 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointGame: Geometrically and Adaptively Masked Auto-Encoder on Point Clouds
Mar 23, 2023



Self-supervised learning is attracting large attention in point cloud understanding. However, exploring discriminative and transferable features still remains challenging due to their nature of irregularity and sparsity. We propose a geometrically and adaptively masked auto-encoder for self-supervised learning on point clouds, termed \textit{PointGame}. PointGame contains two core components: GATE and EAT. GATE stands for the geometrical and adaptive token embedding module; it not only absorbs the conventional wisdom of geometric descriptors that captures the surface shape effectively, but also exploits adaptive saliency to focus on the salient part of a point cloud. EAT stands for the external attention-based Transformer encoder with linear computational complexity, which increases the efficiency of the whole pipeline. Unlike cutting-edge unsupervised learning models, PointGame leverages geometric descriptors to perceive surface shapes and adaptively mines discriminative features from training data. PointGame showcases clear advantages over its competitors on various downstream tasks under both global and local fine-tuning strategies. The code and pre-trained models will be publicly available.
UTOPIC: Uncertainty-aware Overlap Prediction Network for Partial Point Cloud Registration
Aug 12, 2022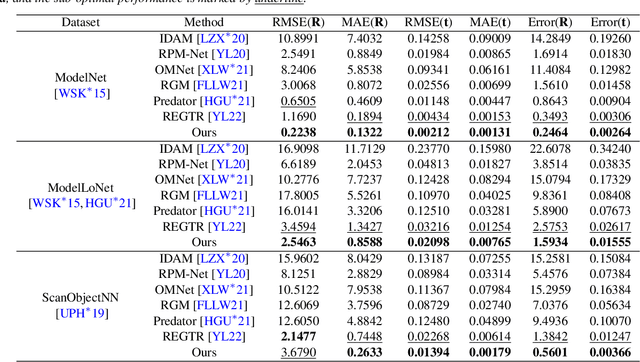
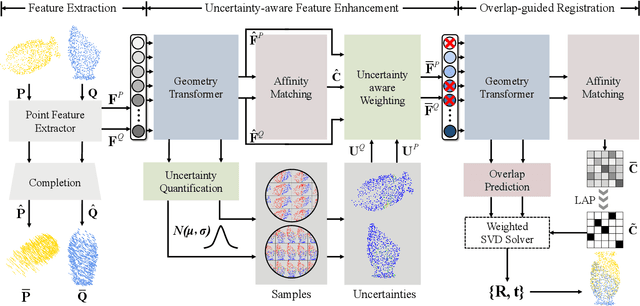
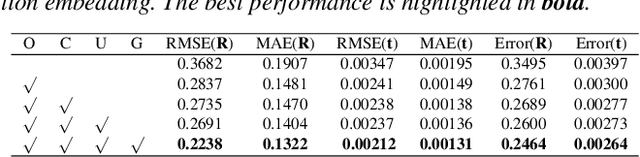
High-confidence overlap prediction and accurate correspondences are critical for cutting-edge models to align paired point clouds in a partial-to-partial manner. However, there inherently exists uncertainty between the overlapping and non-overlapping regions, which has always been neglected and significantly affects the registration performance. Beyond the current wisdom, we propose a novel uncertainty-aware overlap prediction network, dubbed UTOPIC, to tackle the ambiguous overlap prediction problem; to our knowledge, this is the first to explicitly introduce overlap uncertainty to point cloud registration. Moreover, we induce the feature extractor to implicitly perceive the shape knowledge through a completion decoder, and present a geometric relation embedding for Transformer to obtain transformation-invariant geometry-aware feature representations. With the merits of more reliable overlap scores and more precise dense correspondences, UTOPIC can achieve stable and accurate registration results, even for the inputs with limited overlapping areas. Extensive quantitative and qualitative experiments on synthetic and real benchmarks demonstrate the superiority of our approach over state-of-the-art methods.
