 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBraveGuard: From Open-World Threats to Safer Computer-Use Agents
May 31, 2026Computer-use agents extend language models from text generation to sustained interaction with files, terminals, browsers, and external tools. This shift creates safety risks that are difficult to detect from isolated prompts or final responses, because harm often emerges only through multi-step execution traces whose individual actions appear locally benign. We introduce BraveGuard, a self-evolving defense framework for training guard models from open-world threat signals and realistic agent trajectories. BraveGuard mines recent research sources to identify emerging risks and attack patterns, instantiates them as executable computer-use tasks, collects agent rollouts, and derives trajectory-level supervision for guard model training. As new threats and validation failures appear, the pipeline can be repeated, yielding an adaptive defense loop rather than a static, benchmark-driven training process. We instantiate BraveGuard by training multiple guard backbones, including Qwen3-Guard and Llama-Guard variants, and evaluate the resulting guards on trajectory-level agent-safety benchmarks. BraveGuard consistently improves safety detection across computer-use trajectories. On AgentHazard, it substantially improves detection accuracy over off-the-shelf guard models, with accuracy increasing from 38.79% to 82.38% under the averaged guard-model setting. These results show that guard supervision grounded in open-world threat discovery and realistic agent execution can improve safety monitoring beyond fixed taxonomies and synthetic prompt-level data. BraveGuard offers a scalable path toward adaptive defenses for computer-use agents facing evolving real-world risks.
Benchmarking Autonomous Agents against Temporal, Spatial, and Semantic Evasions
May 21, 2026As autonomous agents (e.g., OpenClaw) increasingly operate with deep system-level privileges to execute complex tasks, they introduce severe, unmitigated security risks. Current vulnerability analyses overwhelmingly focus on single-turn, stateless behaviors, overlooking the expanded attack surface inherent in stateful, multi-turn interactions and dynamic tool invocations. In this paper, we propose a novel, multi-dimensional evasion framework targeting LLM-based agent systems. We introduce three stealthy attack vectors: (1) Temporal evasion, which fragments malicious payloads across sequential interaction turns; (2) Spatial evasion, which conceals payloads within complex external artifacts that evade standard LLM parsing mechanisms; and (3) Semantic evasion, which obscures malicious intents beneath benign contextual noise. To systematically quantify these threats, we construct A3S-Bench, a comprehensive benchmark comprising 2,254 real-world agent execution trajectories. Evaluating a standard agent framework separately integrated with 10 mainstream LLM backbones against 20 practical threat scenarios, we demonstrate that our evasion framework elevates the average risk trigger rate from a 28.3\% baseline to 52.6\%. These findings reveal systemic, architecture-level vulnerabilities in current autonomous agent systems that existing defenses fail to address, highlighting an urgent need for defense mechanisms tailored to the unique threats.
AgentWard: A Lifecycle Security Architecture for Autonomous AI Agents
Apr 27, 2026Autonomous AI agents extend large language models into full runtime systems that load skills, ingest external content, maintain memory, plan multi-step actions, and invoke privileged tools. In such systems, security failures rarely remain confined to a single interface; instead, they can propagate across initialization, input processing, memory, decision-making, and execution, often becoming apparent only when harmful effects materialize in the environment. This paper presents AgentWard, a lifecycle-oriented, defense-in-depth architecture that systematically organizes protection across these five stages. AgentWard integrates stage-specific, heterogeneous controls with cross-layer coordination, enabling threats to be intercepted along their propagation paths while safeguarding critical assets. We detail the design rationale and architecture of five coordinated protection layers, and implement a plugin-native prototype on OpenClaw to demonstrate practical feasibility. This perspective provides a concrete blueprint for structuring runtime security controls, managing trust propagation, and enforcing execution containment in autonomous AI agents. Our code is available at https://github.com/FIND-Lab/AgentWard .
Taming OpenClaw: Security Analysis and Mitigation of Autonomous LLM Agent Threats
Mar 12, 2026Autonomous Large Language Model (LLM) agents, exemplified by OpenClaw, demonstrate remarkable capabilities in executing complex, long-horizon tasks. However, their tightly coupled instant-messaging interaction paradigm and high-privilege execution capabilities substantially expand the system attack surface. In this paper, we present a comprehensive security threat analysis of OpenClaw. To structure our analysis, we introduce a five-layer lifecycle-oriented security framework that captures key stages of agent operation, i.e., initialization, input, inference, decision, and execution, and systematically examine compound threats across the agent's operational lifecycle, including indirect prompt injection, skill supply chain contamination, memory poisoning, and intent drift. Through detailed case studies on OpenClaw, we demonstrate the prevalence and severity of these threats and analyze the limitations of existing defenses. Our findings reveal critical weaknesses in current point-based defense mechanisms when addressing cross-temporal and multi-stage systemic risks, highlighting the need for holistic security architectures for autonomous LLM agents. Within this framework, we further examine representative defense strategies at each lifecycle stage, including plugin vetting frameworks, context-aware instruction filtering, memory integrity validation protocols, intent verification mechanisms, and capability enforcement architectures.
