminated by the salt-and-pepper (s&p) noise. A median layer simply performs median filtering on all feature channels. By adding this kind of layer into some widely used fully convolutional deep neural networks, we develop an end-to-end network that removes the extremely high-level s&p noise without performing any non-trivial preprocessing tasks, which is different from all the existing literature in s&p noise removal. Experiments show that inserting median layers into a simple fully-convolutional network with the L2 loss significantly boosts the signal-to-noise ratio. Quantitative comparisons testify that our network outperforms the state-of-the-art methods with a limited amount of training data. The source code has been released for public evaluation and use (https://github.com/llmpass/medianDenoise).