 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOther Tokens Matter: Exploring Global and Local Features of Vision Transformers for Object Re-Identification
Apr 23, 2024Object Re-Identification (Re-ID) aims to identify and retrieve specific objects from images captured at different places and times. Recently, object Re-ID has achieved great success with the advances of Vision Transformers (ViT). However, the effects of the global-local relation have not been fully explored in Transformers for object Re-ID. In this work, we first explore the influence of global and local features of ViT and then further propose a novel Global-Local Transformer (GLTrans) for high-performance object Re-ID. We find that the features from last few layers of ViT already have a strong representational ability, and the global and local information can mutually enhance each other. Based on this fact, we propose a Global Aggregation Encoder (GAE) to utilize the class tokens of the last few Transformer layers and learn comprehensive global features effectively. Meanwhile, we propose the Local Multi-layer Fusion (LMF) which leverages both the global cues from GAE and multi-layer patch tokens to explore the discriminative local representations. Extensive experiments demonstrate that our proposed method achieves superior performance on four object Re-ID benchmarks.
TF-CLIP: Learning Text-free CLIP for Video-based Person Re-Identification
Dec 15, 2023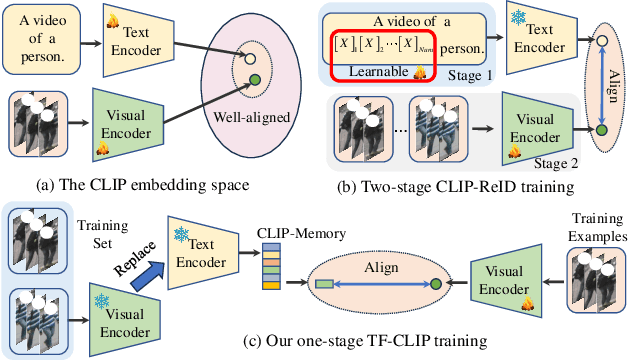
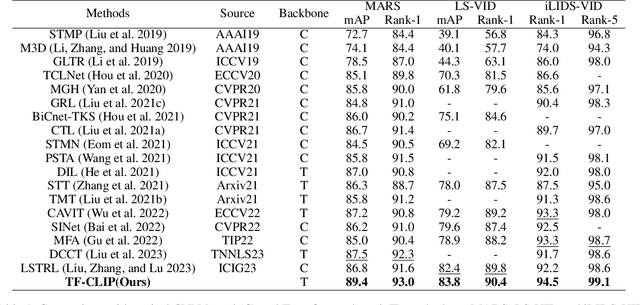
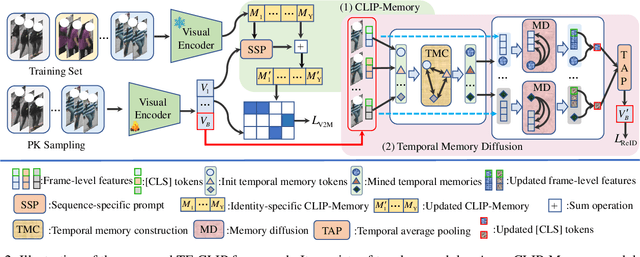

Large-scale language-image pre-trained models (e.g., CLIP) have shown superior performances on many cross-modal retrieval tasks. However, the problem of transferring the knowledge learned from such models to video-based person re-identification (ReID) has barely been explored. In addition, there is a lack of decent text descriptions in current ReID benchmarks. To address these issues, in this work, we propose a novel one-stage text-free CLIP-based learning framework named TF-CLIP for video-based person ReID. More specifically, we extract the identity-specific sequence feature as the CLIP-Memory to replace the text feature. Meanwhile, we design a Sequence-Specific Prompt (SSP) module to update the CLIP-Memory online. To capture temporal information, we further propose a Temporal Memory Diffusion (TMD) module, which consists of two key components: Temporal Memory Construction (TMC) and Memory Diffusion (MD). Technically, TMC allows the frame-level memories in a sequence to communicate with each other, and to extract temporal information based on the relations within the sequence. MD further diffuses the temporal memories to each token in the original features to obtain more robust sequence features. Extensive experiments demonstrate that our proposed method shows much better results than other state-of-the-art methods on MARS, LS-VID and iLIDS-VID. The code is available at https://github.com/AsuradaYuci/TF-CLIP.