 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowDistill: Scalable Traffic Flow Prediction via Distillation from LLMs
Apr 02, 2025Accurate traffic flow prediction is vital for optimizing urban mobility, yet it remains difficult in many cities due to complex spatio-temporal dependencies and limited high-quality data. While deep graph-based models demonstrate strong predictive power, their performance often comes at the cost of high computational overhead and substantial training data requirements, making them impractical for deployment in resource-constrained or data-scarce environments. We propose the FlowDistill, a lightweight and scalable traffic prediction framework based on knowledge distillation from large language models (LLMs). In this teacher-student setup, a fine-tuned LLM guides a compact multi-layer perceptron (MLP) student model using a novel combination of the information bottleneck principle and teacher-bounded regression loss, ensuring the distilled model retains only essential and transferable knowledge. Spatial and temporal correlations are explicitly encoded to enhance the model's generalization across diverse urban settings. Despite its simplicity, FlowDistill consistently outperforms state-of-the-art models in prediction accuracy while requiring significantly less training data, and achieving lower memory usage and inference latency, highlighting its efficiency and suitability for real-world, scalable deployment.
Harnessing LLMs for Cross-City OD Flow Prediction
Sep 05, 2024



Understanding and predicting Origin-Destination (OD) flows is crucial for urban planning and transportation management. Traditional OD prediction models, while effective within single cities, often face limitations when applied across different cities due to varied traffic conditions, urban layouts, and socio-economic factors. In this paper, by employing Large Language Models (LLMs), we introduce a new method for cross-city OD flow prediction. Our approach leverages the advanced semantic understanding and contextual learning capabilities of LLMs to bridge the gap between cities with different characteristics, providing a robust and adaptable solution for accurate OD flow prediction that can be transferred from one city to another. Our novel framework involves four major components: collecting OD training datasets from a source city, instruction-tuning the LLMs, predicting destination POIs in a target city, and identifying the locations that best match the predicted destination POIs. We introduce a new loss function that integrates POI semantics and trip distance during training. By extracting high-quality semantic features from human mobility and POI data, the model understands spatial and functional relationships within urban spaces and captures interactions between individuals and various POIs. Extensive experimental results demonstrate the superiority of our approach over the state-of-the-art learning-based methods in cross-city OD flow prediction.
MI^2GAN: Generative Adversarial Network for Medical Image Domain Adaptation using Mutual Information Constraint
Jul 30, 2020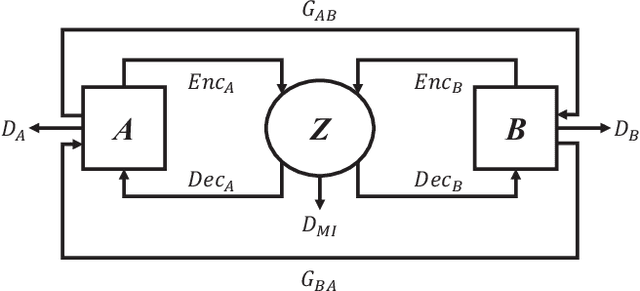
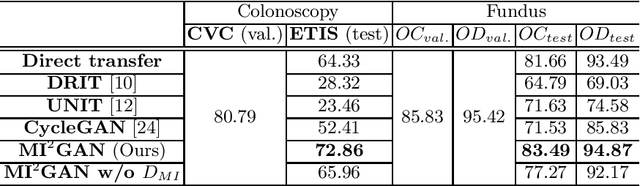
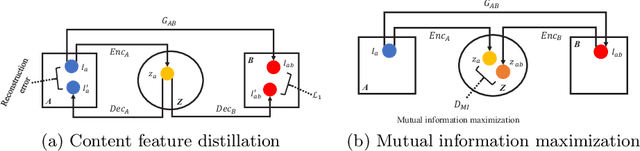
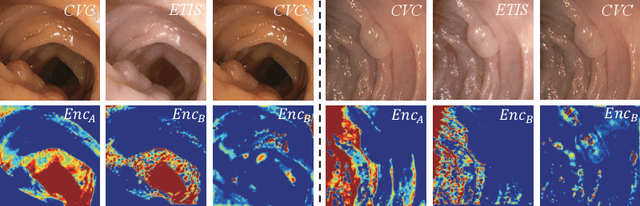
Domain shift between medical images from multicentres is still an open question for the community, which degrades the generalization performance of deep learning models. Generative adversarial network (GAN), which synthesize plausible images, is one of the potential solutions to address the problem. However, the existing GAN-based approaches are prone to fail at preserving image-objects in image-to-image (I2I) translation, which reduces their practicality on domain adaptation tasks. In this paper, we propose a novel GAN (namely MI$^2$GAN) to maintain image-contents during cross-domain I2I translation. Particularly, we disentangle the content features from domain information for both the source and translated images, and then maximize the mutual information between the disentangled content features to preserve the image-objects. The proposed MI$^2$GAN is evaluated on two tasks---polyp segmentation using colonoscopic images and the segmentation of optic disc and cup in fundus images. The experimental results demonstrate that the proposed MI$^2$GAN can not only generate elegant translated images, but also significantly improve the generalization performance of widely used deep learning networks (e.g., U-Net).
