 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireAct: Toward Language Agent Fine-tuning
Oct 09, 2023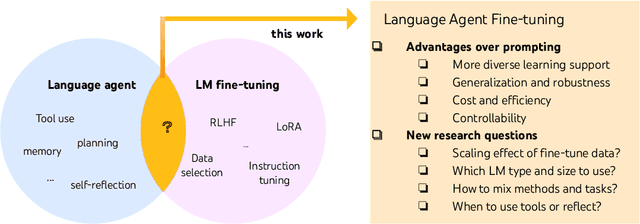
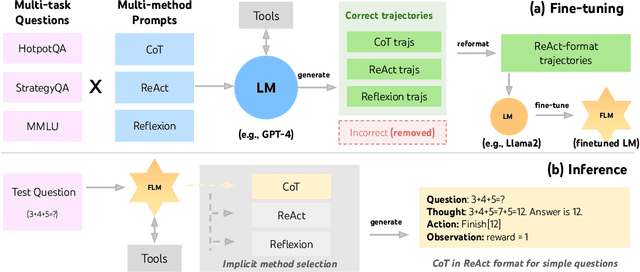

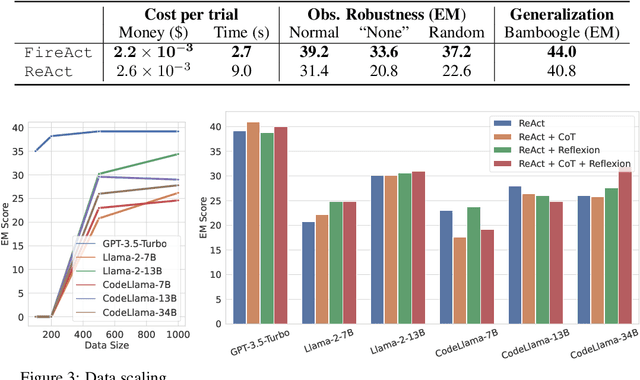
Recent efforts have augmented language models (LMs) with external tools or environments, leading to the development of language agents that can reason and act. However, most of these agents rely on few-shot prompting techniques with off-the-shelf LMs. In this paper, we investigate and argue for the overlooked direction of fine-tuning LMs to obtain language agents. Using a setup of question answering (QA) with a Google search API, we explore a variety of base LMs, prompting methods, fine-tuning data, and QA tasks, and find language agents are consistently improved after fine-tuning their backbone LMs. For example, fine-tuning Llama2-7B with 500 agent trajectories generated by GPT-4 leads to a 77% HotpotQA performance increase. Furthermore, we propose FireAct, a novel approach to fine-tuning LMs with trajectories from multiple tasks and prompting methods, and show having more diverse fine-tuning data can further improve agents. Along with other findings regarding scaling effects, robustness, generalization, efficiency and cost, our work establishes comprehensive benefits of fine-tuning LMs for agents, and provides an initial set of experimental designs, insights, as well as open questions toward language agent fine-tuning.
PSFormer: Point Transformer for 3D Salient Object Detection
Oct 28, 2022
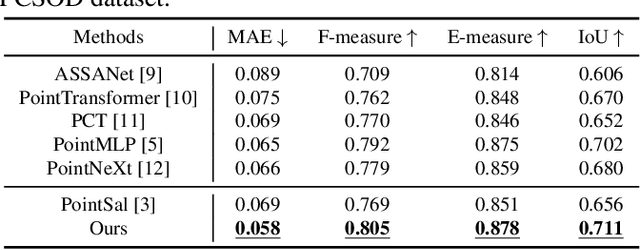
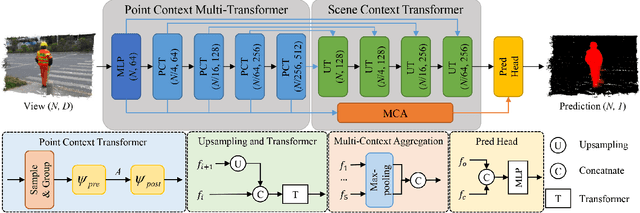
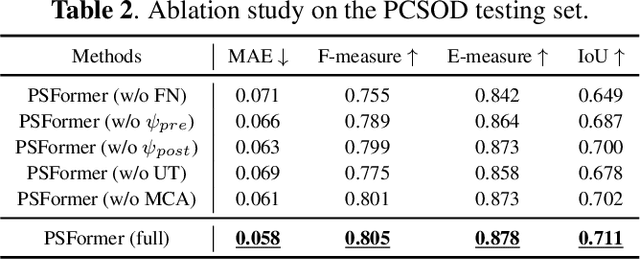
We propose PSFormer, an effective point transformer model for 3D salient object detection. PSFormer is an encoder-decoder network that takes full advantage of transformers to model the contextual information in both multi-scale point- and scene-wise manners. In the encoder, we develop a Point Context Transformer (PCT) module to capture region contextual features at the point level; PCT contains two different transformers to excavate the relationship among points. In the decoder, we develop a Scene Context Transformer (SCT) module to learn context representations at the scene level; SCT contains both Upsampling-and-Transformer blocks and Multi-context Aggregation units to integrate the global semantic and multi-level features from the encoder into the global scene context. Experiments show clear improvements of PSFormer over its competitors and validate that PSFormer is more robust to challenging cases such as small objects, multiple objects, and objects with complex structures.
