 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniMRSeg: Unified Modality-Relax Segmentation via Hierarchical Self-Supervised Compensation
Sep 19, 2025Multi-modal image segmentation faces real-world deployment challenges from incomplete/corrupted modalities degrading performance. While existing methods address training-inference modality gaps via specialized per-combination models, they introduce high deployment costs by requiring exhaustive model subsets and model-modality matching. In this work, we propose a unified modality-relax segmentation network (UniMRSeg) through hierarchical self-supervised compensation (HSSC). Our approach hierarchically bridges representation gaps between complete and incomplete modalities across input, feature and output levels. % First, we adopt modality reconstruction with the hybrid shuffled-masking augmentation, encouraging the model to learn the intrinsic modality characteristics and generate meaningful representations for missing modalities through cross-modal fusion. % Next, modality-invariant contrastive learning implicitly compensates the feature space distance among incomplete-complete modality pairs. Furthermore, the proposed lightweight reverse attention adapter explicitly compensates for the weak perceptual semantics in the frozen encoder. Last, UniMRSeg is fine-tuned under the hybrid consistency constraint to ensure stable prediction under all modality combinations without large performance fluctuations. Without bells and whistles, UniMRSeg significantly outperforms the state-of-the-art methods under diverse missing modality scenarios on MRI-based brain tumor segmentation, RGB-D semantic segmentation, RGB-D/T salient object segmentation. The code will be released at https://github.com/Xiaoqi-Zhao-DLUT/UniMRSeg.
FlowDistill: Scalable Traffic Flow Prediction via Distillation from LLMs
Apr 02, 2025Accurate traffic flow prediction is vital for optimizing urban mobility, yet it remains difficult in many cities due to complex spatio-temporal dependencies and limited high-quality data. While deep graph-based models demonstrate strong predictive power, their performance often comes at the cost of high computational overhead and substantial training data requirements, making them impractical for deployment in resource-constrained or data-scarce environments. We propose the FlowDistill, a lightweight and scalable traffic prediction framework based on knowledge distillation from large language models (LLMs). In this teacher-student setup, a fine-tuned LLM guides a compact multi-layer perceptron (MLP) student model using a novel combination of the information bottleneck principle and teacher-bounded regression loss, ensuring the distilled model retains only essential and transferable knowledge. Spatial and temporal correlations are explicitly encoded to enhance the model's generalization across diverse urban settings. Despite its simplicity, FlowDistill consistently outperforms state-of-the-art models in prediction accuracy while requiring significantly less training data, and achieving lower memory usage and inference latency, highlighting its efficiency and suitability for real-world, scalable deployment.
Harnessing LLMs for Cross-City OD Flow Prediction
Sep 05, 2024



Understanding and predicting Origin-Destination (OD) flows is crucial for urban planning and transportation management. Traditional OD prediction models, while effective within single cities, often face limitations when applied across different cities due to varied traffic conditions, urban layouts, and socio-economic factors. In this paper, by employing Large Language Models (LLMs), we introduce a new method for cross-city OD flow prediction. Our approach leverages the advanced semantic understanding and contextual learning capabilities of LLMs to bridge the gap between cities with different characteristics, providing a robust and adaptable solution for accurate OD flow prediction that can be transferred from one city to another. Our novel framework involves four major components: collecting OD training datasets from a source city, instruction-tuning the LLMs, predicting destination POIs in a target city, and identifying the locations that best match the predicted destination POIs. We introduce a new loss function that integrates POI semantics and trip distance during training. By extracting high-quality semantic features from human mobility and POI data, the model understands spatial and functional relationships within urban spaces and captures interactions between individuals and various POIs. Extensive experimental results demonstrate the superiority of our approach over the state-of-the-art learning-based methods in cross-city OD flow prediction.