Instance-aware Self-supervised Learning for Nuclei Segmentation
Jul 22, 2020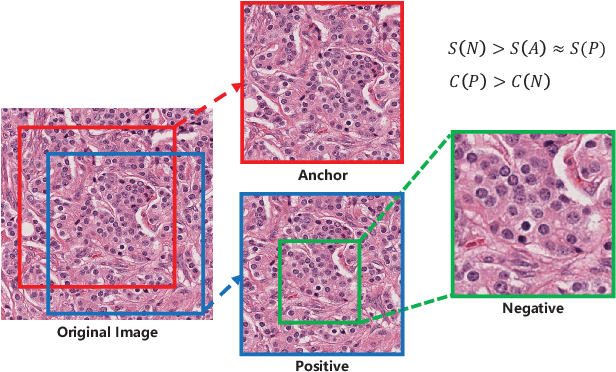
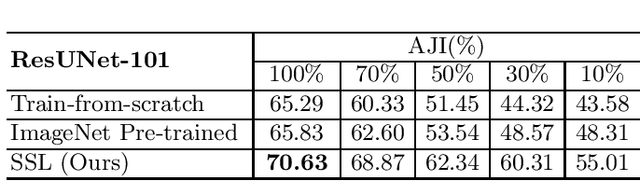
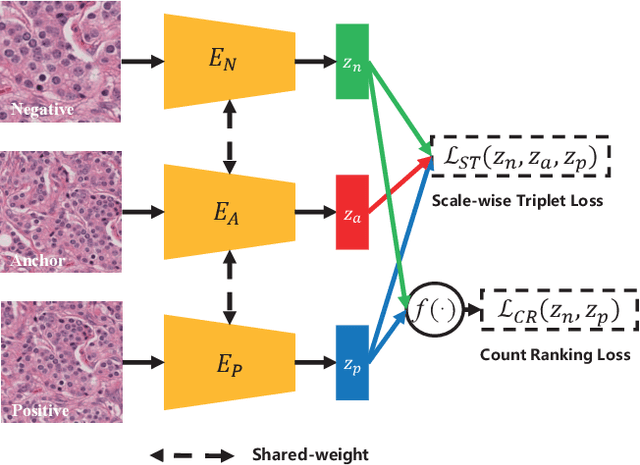
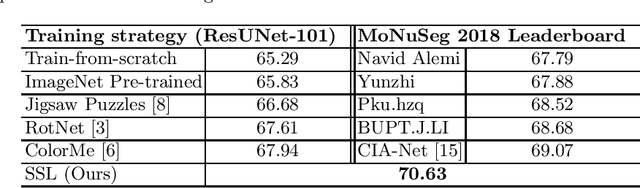
Due to the wide existence and large morphological variances of nuclei, accurate nuclei instance segmentation is still one of the most challenging tasks in computational pathology. The annotating of nuclei instances, requiring experienced pathologists to manually draw the contours, is extremely laborious and expensive, which often results in the deficiency of annotated data. The deep learning based segmentation approaches, which highly rely on the quantity of training data, are difficult to fully demonstrate their capacity in this area. In this paper, we propose a novel self-supervised learning framework to deeply exploit the capacity of widely-used convolutional neural networks (CNNs) on the nuclei instance segmentation task. The proposed approach involves two sub-tasks (i.e., scale-wise triplet learning and count ranking), which enable neural networks to implicitly leverage the prior-knowledge of nuclei size and quantity, and accordingly mine the instance-aware feature representations from the raw data. Experimental results on the publicly available MoNuSeg dataset show that the proposed self-supervised learning approach can remarkably boost the segmentation accuracy of nuclei instance---a new state-of-the-art average Aggregated Jaccard Index (AJI) of 70.63%, is achieved by our self-supervised ResUNet-101. To our best knowledge, this is the first work focusing on the self-supervised learning for instance segmentation.
