 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneGlue: Scene-Aware Transformer for Feature Matching without Scene-Level Annotation
Apr 15, 2026Local feature matching plays a critical role in understanding the correspondence between cross-view images. However, traditional methods are constrained by the inherent local nature of feature descriptors, limiting their ability to capture non-local scene information that is essential for accurate cross-view correspondence. In this paper, we introduce SceneGlue, a scene-aware feature matching framework designed to overcome these limitations. SceneGlue leverages a hybridizable matching paradigm that integrates implicit parallel attention and explicit cross-view visibility estimation. The parallel attention mechanism simultaneously exchanges information among local descriptors within and across images, enhancing the scene's global context. To further enrich the scene awareness, we propose the Visibility Transformer, which explicitly categorizes features into visible and invisible regions, providing an understanding of cross-view scene visibility. By combining explicit and implicit scene-level awareness, SceneGlue effectively compensates for the local descriptor constraints. Notably, SceneGlue is trained using only local feature matches, without requiring scene-level groundtruth annotations. This scene-aware approach not only improves accuracy and robustness but also enhances interpretability compared to traditional methods. Extensive experiments on applications such as homography estimation, pose estimation, image matching, and visual localization validate SceneGlue's superior performance. The source code is available at https://github.com/songlin-du/SceneGlue.
JamMa: Ultra-lightweight Local Feature Matching with Joint Mamba
Mar 05, 2025
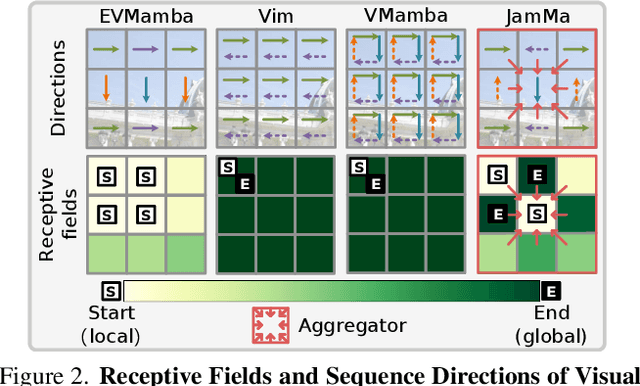
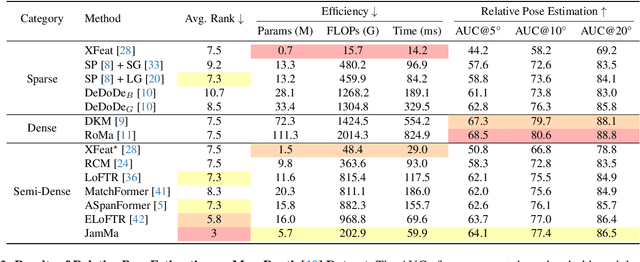
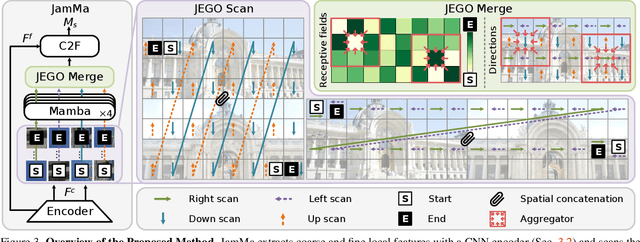
Existing state-of-the-art feature matchers capture long-range dependencies with Transformers but are hindered by high spatial complexity, leading to demanding training and highlatency inference. Striking a better balance between performance and efficiency remains a challenge in feature matching. Inspired by the linear complexity O(N) of Mamba, we propose an ultra-lightweight Mamba-based matcher, named JamMa, which converges on a single GPU and achieves an impressive performance-efficiency balance in inference. To unlock the potential of Mamba for feature matching, we propose Joint Mamba with a scan-merge strategy named JEGO, which enables: (1) Joint scan of two images to achieve high-frequency mutual interaction, (2) Efficient scan with skip steps to reduce sequence length, (3) Global receptive field, and (4) Omnidirectional feature representation. With the above properties, the JEGO strategy significantly outperforms the scan-merge strategies proposed in VMamba and EVMamba in the feature matching task. Compared to attention-based sparse and semi-dense matchers, JamMa demonstrates a superior balance between performance and efficiency, delivering better performance with less than 50% of the parameters and FLOPs.
Raising the Ceiling: Conflict-Free Local Feature Matching with Dynamic View Switching
Jul 10, 2024



Current feature matching methods prioritize improving modeling capabilities to better align outputs with ground-truth matches, which are the theoretical upper bound on matching results, metaphorically depicted as the "ceiling". However, these enhancements fail to address the underlying issues that directly hinder ground-truth matches, including the scarcity of matchable points in small scale images, matching conflicts in dense methods, and the keypoint-repeatability reliance in sparse methods. We propose a novel feature matching method named RCM, which Raises the Ceiling of Matching from three aspects. 1) RCM introduces a dynamic view switching mechanism to address the scarcity of matchable points in source images by strategically switching image pairs. 2) RCM proposes a conflict-free coarse matching module, addressing matching conflicts in the target image through a many-to-one matching strategy. 3) By integrating the semi-sparse paradigm and the coarse-to-fine architecture, RCM preserves the benefits of both high efficiency and global search, mitigating the reliance on keypoint repeatability. As a result, RCM enables more matchable points in the source image to be matched in an exhaustive and conflict-free manner in the target image, leading to a substantial 260% increase in ground-truth matches. Comprehensive experiments show that RCM exhibits remarkable performance and efficiency in comparison to state-of-the-art methods.
