 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHFP-SAM: Hierarchical Frequency Prompted SAM for Efficient Marine Animal Segmentation
Mar 13, 2026Marine Animal Segmentation (MAS) aims at identifying and segmenting marine animals from complex marine environments. Most of previous deep learning-based MAS methods struggle with the long-distance modeling issue. Recently, Segment Anything Model (SAM) has gained popularity in general image segmentation. However, it lacks of perceiving fine-grained details and frequency information. To this end, we propose a novel learning framework, named Hierarchical Frequency Prompted SAM (HFP-SAM) for high-performance MAS. First, we design a Frequency Guided Adapter (FGA) to efficiently inject marine scene information into the frozen SAM backbone through frequency domain prior masks. Additionally, we introduce a Frequency-aware Point Selection (FPS) to generate highlighted regions through frequency analysis. These regions are combined with the coarse predictions of SAM to generate point prompts and integrate into SAM's decoder for fine predictions. Finally, to obtain comprehensive segmentation masks, we introduce a Full-View Mamba (FVM) to efficiently extract spatial and channel contextual information with linear computational complexity. Extensive experiments on four public datasets demonstrate the superior performance of our approach. The source code is publicly available at https://github.com/Drchip61/TIP-HFP-SAM.
Towards Interactive Intelligence for Digital Humans
Dec 15, 2025We introduce Interactive Intelligence, a novel paradigm of digital human that is capable of personality-aligned expression, adaptive interaction, and self-evolution. To realize this, we present Mio (Multimodal Interactive Omni-Avatar), an end-to-end framework composed of five specialized modules: Thinker, Talker, Face Animator, Body Animator, and Renderer. This unified architecture integrates cognitive reasoning with real-time multimodal embodiment to enable fluid, consistent interaction. Furthermore, we establish a new benchmark to rigorously evaluate the capabilities of interactive intelligence. Extensive experiments demonstrate that our framework achieves superior performance compared to state-of-the-art methods across all evaluated dimensions. Together, these contributions move digital humans beyond superficial imitation toward intelligent interaction.
Living the Novel: A System for Generating Self-Training Timeline-Aware Conversational Agents from Novels
Dec 08, 2025



We present the Living Novel, an end-to-end system that transforms any literary work into an immersive, multi-character conversational experience. This system is designed to solve two fundamental challenges for LLM-driven characters. Firstly, generic LLMs suffer from persona drift, often failing to stay in character. Secondly, agents often exhibit abilities that extend beyond the constraints of the story's world and logic, leading to both narrative incoherence (spoiler leakage) and robustness failures (frame-breaking). To address these challenges, we introduce a novel two-stage training pipeline. Our Deep Persona Alignment (DPA) stage uses data-free reinforcement finetuning to instill deep character fidelity. Our Coherence and Robustness Enhancing (CRE) stage then employs a story-time-aware knowledge graph and a second retrieval-grounded training pass to architecturally enforce these narrative constraints. We validate our system through a multi-phase evaluation using Jules Verne's Twenty Thousand Leagues Under the Sea. A lab study with a detailed ablation of system components is followed by a 5-day in-the-wild diary study. Our DPA pipeline helps our specialized model outperform GPT-4o on persona-specific metrics, and our CRE stage achieves near-perfect performance in coherence and robustness measures. Our study surfaces practical design guidelines for AI-driven narrative systems: we find that character-first self-training is foundational for believability, while explicit story-time constraints are crucial for sustaining coherent, interruption-resilient mobile-web experiences.
MambaPro: Multi-Modal Object Re-Identification with Mamba Aggregation and Synergistic Prompt
Dec 14, 2024



Multi-modal object Re-IDentification (ReID) aims to retrieve specific objects by utilizing complementary image information from different modalities. Recently, large-scale pre-trained models like CLIP have demonstrated impressive performance in traditional single-modal object ReID tasks. However, they remain unexplored for multi-modal object ReID. Furthermore, current multi-modal aggregation methods have obvious limitations in dealing with long sequences from different modalities. To address above issues, we introduce a novel framework called MambaPro for multi-modal object ReID. To be specific, we first employ a Parallel Feed-Forward Adapter (PFA) for adapting CLIP to multi-modal object ReID. Then, we propose the Synergistic Residual Prompt (SRP) to guide the joint learning of multi-modal features. Finally, leveraging Mamba's superior scalability for long sequences, we introduce Mamba Aggregation (MA) to efficiently model interactions between different modalities. As a result, MambaPro could extract more robust features with lower complexity. Extensive experiments on three multi-modal object ReID benchmarks (i.e., RGBNT201, RGBNT100 and MSVR310) validate the effectiveness of our proposed methods. The source code is available at https://github.com/924973292/MambaPro.