Self-Loop Uncertainty: A Novel Pseudo-Label for Semi-Supervised Medical Image Segmentation
Jul 20, 2020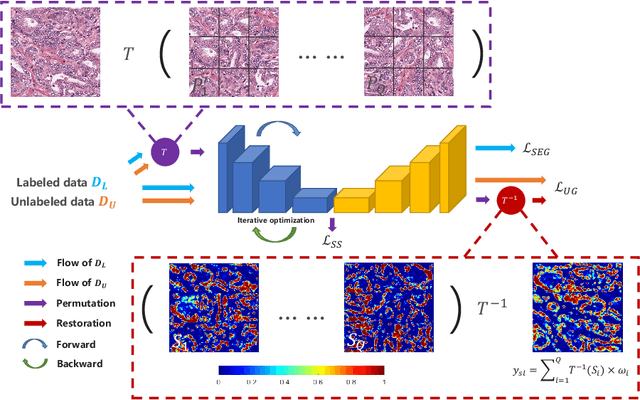

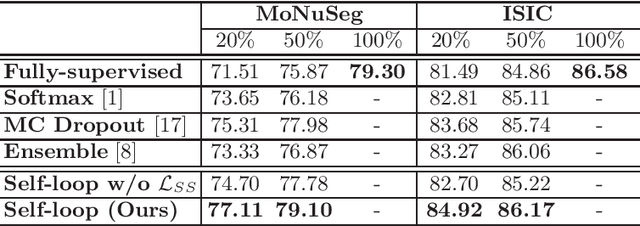
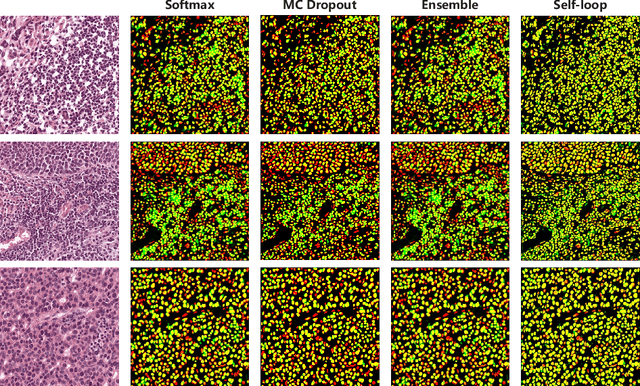
Witnessing the success of deep learning neural networks in natural image processing, an increasing number of studies have been proposed to develop deep-learning-based frameworks for medical image segmentation. However, since the pixel-wise annotation of medical images is laborious and expensive, the amount of annotated data is usually deficient to well-train a neural network. In this paper, we propose a semi-supervised approach to train neural networks with limited labeled data and a large quantity of unlabeled images for medical image segmentation. A novel pseudo-label (namely self-loop uncertainty), generated by recurrently optimizing the neural network with a self-supervised task, is adopted as the ground-truth for the unlabeled images to augment the training set and boost the segmentation accuracy. The proposed self-loop uncertainty can be seen as an approximation of the uncertainty estimation yielded by ensembling multiple models with a significant reduction of inference time. Experimental results on two publicly available datasets demonstrate the effectiveness of our semi-supervied approach.
