 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEA: Temporal Excitation and Aggregation for Action Recognition
Apr 03, 2020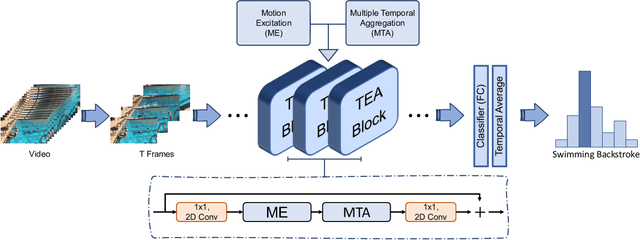
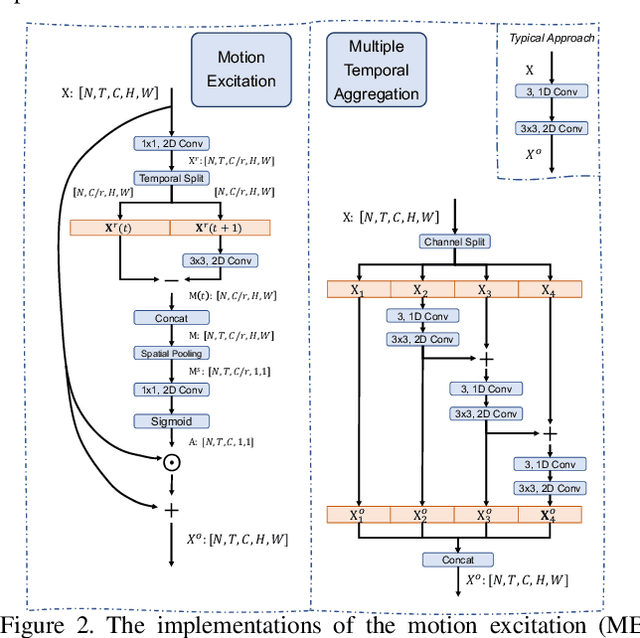
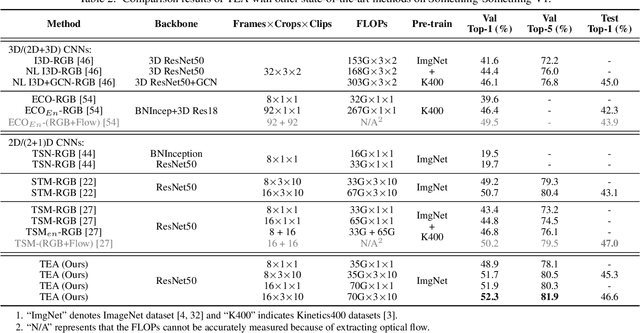
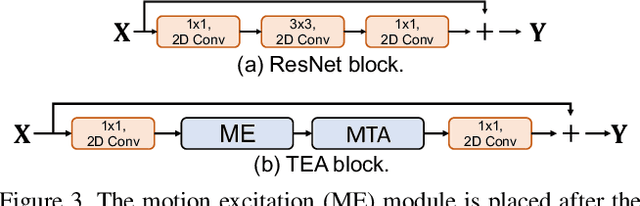
Temporal modeling is key for action recognition in videos. It normally considers both short-range motions and long-range aggregations. In this paper, we propose a Temporal Excitation and Aggregation (TEA) block, including a motion excitation (ME) module and a multiple temporal aggregation (MTA) module, specifically designed to capture both short- and long-range temporal evolution. In particular, for short-range motion modeling, the ME module calculates the feature-level temporal differences from spatiotemporal features. It then utilizes the differences to excite the motion-sensitive channels of the features. The long-range temporal aggregations in previous works are typically achieved by stacking a large number of local temporal convolutions. Each convolution processes a local temporal window at a time. In contrast, the MTA module proposes to deform the local convolution to a group of sub-convolutions, forming a hierarchical residual architecture. Without introducing additional parameters, the features will be processed with a series of sub-convolutions, and each frame could complete multiple temporal aggregations with neighborhoods. The final equivalent receptive field of temporal dimension is accordingly enlarged, which is capable of modeling the long-range temporal relationship over distant frames. The two components of the TEA block are complementary in temporal modeling. Finally, our approach achieves impressive results at low FLOPs on several action recognition benchmarks, such as Kinetics, Something-Something, HMDB51, and UCF101, which confirms its effectiveness and efficiency.