 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond a Single Perspective: Towards a Realistic Evaluation of Website Fingerprinting Attacks
Oct 16, 2025Website Fingerprinting (WF) attacks exploit patterns in encrypted traffic to infer the websites visited by users, posing a serious threat to anonymous communication systems. Although recent WF techniques achieve over 90% accuracy in controlled experimental settings, most studies remain confined to single scenarios, overlooking the complexity of real-world environments. This paper presents the first systematic and comprehensive evaluation of existing WF attacks under diverse realistic conditions, including defense mechanisms, traffic drift, multi-tab browsing, early-stage detection, open-world settings, and few-shot scenarios. Experimental results show that many WF techniques with strong performance in isolated settings degrade significantly when facing other conditions. Since real-world environments often combine multiple challenges, current WF attacks are difficult to apply directly in practice. This study highlights the limitations of WF attacks and introduces a multidimensional evaluation framework, offering critical insights for developing more robust and practical WF attacks.
Towards Fine-Grained Webpage Fingerprinting at Scale
Sep 06, 2024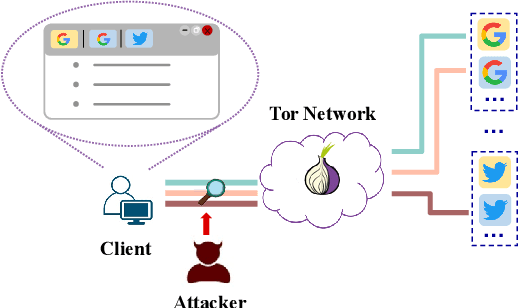
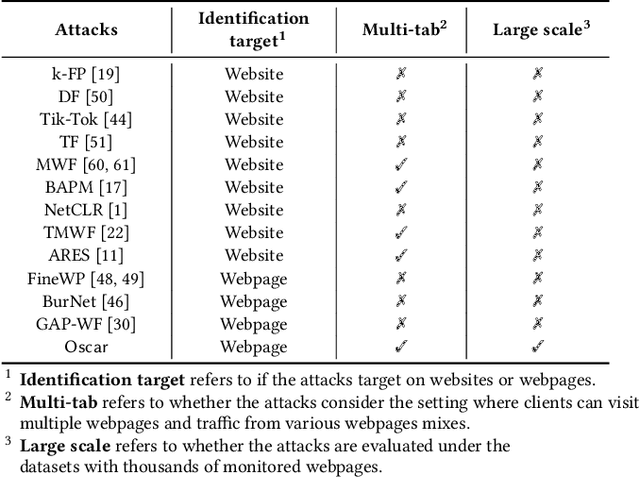
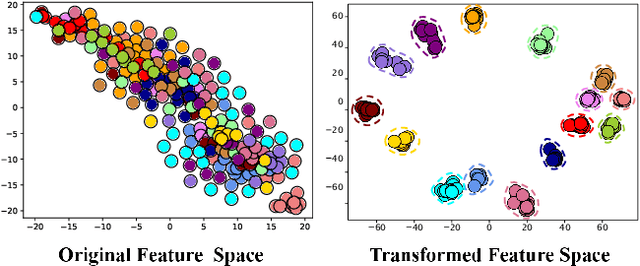

Website Fingerprinting (WF) attacks can effectively identify the websites visited by Tor clients via analyzing encrypted traffic patterns. Existing attacks focus on identifying different websites, but their accuracy dramatically decreases when applied to identify fine-grained webpages, especially when distinguishing among different subpages of the same website. WebPage Fingerprinting (WPF) attacks face the challenges of highly similar traffic patterns and a much larger scale of webpages. Furthermore, clients often visit multiple webpages concurrently, increasing the difficulty of extracting the traffic patterns of each webpage from the obfuscated traffic. In this paper, we propose Oscar, a WPF attack based on multi-label metric learning that identifies different webpages from obfuscated traffic by transforming the feature space. Oscar can extract the subtle differences among various webpages, even those with similar traffic patterns. In particular, Oscar combines proxy-based and sample-based metric learning losses to extract webpage features from obfuscated traffic and identify multiple webpages. We prototype Oscar and evaluate its performance using traffic collected from 1,000 monitored webpages and over 9,000 unmonitored webpages in the real world. Oscar demonstrates an 88.6% improvement in the multi-label metric Recall@5 compared to the state-of-the-art attacks.
Learning Multimodal Confidence for Intention Recognition in Human-Robot Interaction
May 23, 2024



The rapid development of collaborative robotics has provided a new possibility of helping the elderly who has difficulties in daily life, allowing robots to operate according to specific intentions. However, efficient human-robot cooperation requires natural, accurate and reliable intention recognition in shared environments. The current paramount challenge for this is reducing the uncertainty of multimodal fused intention to be recognized and reasoning adaptively a more reliable result despite current interactive condition. In this work we propose a novel learning-based multimodal fusion framework Batch Multimodal Confidence Learning for Opinion Pool (BMCLOP). Our approach combines Bayesian multimodal fusion method and batch confidence learning algorithm to improve accuracy, uncertainty reduction and success rate given the interactive condition. In particular, the generic and practical multimodal intention recognition framework can be easily extended further. Our desired assistive scenarios consider three modalities gestures, speech and gaze, all of which produce categorical distributions over all the finite intentions. The proposed method is validated with a six-DoF robot through extensive experiments and exhibits high performance compared to baselines.