Scene-Aware Feature Matching
Aug 22, 2023



Current feature matching methods focus on point-level matching, pursuing better representation learning of individual features, but lacking further understanding of the scene. This results in significant performance degradation when handling challenging scenes such as scenes with large viewpoint and illumination changes. To tackle this problem, we propose a novel model named SAM, which applies attentional grouping to guide Scene-Aware feature Matching. SAM handles multi-level features, i.e., image tokens and group tokens, with attention layers, and groups the image tokens with the proposed token grouping module. Our model can be trained by ground-truth matches only and produce reasonable grouping results. With the sense-aware grouping guidance, SAM is not only more accurate and robust but also more interpretable than conventional feature matching models. Sufficient experiments on various applications, including homography estimation, pose estimation, and image matching, demonstrate that our model achieves state-of-the-art performance.
ParaFormer: Parallel Attention Transformer for Efficient Feature Matching
Mar 10, 2023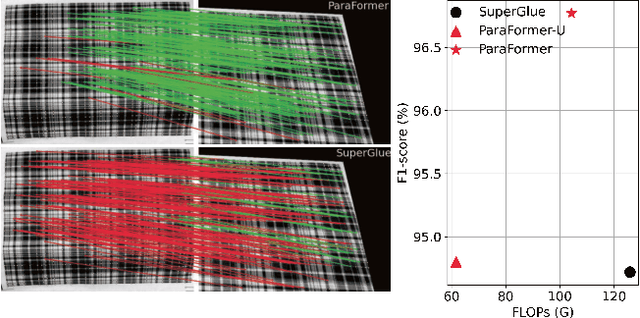
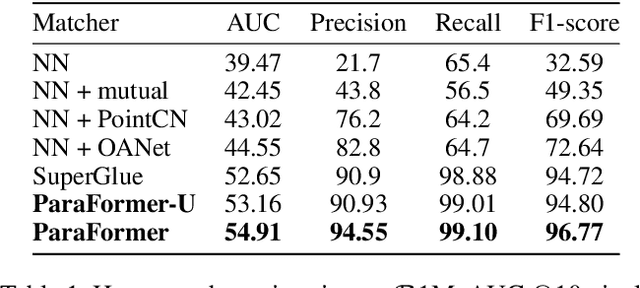
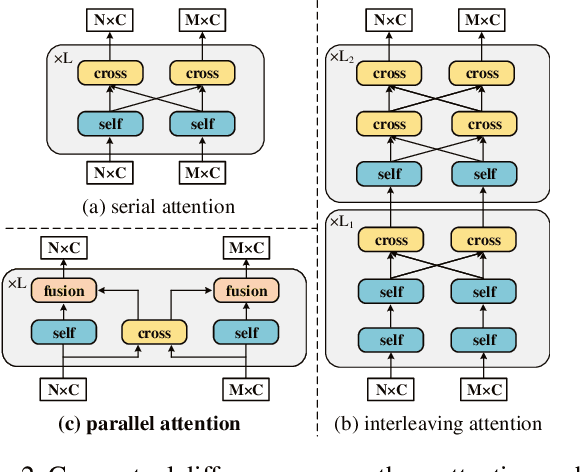
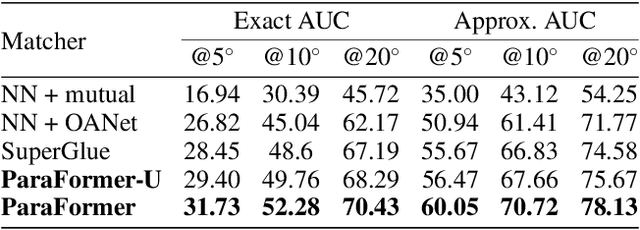
Heavy computation is a bottleneck limiting deep-learningbased feature matching algorithms to be applied in many realtime applications. However, existing lightweight networks optimized for Euclidean data cannot address classical feature matching tasks, since sparse keypoint based descriptors are expected to be matched. This paper tackles this problem and proposes two concepts: 1) a novel parallel attention model entitled ParaFormer and 2) a graph based U-Net architecture with attentional pooling. First, ParaFormer fuses features and keypoint positions through the concept of amplitude and phase, and integrates self- and cross-attention in a parallel manner which achieves a win-win performance in terms of accuracy and efficiency. Second, with U-Net architecture and proposed attentional pooling, the ParaFormer-U variant significantly reduces computational complexity, and minimize performance loss caused by downsampling. Sufficient experiments on various applications, including homography estimation, pose estimation, and image matching, demonstrate that ParaFormer achieves state-of-the-art performance while maintaining high efficiency. The efficient ParaFormer-U variant achieves comparable performance with less than 50% FLOPs of the existing attention-based models.