Texture Deformation Based Generative Adversarial Networks for Face Editing
Dec 24, 2018
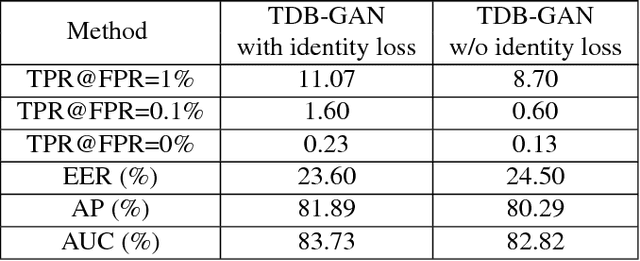
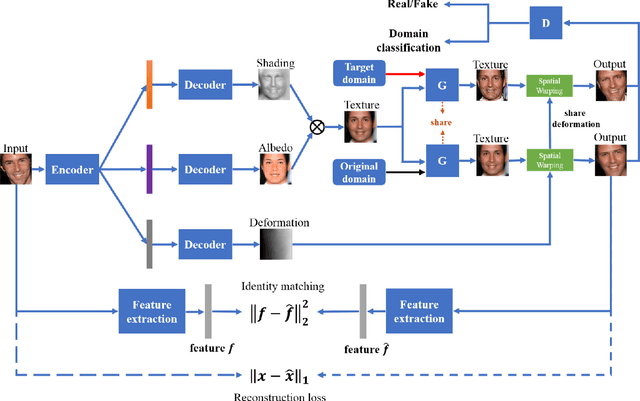
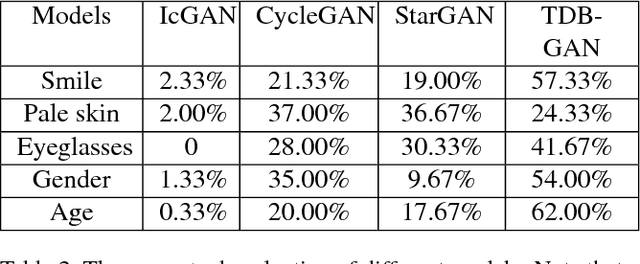
Despite the significant success in image-to-image translation and latent representation based facial attribute editing and expression synthesis, the existing approaches still have limitations in the sharpness of details, distinct image translation and identity preservation. To address these issues, we propose a Texture Deformation Based GAN, namely TDB-GAN, to disentangle texture from original image and transfers domains based on the extracted texture. The approach utilizes the texture to transfer facial attributes and expressions without the consideration of the object pose. This leads to shaper details and more distinct visual effect of the synthesized faces. In addition, it brings the faster convergence during training. The effectiveness of the proposed method is validated through extensive ablation studies. We also evaluate our approach qualitatively and quantitatively on facial attribute and facial expression synthesis. The results on both the CelebA and RaFD datasets suggest that Texture Deformation Based GAN achieves better performance.
Reversed Active Learning based Atrous DenseNet for Pathological Image Classification
Jul 06, 2018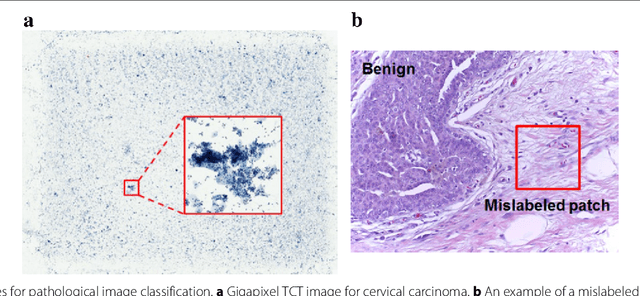
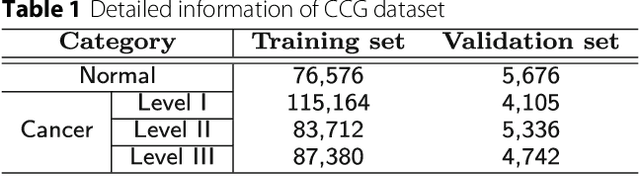
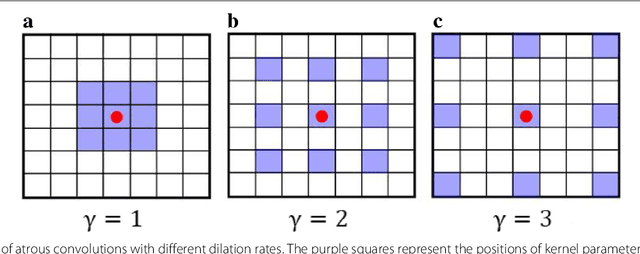
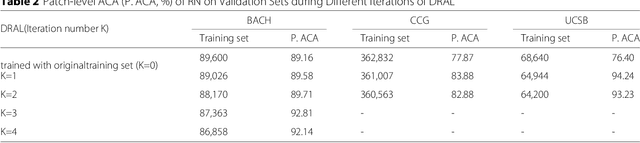
Witnessed the development of deep learning in recent years, increasing number of researches try to adopt deep learning model for medical image analysis. However, the usage of deep learning networks for the pathological image analysis encounters several challenges, e.g. high resolution (gigapixel) of pathological images and lack of annotations of cancer areas. To address the challenges, we proposed a complete framework for the pathological image classification, which consists of a novel training strategy, namely