 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-BERT for Point Cloud Pretraining
Dec 08, 2023



Introducing BERT into cross-modal settings raises difficulties in its optimization for handling multiple modalities. Both the BERT architecture and training objective need to be adapted to incorporate and model information from different modalities. In this paper, we address these challenges by exploring the implicit semantic and geometric correlations between 2D and 3D data of the same objects/scenes. We propose a new cross-modal BERT-style self-supervised learning paradigm, called Cross-BERT. To facilitate pretraining for irregular and sparse point clouds, we design two self-supervised tasks to boost cross-modal interaction. The first task, referred to as Point-Image Alignment, aims to align features between unimodal and cross-modal representations to capture the correspondences between the 2D and 3D modalities. The second task, termed Masked Cross-modal Modeling, further improves mask modeling of BERT by incorporating high-dimensional semantic information obtained by cross-modal interaction. By performing cross-modal interaction, Cross-BERT can smoothly reconstruct the masked tokens during pretraining, leading to notable performance enhancements for downstream tasks. Through empirical evaluation, we demonstrate that Cross-BERT outperforms existing state-of-the-art methods in 3D downstream applications. Our work highlights the effectiveness of leveraging cross-modal 2D knowledge to strengthen 3D point cloud representation and the transferable capability of BERT across modalities.
PointGame: Geometrically and Adaptively Masked Auto-Encoder on Point Clouds
Mar 23, 2023



Self-supervised learning is attracting large attention in point cloud understanding. However, exploring discriminative and transferable features still remains challenging due to their nature of irregularity and sparsity. We propose a geometrically and adaptively masked auto-encoder for self-supervised learning on point clouds, termed \textit{PointGame}. PointGame contains two core components: GATE and EAT. GATE stands for the geometrical and adaptive token embedding module; it not only absorbs the conventional wisdom of geometric descriptors that captures the surface shape effectively, but also exploits adaptive saliency to focus on the salient part of a point cloud. EAT stands for the external attention-based Transformer encoder with linear computational complexity, which increases the efficiency of the whole pipeline. Unlike cutting-edge unsupervised learning models, PointGame leverages geometric descriptors to perceive surface shapes and adaptively mines discriminative features from training data. PointGame showcases clear advantages over its competitors on various downstream tasks under both global and local fine-tuning strategies. The code and pre-trained models will be publicly available.
GeoGCN: Geometric Dual-domain Graph Convolution Network for Point Cloud Denoising
Oct 28, 2022We propose GeoGCN, a novel geometric dual-domain graph convolution network for point cloud denoising (PCD). Beyond the traditional wisdom of PCD, to fully exploit the geometric information of point clouds, we define two kinds of surface normals, one is called Real Normal (RN), and the other is Virtual Normal (VN). RN preserves the local details of noisy point clouds while VN avoids the global shape shrinkage during denoising. GeoGCN is a new PCD paradigm that, 1) first regresses point positions by spatialbased GCN with the help of VNs, 2) then estimates initial RNs by performing Principal Component Analysis on the regressed points, and 3) finally regresses fine RNs by normalbased GCN. Unlike existing PCD methods, GeoGCN not only exploits two kinds of geometry expertise (i.e., RN and VN) but also benefits from training data. Experiments validate that GeoGCN outperforms SOTAs in terms of both noise-robustness and local-and-global feature preservation.
LBF:Learnable Bilateral Filter For Point Cloud Denoising
Oct 28, 2022