Dynamic Message Propagation Network for RGB-D Salient Object Detection
Jun 20, 2022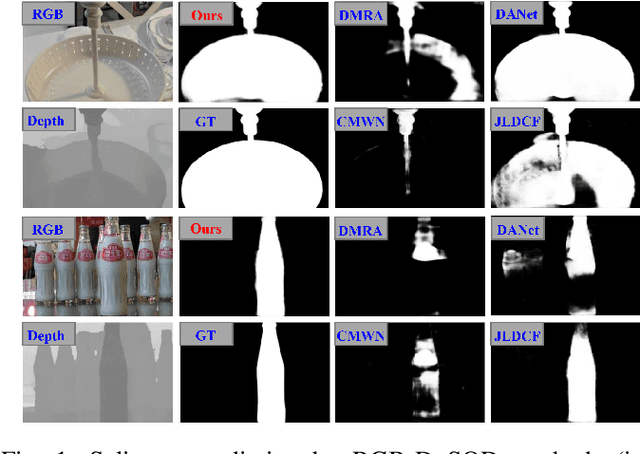
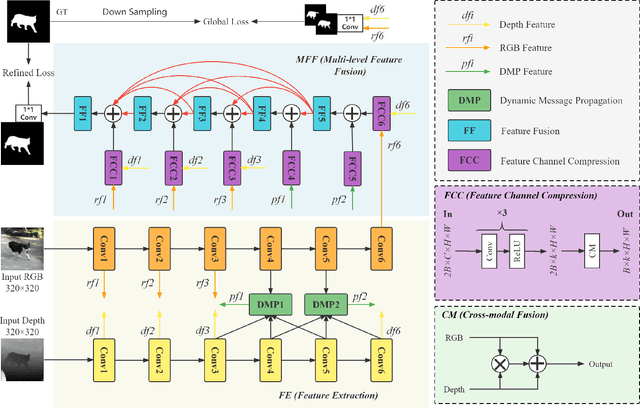
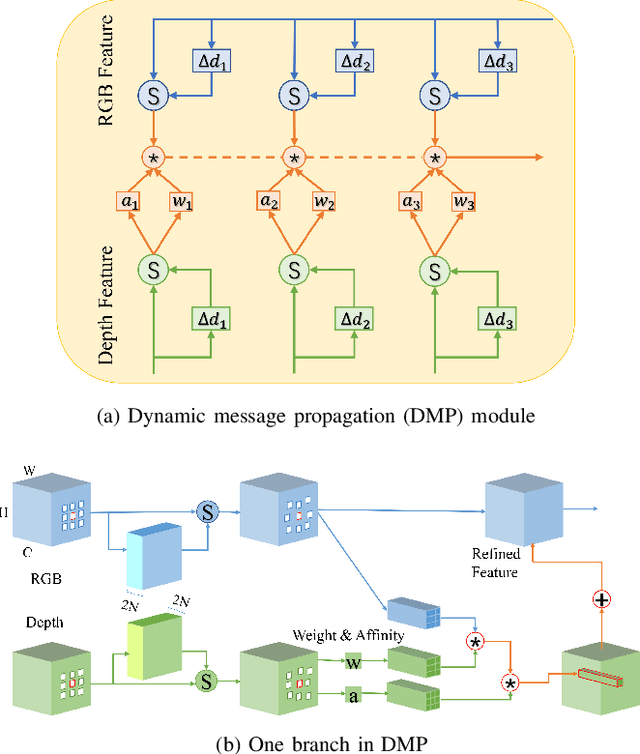
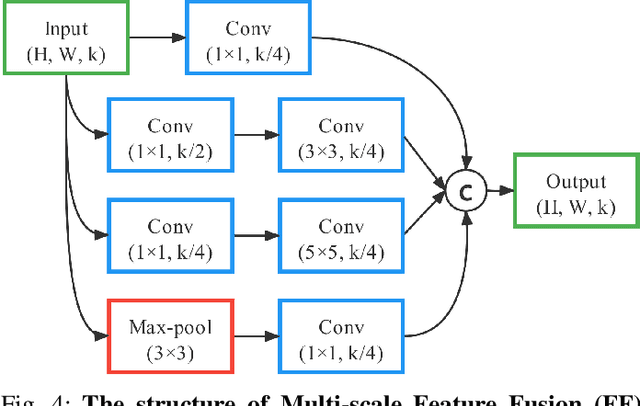
This paper presents a novel deep neural network framework for RGB-D salient object detection by controlling the message passing between the RGB images and depth maps on the feature level and exploring the long-range semantic contexts and geometric information on both RGB and depth features to infer salient objects. To achieve this, we formulate a dynamic message propagation (DMP) module with the graph neural networks and deformable convolutions to dynamically learn the context information and to automatically predict filter weights and affinity matrices for message propagation control. We further embed this module into a Siamese-based network to process the RGB image and depth map respectively and design a multi-level feature fusion (MFF) module to explore the cross-level information between the refined RGB and depth features. Compared with 17 state-of-the-art methods on six benchmark datasets for RGB-D salient object detection, experimental results show that our method outperforms all the others, both quantitatively and visually.