Part Representation Learning with Teacher-Student Decoder for Occluded Person Re-identification
Dec 15, 2023



Occluded person re-identification (ReID) is a very challenging task due to the occlusion disturbance and incomplete target information. Leveraging external cues such as human pose or parsing to locate and align part features has been proven to be very effective in occluded person ReID. Meanwhile, recent Transformer structures have a strong ability of long-range modeling. Considering the above facts, we propose a Teacher-Student Decoder (TSD) framework for occluded person ReID, which utilizes the Transformer decoder with the help of human parsing. More specifically, our proposed TSD consists of a Parsing-aware Teacher Decoder (PTD) and a Standard Student Decoder (SSD). PTD employs human parsing cues to restrict Transformer's attention and imparts this information to SSD through feature distillation. Thereby, SSD can learn from PTD to aggregate information of body parts automatically. Moreover, a mask generator is designed to provide discriminative regions for better ReID. In addition, existing occluded person ReID benchmarks utilize occluded samples as queries, which will amplify the role of alleviating occlusion interference and underestimate the impact of the feature absence issue. Contrastively, we propose a new benchmark with non-occluded queries, serving as a complement to the existing benchmark. Extensive experiments demonstrate that our proposed method is superior and the new benchmark is essential. The source codes are available at https://github.com/hh23333/TSD.
TF-CLIP: Learning Text-free CLIP for Video-based Person Re-Identification
Dec 15, 2023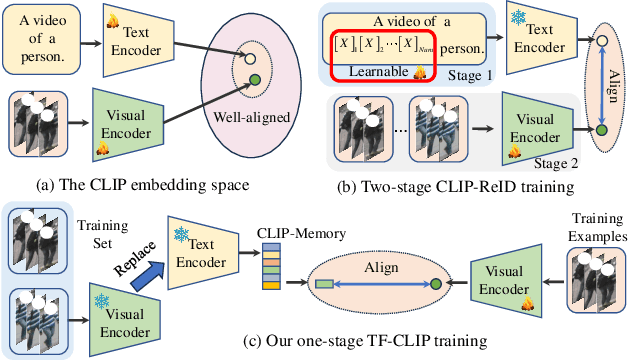
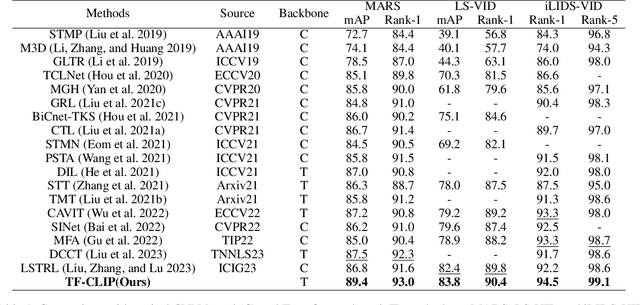
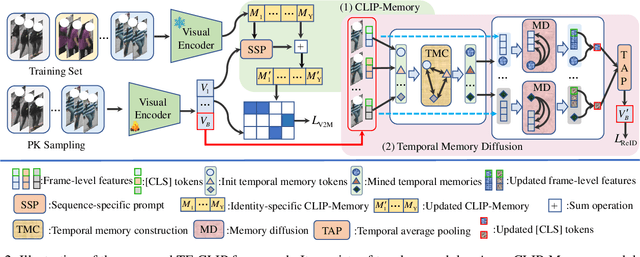

Large-scale language-image pre-trained models (e.g., CLIP) have shown superior performances on many cross-modal retrieval tasks. However, the problem of transferring the knowledge learned from such models to video-based person re-identification (ReID) has barely been explored. In addition, there is a lack of decent text descriptions in current ReID benchmarks. To address these issues, in this work, we propose a novel one-stage text-free CLIP-based learning framework named TF-CLIP for video-based person ReID. More specifically, we extract the identity-specific sequence feature as the CLIP-Memory to replace the text feature. Meanwhile, we design a Sequence-Specific Prompt (SSP) module to update the CLIP-Memory online. To capture temporal information, we further propose a Temporal Memory Diffusion (TMD) module, which consists of two key components: Temporal Memory Construction (TMC) and Memory Diffusion (MD). Technically, TMC allows the frame-level memories in a sequence to communicate with each other, and to extract temporal information based on the relations within the sequence. MD further diffuses the temporal memories to each token in the original features to obtain more robust sequence features. Extensive experiments demonstrate that our proposed method shows much better results than other state-of-the-art methods on MARS, LS-VID and iLIDS-VID. The code is available at https://github.com/AsuradaYuci/TF-CLIP.