Multi-Scale and Detail-Enhanced Segment Anything Model for Salient Object Detection
Aug 08, 2024



Salient Object Detection (SOD) aims to identify and segment the most prominent objects in images. Advanced SOD methods often utilize various Convolutional Neural Networks (CNN) or Transformers for deep feature extraction. However, these methods still deliver low performance and poor generalization in complex cases. Recently, Segment Anything Model (SAM) has been proposed as a visual fundamental model, which gives strong segmentation and generalization capabilities. Nonetheless, SAM requires accurate prompts of target objects, which are unavailable in SOD. Additionally, SAM lacks the utilization of multi-scale and multi-level information, as well as the incorporation of fine-grained details. To address these shortcomings, we propose a Multi-scale and Detail-enhanced SAM (MDSAM) for SOD. Specifically, we first introduce a Lightweight Multi-Scale Adapter (LMSA), which allows SAM to learn multi-scale information with very few trainable parameters. Then, we propose a Multi-Level Fusion Module (MLFM) to comprehensively utilize the multi-level information from the SAM's encoder. Finally, we propose a Detail Enhancement Module (DEM) to incorporate SAM with fine-grained details. Experimental results demonstrate the superior performance of our model on multiple SOD datasets and its strong generalization on other segmentation tasks. The source code is released at https://github.com/BellyBeauty/MDSAM.
MAS-SAM: Segment Any Marine Animal with Aggregated Features
Apr 24, 2024



Recently, Segment Anything Model (SAM) shows exceptional performance in generating high-quality object masks and achieving zero-shot image segmentation. However, as a versatile vision model, SAM is primarily trained with large-scale natural light images. In underwater scenes, it exhibits substantial performance degradation due to the light scattering and absorption. Meanwhile, the simplicity of the SAM's decoder might lead to the loss of fine-grained object details. To address the above issues, we propose a novel feature learning framework named MAS-SAM for marine animal segmentation, which involves integrating effective adapters into the SAM's encoder and constructing a pyramidal decoder. More specifically, we first build a new SAM's encoder with effective adapters for underwater scenes. Then, we introduce a Hypermap Extraction Module (HEM) to generate multi-scale features for a comprehensive guidance. Finally, we propose a Progressive Prediction Decoder (PPD) to aggregate the multi-scale features and predict the final segmentation results. When grafting with the Fusion Attention Module (FAM), our method enables to extract richer marine information from global contextual cues to fine-grained local details. Extensive experiments on four public MAS datasets demonstrate that our MAS-SAM can obtain better results than other typical segmentation methods. The source code is available at https://github.com/Drchip61/MAS-SAM.
Fantastic Animals and Where to Find Them: Segment Any Marine Animal with Dual SAM
Apr 07, 2024As an important pillar of underwater intelligence, Marine Animal Segmentation (MAS) involves segmenting animals within marine environments. Previous methods don't excel in extracting long-range contextual features and overlook the connectivity between discrete pixels. Recently, Segment Anything Model (SAM) offers a universal framework for general segmentation tasks. Unfortunately, trained with natural images, SAM does not obtain the prior knowledge from marine images. In addition, the single-position prompt of SAM is very insufficient for prior guidance. To address these issues, we propose a novel feature learning framework, named Dual-SAM for high-performance MAS. To this end, we first introduce a dual structure with SAM's paradigm to enhance feature learning of marine images. Then, we propose a Multi-level Coupled Prompt (MCP) strategy to instruct comprehensive underwater prior information, and enhance the multi-level features of SAM's encoder with adapters. Subsequently, we design a Dilated Fusion Attention Module (DFAM) to progressively integrate multi-level features from SAM's encoder. Finally, instead of directly predicting the masks of marine animals, we propose a Criss-Cross Connectivity Prediction (C$^3$P) paradigm to capture the inter-connectivity between discrete pixels. With dual decoders, it generates pseudo-labels and achieves mutual supervision for complementary feature representations, resulting in considerable improvements over previous techniques. Extensive experiments verify that our proposed method achieves state-of-the-art performances on five widely-used MAS datasets. The code is available at https://github.com/Drchip61/Dual_SAM.