3DLG-Detector: 3D Object Detection via Simultaneous Local-Global Feature Learning
Aug 31, 2022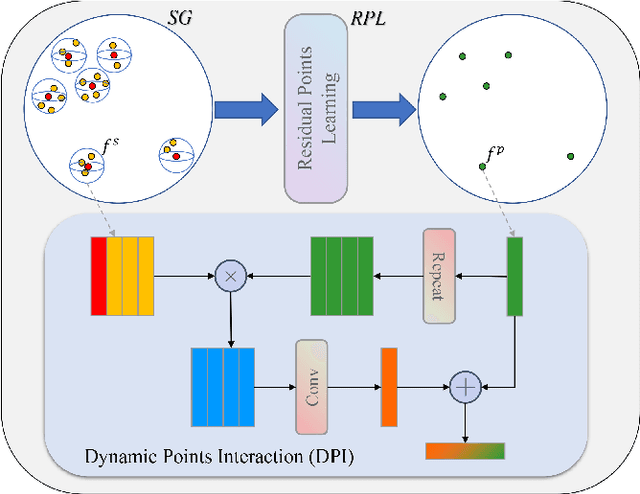
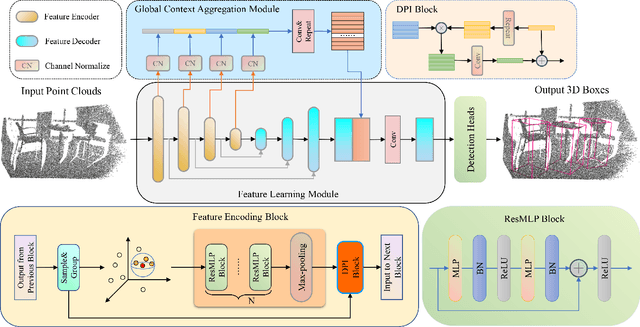
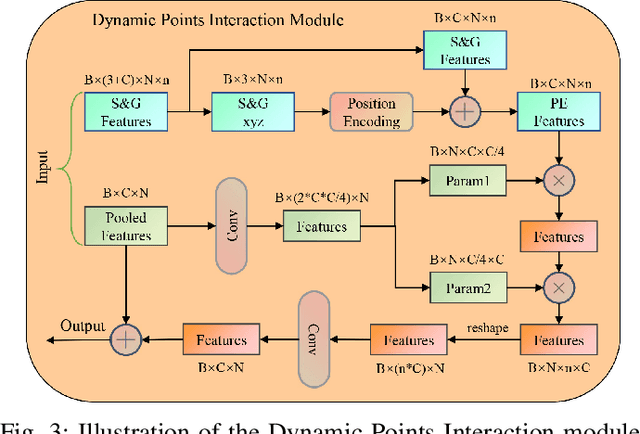

Capturing both local and global features of irregular point clouds is essential to 3D object detection (3OD). However, mainstream 3D detectors, e.g., VoteNet and its variants, either abandon considerable local features during pooling operations or ignore many global features in the whole scene context. This paper explores new modules to simultaneously learn local-global features of scene point clouds that serve 3OD positively. To this end, we propose an effective 3OD network via simultaneous local-global feature learning (dubbed 3DLG-Detector). 3DLG-Detector has two key contributions. First, it develops a Dynamic Points Interaction (DPI) module that preserves effective local features during pooling. Besides, DPI is detachable and can be incorporated into existing 3OD networks to boost their performance. Second, it develops a Global Context Aggregation module to aggregate multi-scale features from different layers of the encoder to achieve scene context-awareness. Our method shows improvements over thirteen competitors in terms of detection accuracy and robustness on both the SUN RGB-D and ScanNet datasets. Source code will be available upon publication.