AGConv: Adaptive Graph Convolution on 3D Point Clouds
Jun 09, 2022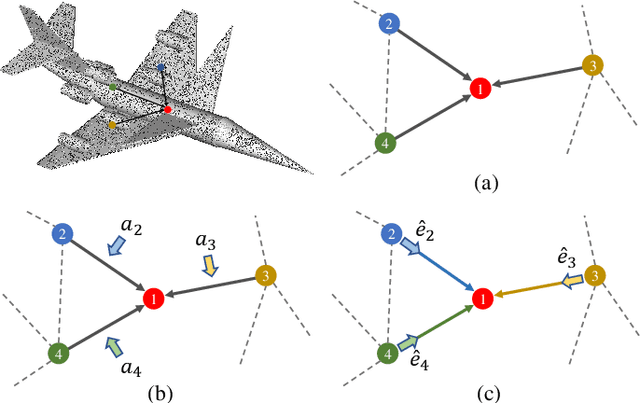


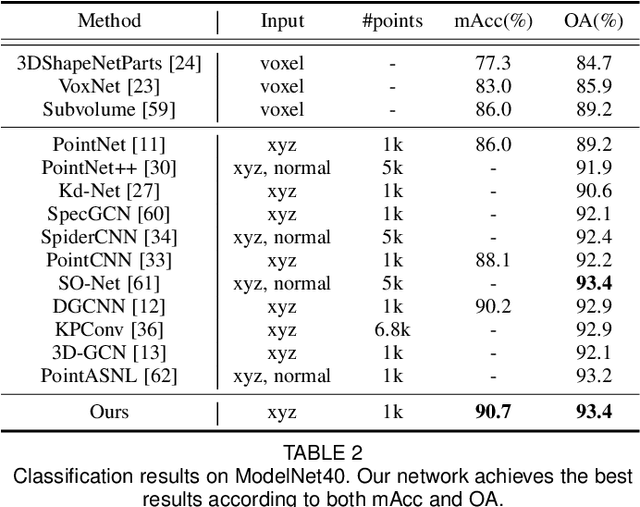
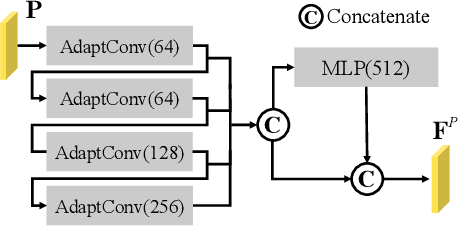
Convolution on 3D point clouds is widely researched yet far from perfect in geometric deep learning. The traditional wisdom of convolution characterises feature correspondences indistinguishably among 3D points, arising an intrinsic limitation of poor distinctive feature learning. In this paper, we propose Adaptive Graph Convolution (AGConv) for wide applications of point cloud analysis. AGConv generates adaptive kernels for points according to their dynamically learned features. Compared with the solution of using fixed/isotropic kernels, AGConv improves the flexibility of point cloud convolutions, effectively and precisely capturing the diverse relations between points from different semantic parts. Unlike the popular attentional weight schemes, AGConv implements the adaptiveness inside the convolution operation instead of simply assigning different weights to the neighboring points. Extensive evaluations clearly show that our method outperforms state-of-the-arts of point cloud classification and segmentation on various benchmark datasets.Meanwhile, AGConv can flexibly serve more point cloud analysis approaches to boost their performance. To validate its flexibility and effectiveness, we explore AGConv-based paradigms of completion, denoising, upsampling, registration and circle extraction, which are comparable or even superior to their competitors. Our code is available at https://github.com/hrzhou2/AdaptConv-master.