Bilateral filter (BF) is a fast, lightweight and effective tool for image denoising and well extended to point cloud denoising. However, it often involves continual yet manual parameter adjustment; this inconvenience discounts the efficiency and user experience to obtain satisfied denoising results. We propose LBF, an end-to-end learnable bilateral filtering network for point cloud denoising; to our knowledge, this is the first time. Unlike the conventional BF and its variants that receive the same parameters for a whole point cloud, LBF learns adaptive parameters for each point according its geometric characteristic (e.g., corner, edge, plane), avoiding remnant noise, wrongly-removed geometric details, and distorted shapes. Besides the learnable paradigm of BF, we have two cores to facilitate LBF. First, different from the local BF, LBF possesses a global-scale feature perception ability by exploiting multi-scale patches of each point. Second, LBF formulates a geometry-aware bi-directional projection loss, leading the denoising results to being faithful to their underlying surfaces. Users can apply our LBF without any laborious parameter tuning to achieve the optimal denoising results. Experiments show clear improvements of LBF over its competitors on both synthetic and real-scanned datasets.
ImLoveNet: Misaligned Image-supported Registration Network for Low-overlap Point Cloud Pairs
Jul 02, 2022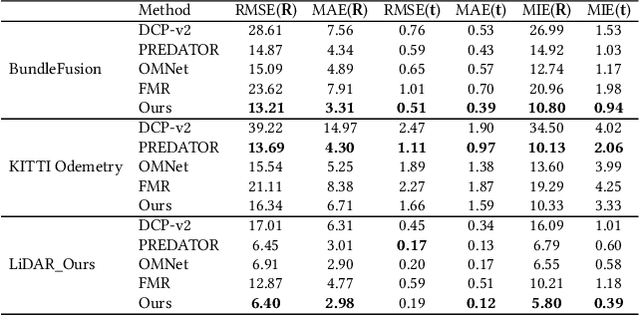
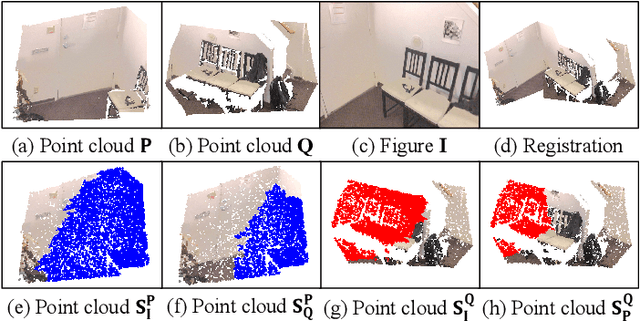
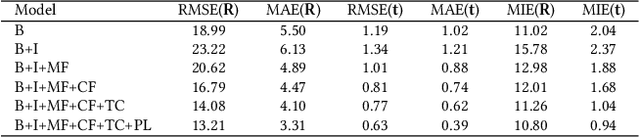
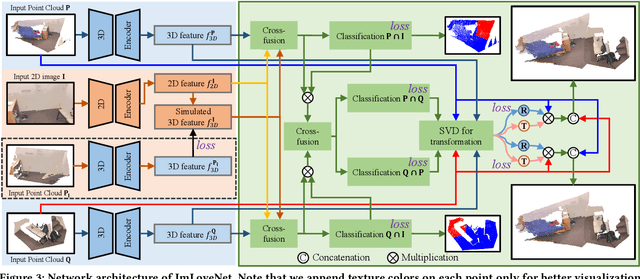
Low-overlap regions between paired point clouds make the captured features very low-confidence, leading cutting edge models to point cloud registration with poor quality. Beyond the traditional wisdom, we raise an intriguing question: Is it possible to exploit an intermediate yet misaligned image between two low-overlap point clouds to enhance the performance of cutting-edge registration models? To answer it, we propose a misaligned image supported registration network for low-overlap point cloud pairs, dubbed ImLoveNet. ImLoveNet first learns triple deep features across different modalities and then exports these features to a two-stage classifier, for progressively obtaining the high-confidence overlap region between the two point clouds. Therefore, soft correspondences are well established on the predicted overlap region, resulting in accurate rigid transformations for registration. ImLoveNet is simple to implement yet effective, since 1) the misaligned image provides clearer overlap information for the two low-overlap point clouds to better locate overlap parts; 2) it contains certain geometry knowledge to extract better deep features; and 3) it does not require the extrinsic parameters of the imaging device with respect to the reference frame of the 3D point cloud. Extensive qualitative and quantitative evaluations on different kinds of benchmarks demonstrate the effectiveness and superiority of our ImLoveNet over state-of-the-art approaches.
AGConv: Adaptive Graph Convolution on 3D Point Clouds
Jun 09, 2022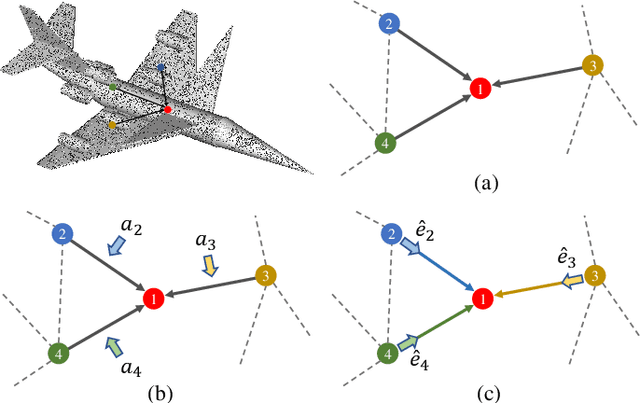