Dynamic Message Propagation Network for RGB-D Salient Object Detection
Jun 20, 2022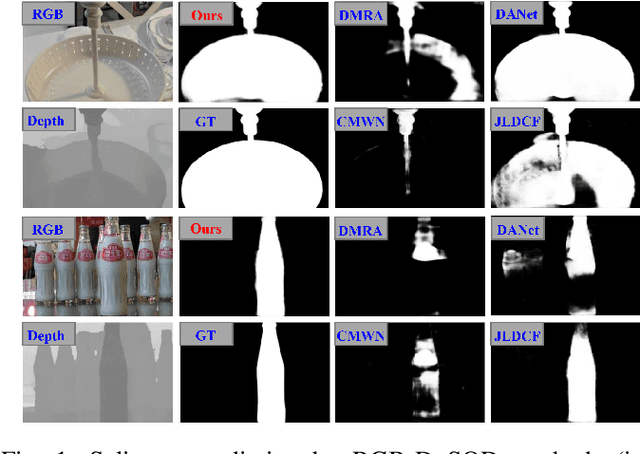
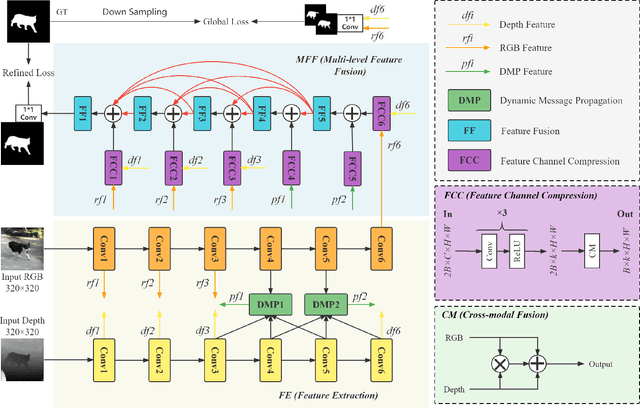
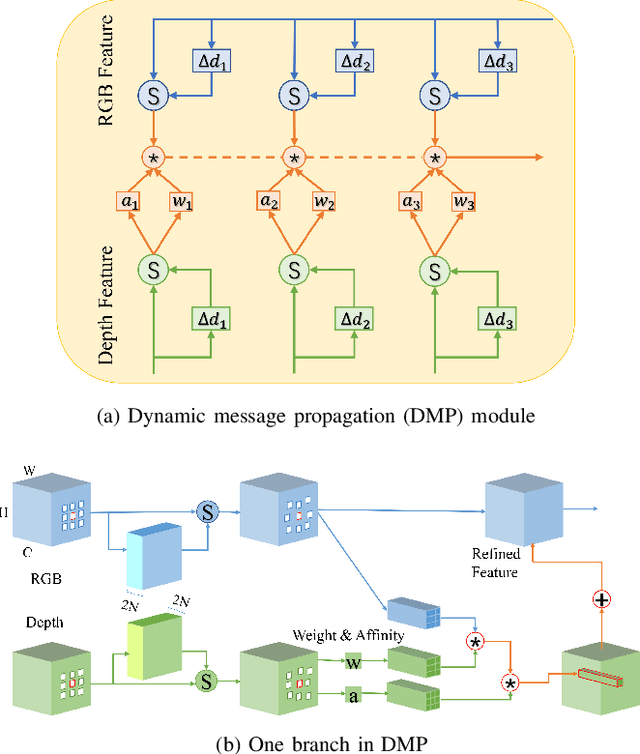
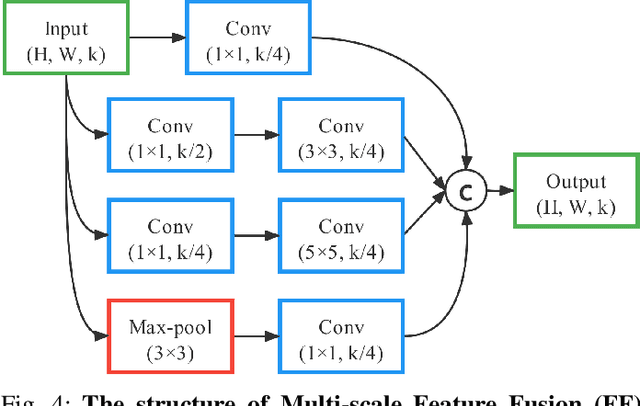
This paper presents a novel deep neural network framework for RGB-D salient object detection by controlling the message passing between the RGB images and depth maps on the feature level and exploring the long-range semantic contexts and geometric information on both RGB and depth features to infer salient objects. To achieve this, we formulate a dynamic message propagation (DMP) module with the graph neural networks and deformable convolutions to dynamically learn the context information and to automatically predict filter weights and affinity matrices for message propagation control. We further embed this module into a Siamese-based network to process the RGB image and depth map respectively and design a multi-level feature fusion (MFF) module to explore the cross-level information between the refined RGB and depth features. Compared with 17 state-of-the-art methods on six benchmark datasets for RGB-D salient object detection, experimental results show that our method outperforms all the others, both quantitatively and visually.