TransY-Net:Learning Fully Transformer Networks for Change Detection of Remote Sensing Images
Oct 22, 2023In the remote sensing field, Change Detection (CD) aims to identify and localize the changed regions from dual-phase images over the same places. Recently, it has achieved great progress with the advances of deep learning. However, current methods generally deliver incomplete CD regions and irregular CD boundaries due to the limited representation ability of the extracted visual features. To relieve these issues, in this work we propose a novel Transformer-based learning framework named TransY-Net for remote sensing image CD, which improves the feature extraction from a global view and combines multi-level visual features in a pyramid manner. More specifically, the proposed framework first utilizes the advantages of Transformers in long-range dependency modeling. It can help to learn more discriminative global-level features and obtain complete CD regions. Then, we introduce a novel pyramid structure to aggregate multi-level visual features from Transformers for feature enhancement. The pyramid structure grafted with a Progressive Attention Module (PAM) can improve the feature representation ability with additional inter-dependencies through spatial and channel attentions. Finally, to better train the whole framework, we utilize the deeply-supervised learning with multiple boundary-aware loss functions. Extensive experiments demonstrate that our proposed method achieves a new state-of-the-art performance on four optical and two SAR image CD benchmarks. The source code is released at https://github.com/Drchip61/TransYNet.
Fully Transformer Network for Change Detection of Remote Sensing Images
Oct 03, 2022
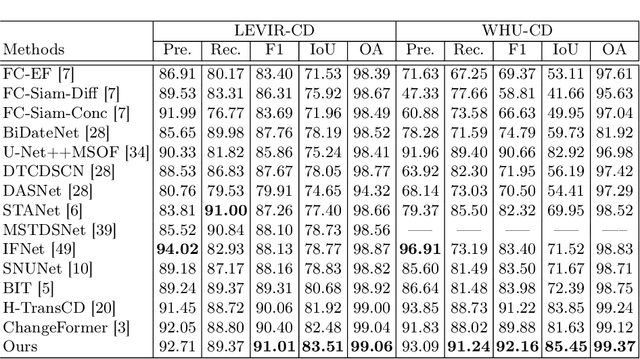
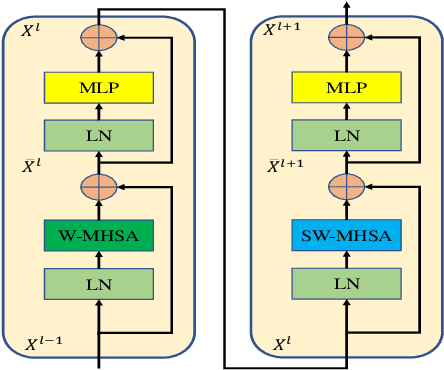
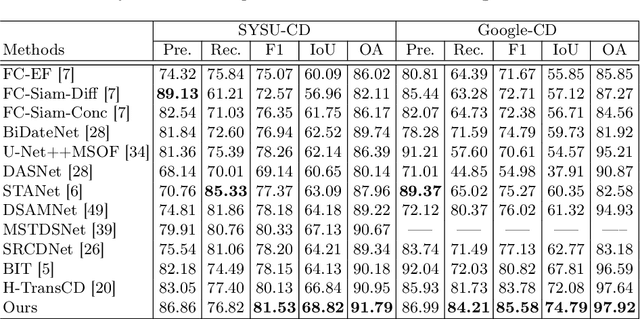
Recently, change detection (CD) of remote sensing images have achieved great progress with the advances of deep learning. However, current methods generally deliver incomplete CD regions and irregular CD boundaries due to the limited representation ability of the extracted visual features. To relieve these issues, in this work we propose a novel learning framework named Fully Transformer Network (FTN) for remote sensing image CD, which improves the feature extraction from a global view and combines multi-level visual features in a pyramid manner. More specifically, the proposed framework first utilizes the advantages of Transformers in long-range dependency modeling. It can help to learn more discriminative global-level features and obtain complete CD regions. Then, we introduce a pyramid structure to aggregate multi-level visual features from Transformers for feature enhancement. The pyramid structure grafted with a Progressive Attention Module (PAM) can improve the feature representation ability with additional interdependencies through channel attentions. Finally, to better train the framework, we utilize the deeply-supervised learning with multiple boundaryaware loss functions. Extensive experiments demonstrate that our proposed method achieves a new state-of-the-art performance on four public CD benchmarks. For model reproduction, the source code is released at https://github.com/AI-Zhpp/FTN.