Deeply-Coupled Convolution-Transformer with Spatial-temporal Complementary Learning for Video-based Person Re-identification
Apr 27, 2023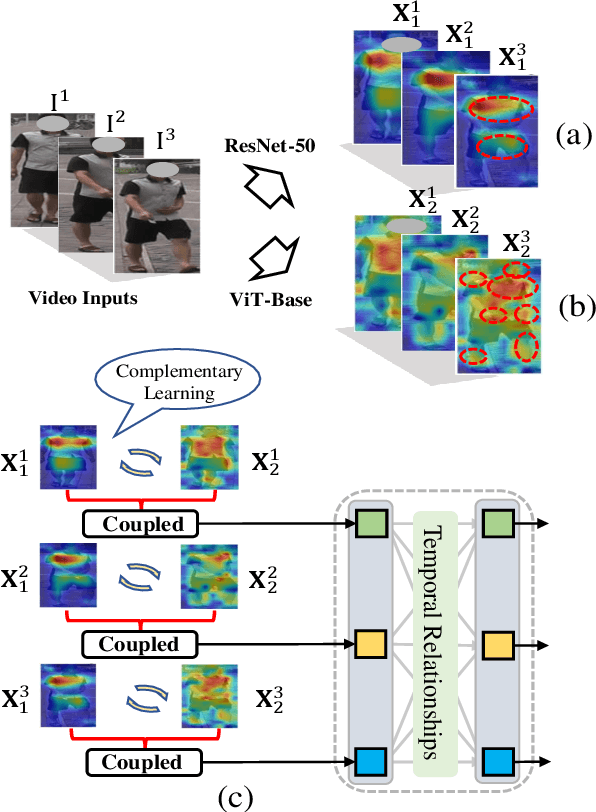
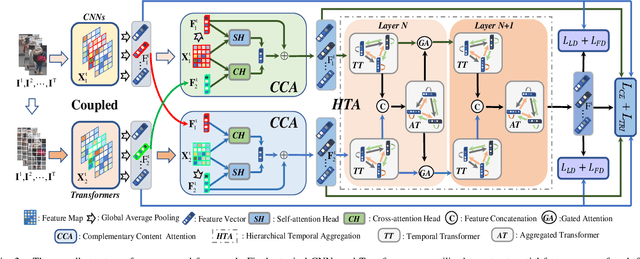
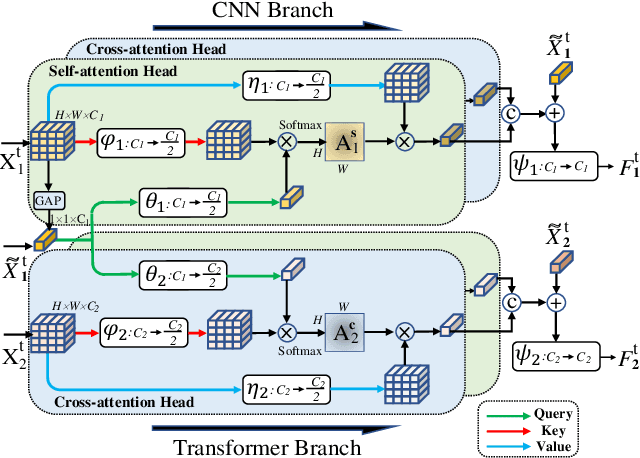
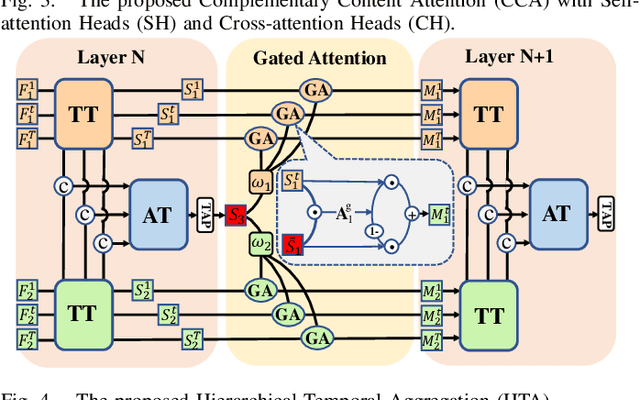
Advanced deep Convolutional Neural Networks (CNNs) have shown great success in video-based person Re-Identification (Re-ID). However, they usually focus on the most obvious regions of persons with a limited global representation ability. Recently, it witnesses that Transformers explore the inter-patch relations with global observations for performance improvements. In this work, we take both sides and propose a novel spatial-temporal complementary learning framework named Deeply-Coupled Convolution-Transformer (DCCT) for high-performance video-based person Re-ID. Firstly, we couple CNNs and Transformers to extract two kinds of visual features and experimentally verify their complementarity. Further, in spatial, we propose a Complementary Content Attention (CCA) to take advantages of the coupled structure and guide independent features for spatial complementary learning. In temporal, a Hierarchical Temporal Aggregation (HTA) is proposed to progressively capture the inter-frame dependencies and encode temporal information. Besides, a gated attention is utilized to deliver aggregated temporal information into the CNN and Transformer branches for temporal complementary learning. Finally, we introduce a self-distillation training strategy to transfer the superior spatial-temporal knowledge to backbone networks for higher