Video Enhancement with Task-Oriented Flow
Nov 24, 2017
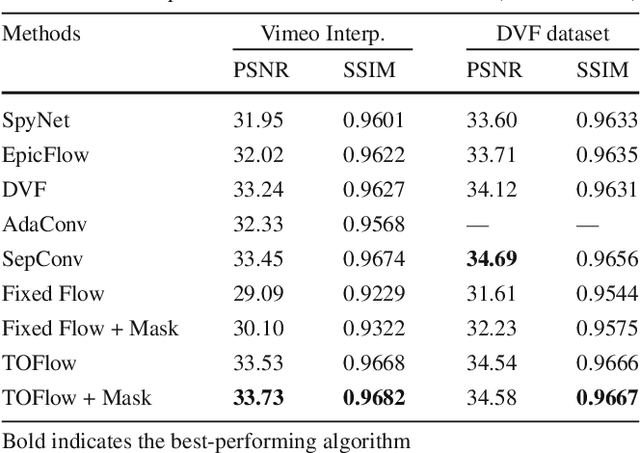
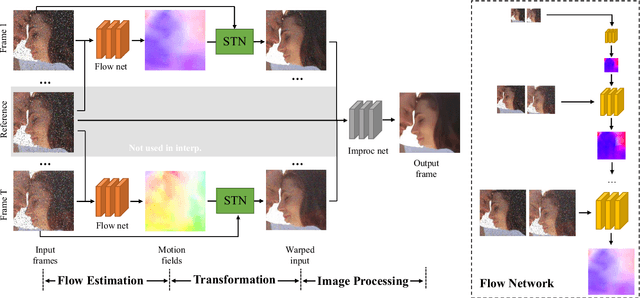
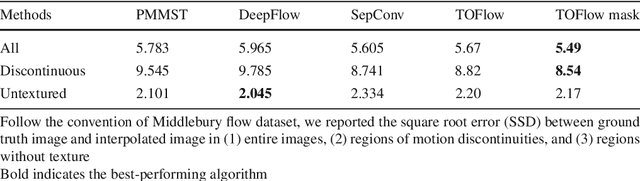
Many video processing algorithms rely on optical flow to register different frames within a sequence. However, a precise estimation of optical flow is often neither tractable nor optimal for a particular task. In this paper, we propose task-oriented flow (TOFlow), a flow representation tailored for specific video processing tasks. We design a neural network with a motion estimation component and a video processing component. These two parts can be jointly trained in a self-supervised manner to facilitate learning of the proposed TOFlow. We demonstrate that TOFlow outperforms the traditional optical flow on three different video processing tasks: frame interpolation, video denoising/deblocking, and video super-resolution. We also introduce Vimeo-90K, a large-scale, high-quality video dataset for video processing to better evaluate the proposed algorithm.
2D SLAM Quality Evaluation Methods
Aug 08, 2017

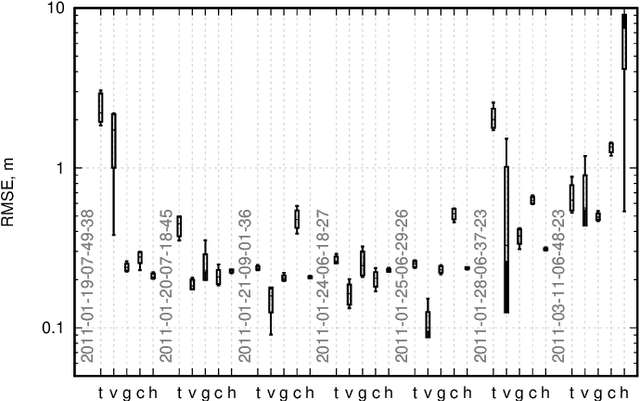
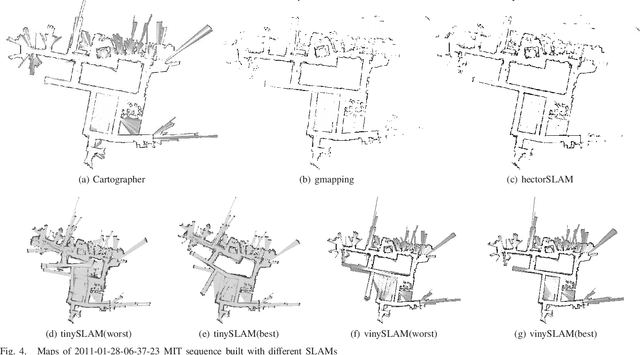
SLAM (Simultaneous Localization and mapping) is one of the most challenging problems for mobile platforms and there is a huge amount of modern SLAM algorithms. The choice of the algorithm that might be used in every particular problem requires prior knowledge about advantages and disadvantages of each algorithm. This paper presents the approach for comparison of SLAM algorithms that allows to find the most accurate one. The accent of research is made on 2D SLAM algorithms and the focus of analysis is 2D map that is built after algorithm performance. Three metrics for evaluation of maps are presented in this paper