 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Source-Channel Coding: Fundamentals and Recent Progress in Practical Designs
Paper and Code
Sep 26, 2024

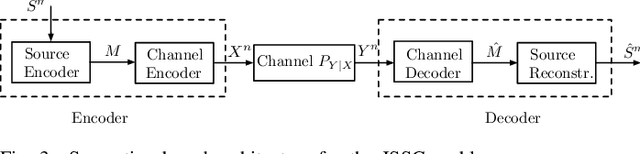

Semantic- and task-oriented communication has emerged as a promising approach to reducing the latency and bandwidth requirements of next-generation mobile networks by transmitting only the most relevant information needed to complete a specific task at the receiver. This is particularly advantageous for machine-oriented communication of high data rate content, such as images and videos, where the goal is rapid and accurate inference, rather than perfect signal reconstruction. While semantic- and task-oriented compression can be implemented in conventional communication systems, joint source-channel coding (JSCC) offers an alternative end-to-end approach by optimizing compression and channel coding together, or even directly mapping the source signal to the modulated waveform. Although all digital communication systems today rely on separation, thanks to its modularity, JSCC is known to achieve higher performance in finite blocklength scenarios, and to avoid cliff and the levelling-off effects in time-varying channel scenarios. This article provides an overview of the information theoretic foundations of JSCC, surveys practical JSCC designs over the decades, and discusses the reasons for their limited adoption in practical systems. We then examine the recent resurgence of JSCC, driven by the integration of deep learning techniques, particularly through DeepJSCC, highlighting its many surprising advantages in various scenarios. Finally, we discuss why it may be time to reconsider today's strictly separate architectures, and reintroduce JSCC to enable high-fidelity, low-latency communications in critical applications such as autonomous driving, drone surveillance, or wearable systems.