accuracy and more efficiency. In this way, two kinds of typical features from same videos are integrated mechanically for more informative representations. Extensive experiments on four public Re-ID benchmarks demonstrate that our framework could attain better performances than most state-of-the-art methods.
Mind Your Clever Neighbours: Unsupervised Person Re-identification via Adaptive Clustering Relationship Modeling
Dec 08, 2021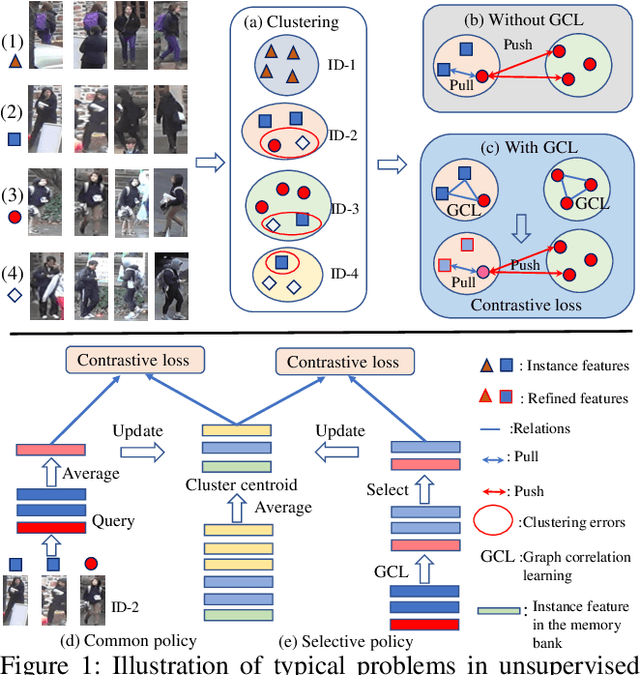
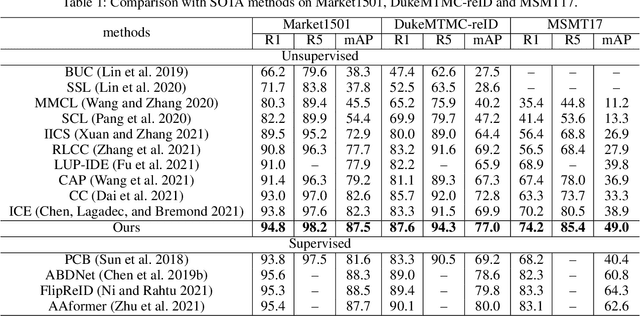
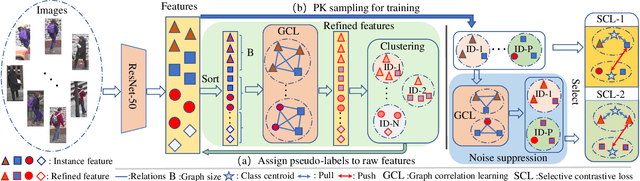
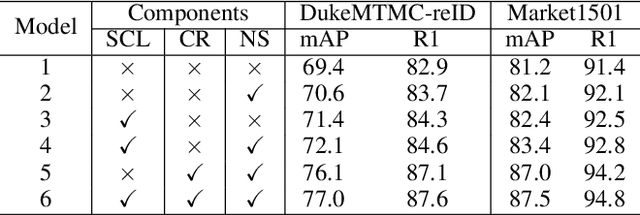
Unsupervised person re-identification (Re-ID) attracts increasing attention due to its potential to resolve the scalability problem of supervised Re-ID models. Most existing unsupervised methods adopt an iterative clustering mechanism, where the network was trained based on pseudo labels generated by unsupervised clustering. However, clustering errors are inevitable. To generate high-quality pseudo-labels and mitigate the impact of clustering errors, we propose a novel clustering relationship modeling framework for unsupervised person Re-ID. Specifically, before clustering, the relation between unlabeled images is explored based on a graph correlation learning (GCL) module and the refined features are then used for clustering to generate high-quality pseudo-labels.Thus, GCL adaptively mines the relationship between samples in a mini-batch to reduce the impact of abnormal clustering when training. To train the network more effectively, we further propose a selective contrastive learning (SCL) method with a selective memory bank update policy. Extensive experiments demonstrate that our method shows much better results than most state-of-the-art unsupervised methods on Market1501, DukeMTMC-reID and MSMT17 datasets. We will release the code for model reproduction.