Automating Agent Hijacking via Structural Template Injection
Feb 18, 2026Agent hijacking, highlighted by OWASP as a critical threat to the Large Language Model (LLM) ecosystem, enables adversaries to manipulate execution by injecting malicious instructions into retrieved content. Most existing attacks rely on manually crafted, semantics-driven prompt manipulation, which often yields low attack success rates and limited transferability to closed-source commercial models. In this paper, we propose Phantom, an automated agent hijacking framework built upon Structured Template Injection that targets the fundamental architectural mechanisms of LLM agents. Our key insight is that agents rely on specific chat template tokens to separate system, user, assistant, and tool instructions. By injecting optimized structured templates into the retrieved context, we induce role confusion and cause the agent to misinterpret the injected content as legitimate user instructions or prior tool outputs. To enhance attack transferability against black-box agents, Phantom introduces a novel attack template search framework. We first perform multi-level template augmentation to increase structural diversity and then train a Template Autoencoder (TAE) to embed discrete templates into a continuous, searchable latent space. Subsequently, we apply Bayesian optimization to efficiently identify optimal adversarial vectors that are decoded into high-potency structured templates. Extensive experiments on Qwen, GPT, and Gemini demonstrate that our framework significantly outperforms existing baselines in both Attack Success Rate (ASR) and query efficiency. Moreover, we identified over 70 vulnerabilities in real-world commercial products that have been confirmed by vendors, underscoring the practical severity of structured template-based hijacking and providing an empirical foundation for securing next-generation agentic systems.
STAR: Semantic-Traffic Alignment and Retrieval for Zero-Shot HTTPS Website Fingerprinting
Dec 19, 2025



Modern HTTPS mechanisms such as Encrypted Client Hello (ECH) and encrypted DNS improve privacy but remain vulnerable to website fingerprinting (WF) attacks, where adversaries infer visited sites from encrypted traffic patterns. Existing WF methods rely on supervised learning with site-specific labeled traces, which limits scalability and fails to handle previously unseen websites. We address these limitations by reformulating WF as a zero-shot cross-modal retrieval problem and introducing STAR. STAR learns a joint embedding space for encrypted traffic traces and crawl-time logic profiles using a dual-encoder architecture. Trained on 150K automatically collected traffic-logic pairs with contrastive and consistency objectives and structure-aware augmentation, STAR retrieves the most semantically aligned profile for a trace without requiring target-side traffic during training. Experiments on 1,600 unseen websites show that STAR achieves 87.9 percent top-1 accuracy and 0.963 AUC in open-world detection, outperforming supervised and few-shot baselines. Adding an adapter with only four labeled traces per site further boosts top-5 accuracy to 98.8 percent. Our analysis reveals intrinsic semantic-traffic alignment in modern web protocols, identifying semantic leakage as the dominant privacy risk in encrypted HTTPS traffic. We release STAR's datasets and code to support reproducibility and future research.
Beyond a Single Perspective: Towards a Realistic Evaluation of Website Fingerprinting Attacks
Oct 16, 2025Website Fingerprinting (WF) attacks exploit patterns in encrypted traffic to infer the websites visited by users, posing a serious threat to anonymous communication systems. Although recent WF techniques achieve over 90% accuracy in controlled experimental settings, most studies remain confined to single scenarios, overlooking the complexity of real-world environments. This paper presents the first systematic and comprehensive evaluation of existing WF attacks under diverse realistic conditions, including defense mechanisms, traffic drift, multi-tab browsing, early-stage detection, open-world settings, and few-shot scenarios. Experimental results show that many WF techniques with strong performance in isolated settings degrade significantly when facing other conditions. Since real-world environments often combine multiple challenges, current WF attacks are difficult to apply directly in practice. This study highlights the limitations of WF attacks and introduces a multidimensional evaluation framework, offering critical insights for developing more robust and practical WF attacks.