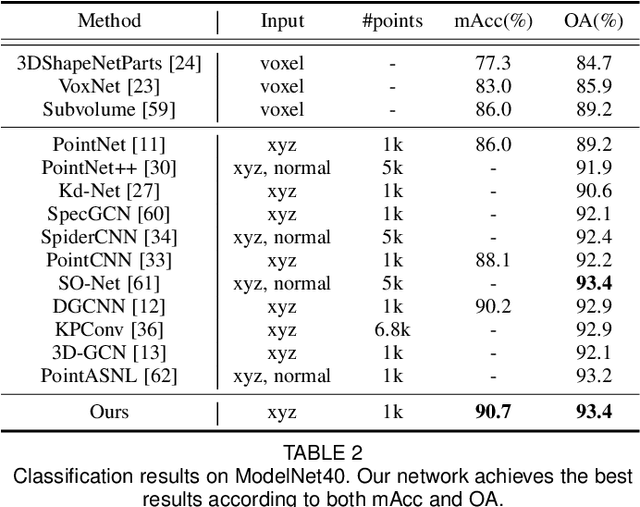
Convolution on 3D point clouds is widely researched yet far from perfect in geometric deep learning. The traditional wisdom of convolution characterises feature correspondences indistinguishably among 3D points, arising an intrinsic limitation of poor distinctive feature learning. In this paper, we propose Adaptive Graph Convolution (AGConv) for wide applications of point cloud analysis. AGConv generates adaptive kernels for points according to their dynamically learned features. Compared with the solution of using fixed/isotropic kernels, AGConv improves the flexibility of point cloud convolutions, effectively and precisely capturing the diverse relations between points from different semantic parts. Unlike the popular attentional weight schemes, AGConv implements the adaptiveness inside the convolution operation instead of simply assigning different weights to the neighboring points. Extensive evaluations clearly show that our method outperforms state-of-the-arts of point cloud classification and segmentation on various benchmark datasets.Meanwhile, AGConv can flexibly serve more point cloud analysis approaches to boost their performance. To validate its flexibility and effectiveness, we explore AGConv-based paradigms of completion, denoising, upsampling, registration and circle extraction, which are comparable or even superior to their competitors. Our code is available at https://github.com/hrzhou2/AdaptConv-master.
Deep Algebraic Fitting for Multiple Circle Primitives Extraction from Raw Point Clouds
Apr 02, 2022

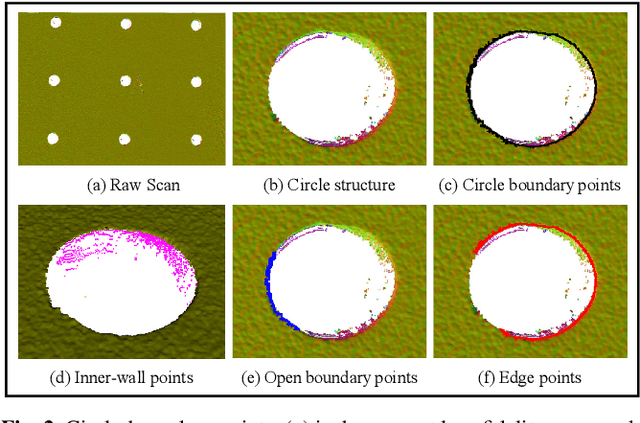

The shape of circle is one of fundamental geometric primitives of man-made engineering objects. Thus, extraction of circles from scanned point clouds is a quite important task in 3D geometry data processing. However, existing circle extraction methods either are sensitive to the quality of raw point clouds when classifying circle-boundary points, or require well-designed fitting functions when regressing circle parameters. To relieve the challenges, we propose an end-to-end Point Cloud Circle Algebraic Fitting Network (Circle-Net) based on a synergy of deep circle-boundary point feature learning and weighted algebraic fitting. First, we design a circle-boundary learning module, which considers local and global neighboring contexts of each point, to detect all potential circle-boundary points. Second, we develop a deep feature based circle parameter learning module for weighted algebraic fitting, without designing any weight metric, to avoid the influence of outliers during fitting. Unlike most of the cutting-edge circle extraction wisdoms, the proposed classification-and-fitting modules are originally co-trained with a comprehensive loss to enhance the quality of extracted circles.Comparisons on the established dataset and real-scanned point clouds exhibit clear improvements of Circle-Net over SOTAs in terms of both noise-robustness and extraction accuracy. We will release our code, model, and data for both training and evaluation on GitHub upon publication.