A Video Is Worth Three Views: Trigeminal Transformers for Video-based Person Re-identification
Apr 05, 2021
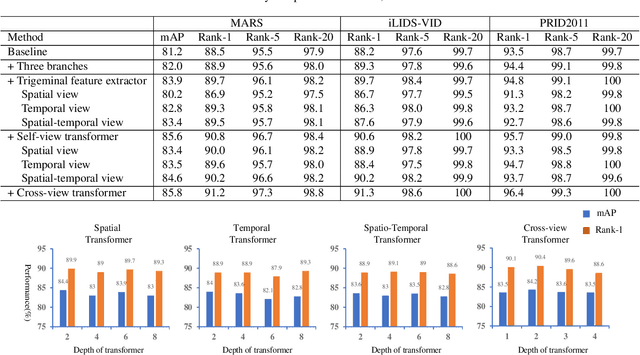

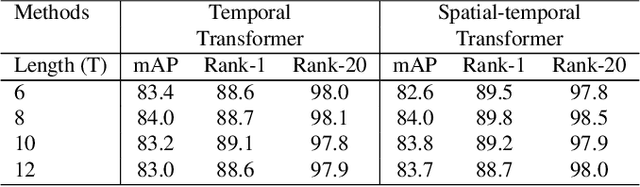
Video-based person re-identification (Re-ID) aims to retrieve video sequences of the same person under non-overlapping cameras. Previous methods usually focus on limited views, such as spatial, temporal or spatial-temporal view, which lack of the observations in different feature domains. To capture richer perceptions and extract more comprehensive video representations, in this paper we propose a novel framework named Trigeminal Transformers (TMT) for video-based person Re-ID. More specifically, we design a trigeminal feature extractor to jointly transform raw video data into spatial, temporal and spatial-temporal domain. Besides, inspired by the great success of vision transformer, we introduce the transformer structure for video-based person Re-ID. In our work, three self-view transformers are proposed to exploit the relationships between local features for information enhancement in spatial, temporal and spatial-temporal domains. Moreover, a cross-view transformer is proposed to aggregate the multi-view features for comprehensive video representations. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches on public Re-ID benchmarks. We will release the code for model reproduction.