reversed active learning (RAL), and an advanced network, namely atrous DenseNet (ADN). The proposed RAL can remove the mislabel patches in the training set. The refined training set can then be used to train widely used deep learning networks, e.g. VGG-16, ResNets, etc. A novel deep learning network, i.e. atrous DenseNet (ADN), is also proposed for the classification of pathological images. The proposed ADN achieves multi-scale feature extraction by integrating the atrous convolutions to the Dense Block. The proposed RAL and ADN have been evaluated on two pathological datasets, i.e. BACH and CCG. The experimental results demonstrate the excellent performance of the proposed ADN + RAL framework, i.e. the average patch-level ACAs of 94.10% and 92.05% on BACH and CCG validation sets were achieved.
Active Learning for Breast Cancer Identification
Apr 18, 2018
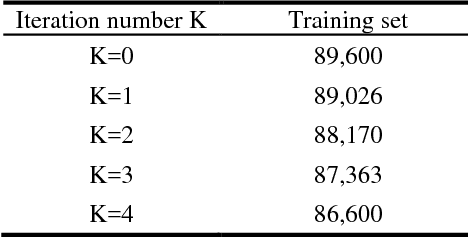
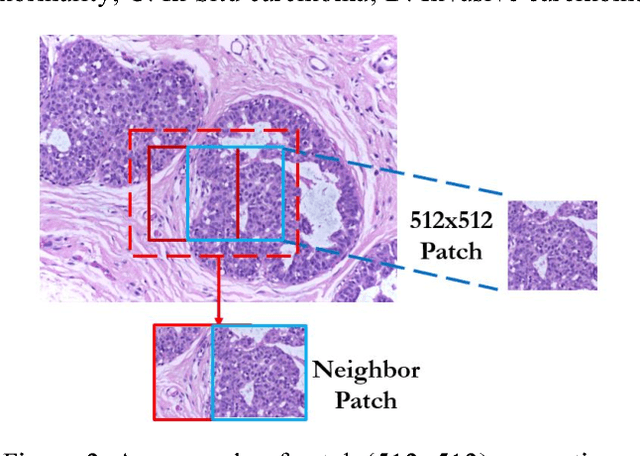
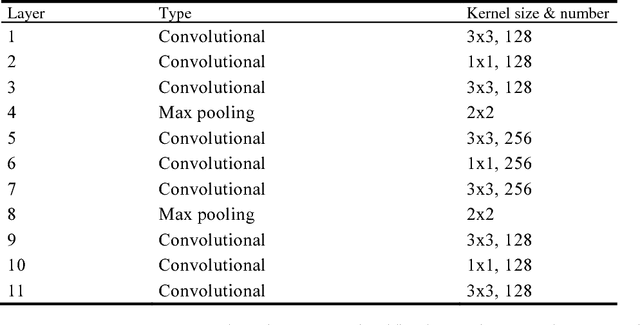
Breast cancer is the second most common malignancy among women and has become a major public health problem in current society. Traditional breast cancer identification requires experienced pathologists to carefully read the breast slice, which is laborious and suffers from inter-observer variations. Consequently, an automatic classification framework for breast cancer identification is worthwhile to develop. Recent years witnessed the development of deep learning technique. Increasing number of medical applications start to use deep learning to improve diagnosis accuracy. In this paper, we proposed a novel training strategy, namely reversed active learning (RAL), to train network to automatically classify breast cancer images. Our RAL is applied to the training set of a simple convolutional neural network (CNN) to remove mislabeled images. We evaluate the CNN trained with RAL on publicly available ICIAR 2018 Breast Cancer Dataset (IBCD). The experimental results show that our RAL increases the slice-based accuracy of CNN from 93.75% to 96.25%.