Towards Fine-Grained Webpage Fingerprinting at Scale
Sep 06, 2024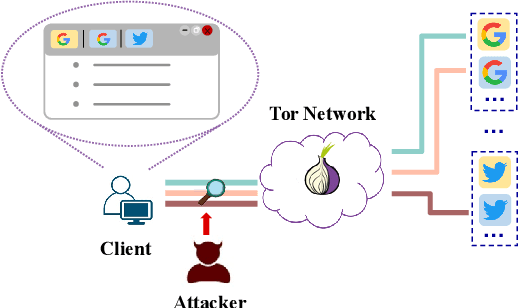
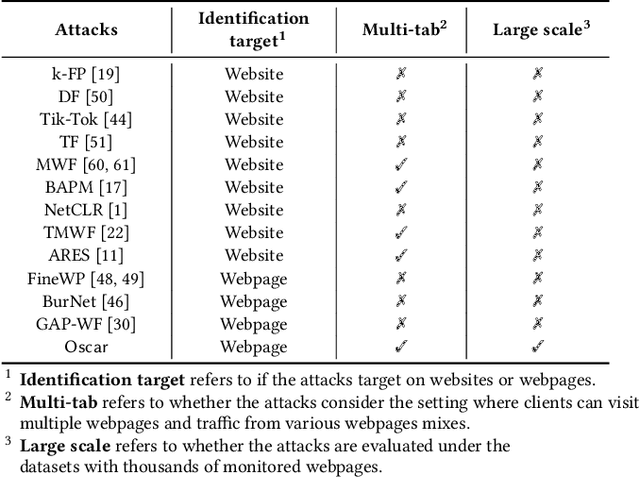
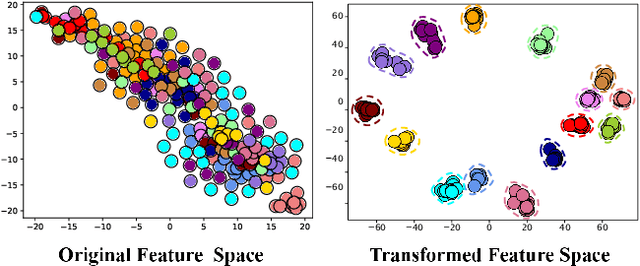

Website Fingerprinting (WF) attacks can effectively identify the websites visited by Tor clients via analyzing encrypted traffic patterns. Existing attacks focus on identifying different websites, but their accuracy dramatically decreases when applied to identify fine-grained webpages, especially when distinguishing among different subpages of the same website. WebPage Fingerprinting (WPF) attacks face the challenges of highly similar traffic patterns and a much larger scale of webpages. Furthermore, clients often visit multiple webpages concurrently, increasing the difficulty of extracting the traffic patterns of each webpage from the obfuscated traffic. In this paper, we propose Oscar, a WPF attack based on multi-label metric learning that identifies different webpages from obfuscated traffic by transforming the feature space. Oscar can extract the subtle differences among various webpages, even those with similar traffic patterns. In particular, Oscar combines proxy-based and sample-based metric learning losses to extract webpage features from obfuscated traffic and identify multiple webpages. We prototype Oscar and evaluate its performance using traffic collected from 1,000 monitored webpages and over 9,000 unmonitored webpages in the real world. Oscar demonstrates an 88.6% improvement in the multi-label metric Recall@5 compared to the state-of-the-art attacks.
Robust and Reliable Early-Stage Website Fingerprinting Attacks via Spatial-Temporal Distribution Analysis
Jul 01, 2024



Website Fingerprinting (WF) attacks identify the websites visited by users by performing traffic analysis, compromising user privacy. Particularly, DL-based WF attacks demonstrate impressive attack performance. However, the effectiveness of DL-based WF attacks relies on the collected complete and pure traffic during the page loading, which impacts the practicality of these attacks. The WF performance is rather low under dynamic network conditions and various WF defenses, particularly when the analyzed traffic is only a small part of the complete traffic. In this paper, we propose Holmes, a robust and reliable early-stage WF attack. Holmes utilizes temporal and spatial distribution analysis of website traffic to effectively identify websites in the early stages of page loading. Specifically, Holmes develops adaptive data augmentation based on the temporal distribution of website traffic and utilizes a supervised contrastive learning method to extract the correlations between the early-stage traffic and the pre-collected complete traffic. Holmes accurately identifies traffic in the early stages of page loading by computing the correlation of the traffic with the spatial distribution information, which ensures robust and reliable detection according to early-stage traffic. We extensively evaluate Holmes using six datasets. Compared to nine existing DL-based WF attacks, Holmes improves the F1-score of identifying early-stage traffic by an average of 169.18%. Furthermore, we replay the traffic of visiting real-world dark web websites. Holmes successfully identifies dark web websites when the ratio of page loading on average is only 21.71%, with an average precision improvement of 169.36% over the existing WF attacks.
MAS-SAM: Segment Any Marine Animal with Aggregated Features
Apr 24, 2024



Recently, Segment Anything Model (SAM) shows exceptional performance in generating high-quality object masks and achieving zero-shot image segmentation. However, as a versatile vision model, SAM is primarily trained with large-scale natural light images. In underwater scenes, it exhibits substantial performance degradation due to the light scattering and absorption. Meanwhile, the simplicity of the SAM's decoder might lead to the loss of fine-grained object details. To address the above issues, we propose a novel feature learning framework named MAS-SAM for marine animal segmentation, which involves integrating effective adapters into the SAM's encoder and constructing a pyramidal decoder. More specifically, we first build a new SAM's encoder with effective adapters for underwater scenes. Then, we introduce a Hypermap Extraction Module (HEM) to generate multi-scale features for a comprehensive guidance. Finally, we propose a Progressive Prediction Decoder (PPD) to aggregate the multi-scale features and predict the final segmentation results. When grafting with the Fusion Attention Module (FAM), our method enables to extract richer marine information from global contextual cues to fine-grained local details. Extensive experiments on four public MAS datasets demonstrate that our MAS-SAM can obtain better results than other typical segmentation methods. The source code is available at https://github.com/Drchip61/MAS-SAM.