Watching You: Global-guided Reciprocal Learning for Video-based Person Re-identification
Apr 01, 2021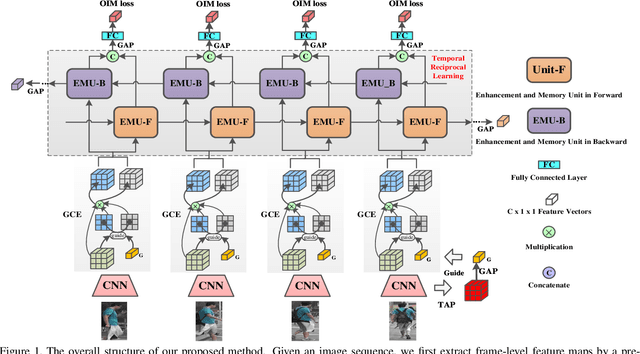
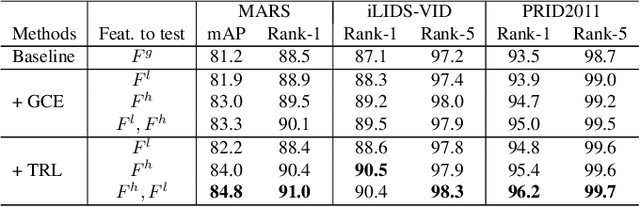
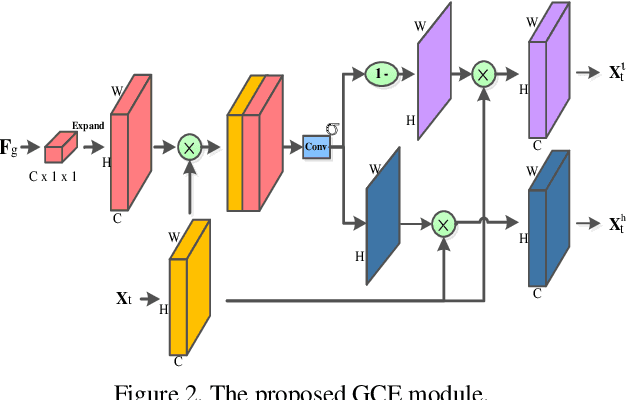
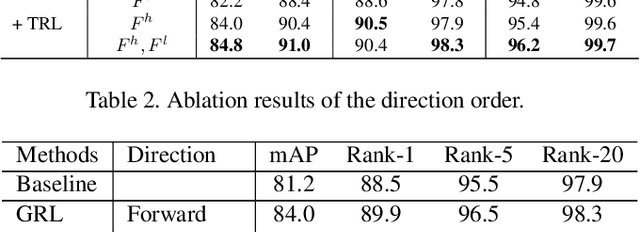
Video-based person re-identification (Re-ID) aims to automatically retrieve video sequences of the same person under non-overlapping cameras. To achieve this goal, it is the key to fully utilize abundant spatial and temporal cues in videos. Existing methods usually focus on the most conspicuous image regions, thus they may easily miss out fine-grained clues due to the person varieties in image sequences. To address above issues, in this paper, we propose a novel Global-guided Reciprocal Learning (GRL) framework for video-based person Re-ID. Specifically, we first propose a Global-guided Correlation Estimation (GCE) to generate feature correlation maps of local features and global features, which help to localize the high- and low-correlation regions for identifying the same person. After that, the discriminative features are disentangled into high-correlation features and low-correlation features under the guidance of the global representations. Moreover, a novel Temporal Reciprocal Learning (TRL) mechanism is designed to sequentially enhance the high-correlation semantic information and accumulate the low-correlation sub-critical clues. Extensive experiments are conducted on three public benchmarks. The experimental results indicate that our approach can achieve better performance than other state-of-the-art approaches. The code is released at https://github.com/flysnowtiger/GRL.