Mind Your Clever Neighbours: Unsupervised Person Re-identification via Adaptive Clustering Relationship Modeling
Dec 08, 2021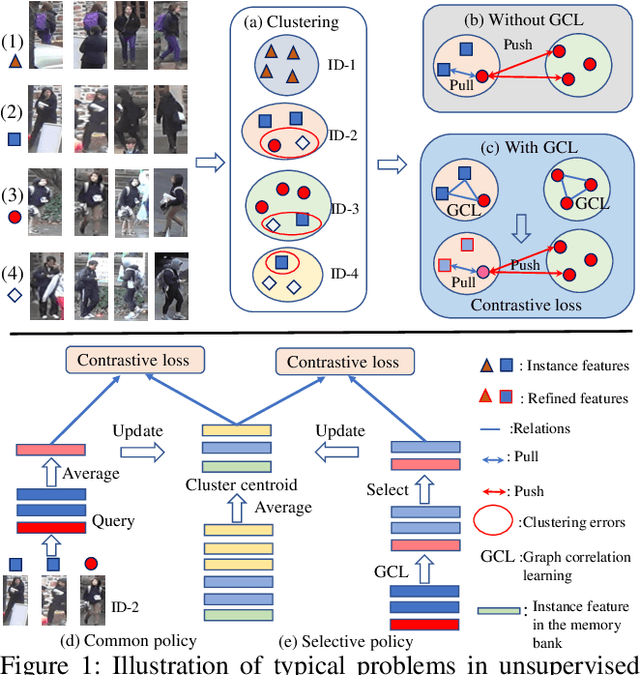
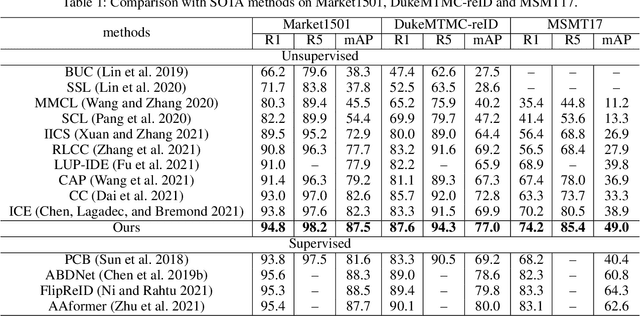
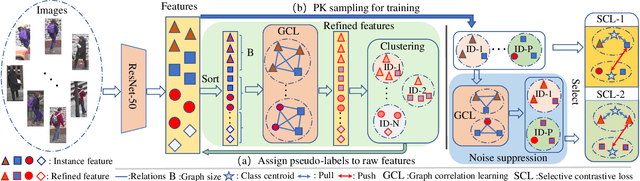
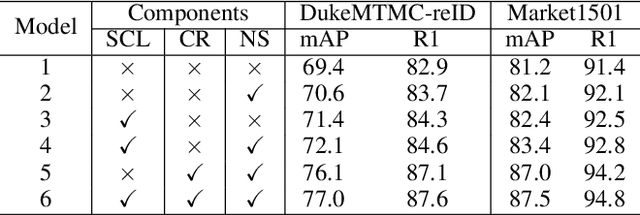
Unsupervised person re-identification (Re-ID) attracts increasing attention due to its potential to resolve the scalability problem of supervised Re-ID models. Most existing unsupervised methods adopt an iterative clustering mechanism, where the network was trained based on pseudo labels generated by unsupervised clustering. However, clustering errors are inevitable. To generate high-quality pseudo-labels and mitigate the impact of clustering errors, we propose a novel clustering relationship modeling framework for unsupervised person Re-ID. Specifically, before clustering, the relation between unlabeled images is explored based on a graph correlation learning (GCL) module and the refined features are then used for clustering to generate high-quality pseudo-labels.Thus, GCL adaptively mines the relationship between samples in a mini-batch to reduce the impact of abnormal clustering when training. To train the network more effectively, we further propose a selective contrastive learning (SCL) method with a selective memory bank update policy. Extensive experiments demonstrate that our method shows much better results than most state-of-the-art unsupervised methods on Market1501, DukeMTMC-reID and MSMT17 datasets. We will release the code for model reproduction.