 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Augmentation Framework for Anomaly Detection
Aug 31, 2023Data augmentation methods are commonly integrated into the training of anomaly detection models. Previous approaches have primarily focused on replicating real-world anomalies or enhancing diversity, without considering that the standard of anomaly varies across different classes, potentially leading to a biased training distribution.This paper analyzes crucial traits of simulated anomalies that contribute to the training of reconstructive networks and condenses them into several methods, thus creating a comprehensive framework by selectively utilizing appropriate combinations.Furthermore, we integrate this framework with a reconstruction-based approach and concurrently propose a split training strategy that alleviates the issue of overfitting while avoiding introducing interference to the reconstruction process. The evaluations conducted on the MVTec anomaly detection dataset demonstrate that our method outperforms the previous state-of-the-art approach, particularly in terms of object classes. To evaluate generalizability, we generate a simulated dataset comprising anomalies with diverse characteristics since the original test samples only include specific types of anomalies and may lead to biased evaluations. Experimental results demonstrate that our approach exhibits promising potential for generalizing effectively to various unforeseen anomalies encountered in real-world scenarios.
Scene-Aware Feature Matching
Aug 22, 2023



Current feature matching methods focus on point-level matching, pursuing better representation learning of individual features, but lacking further understanding of the scene. This results in significant performance degradation when handling challenging scenes such as scenes with large viewpoint and illumination changes. To tackle this problem, we propose a novel model named SAM, which applies attentional grouping to guide Scene-Aware feature Matching. SAM handles multi-level features, i.e., image tokens and group tokens, with attention layers, and groups the image tokens with the proposed token grouping module. Our model can be trained by ground-truth matches only and produce reasonable grouping results. With the sense-aware grouping guidance, SAM is not only more accurate and robust but also more interpretable than conventional feature matching models. Sufficient experiments on various applications, including homography estimation, pose estimation, and image matching, demonstrate that our model achieves state-of-the-art performance.
ParaFormer: Parallel Attention Transformer for Efficient Feature Matching
Mar 10, 2023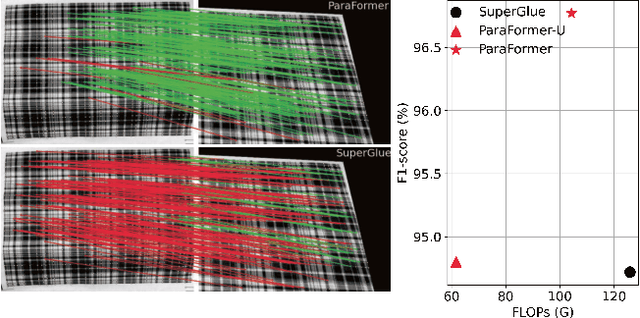
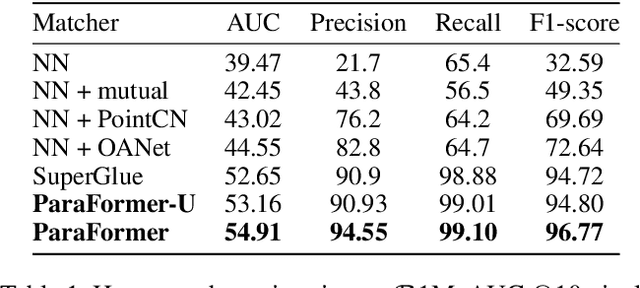
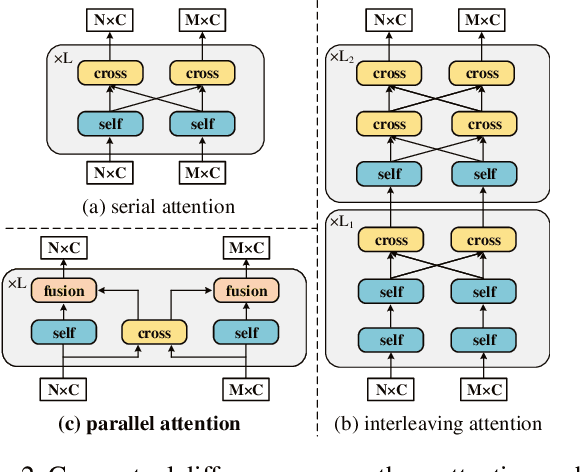
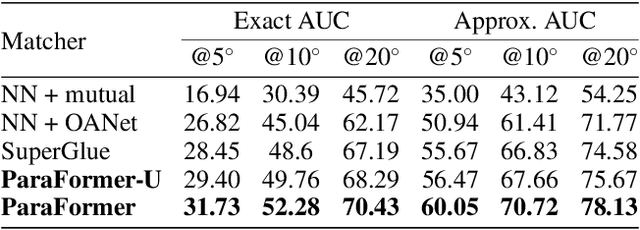
Heavy computation is a bottleneck limiting deep-learningbased feature matching algorithms to be applied in many realtime applications. However, existing lightweight networks optimized for Euclidean data cannot address classical feature matching tasks, since sparse keypoint based descriptors are expected to be matched. This paper tackles this problem and proposes two concepts: 1) a novel parallel attention model entitled ParaFormer and 2) a graph based U-Net architecture with attentional pooling. First, ParaFormer fuses features and keypoint positions through the concept of amplitude and phase, and integrates self- and cross-attention in a parallel manner which achieves a win-win performance in terms of accuracy and efficiency. Second, with U-Net architecture and proposed attentional pooling, the ParaFormer-U variant significantly reduces computational complexity, and minimize performance loss caused by downsampling. Sufficient experiments on various applications, including homography estimation, pose estimation, and image matching, demonstrate that ParaFormer achieves state-of-the-art performance while maintaining high efficiency. The efficient ParaFormer-U variant achieves comparable performance with less than 50% FLOPs of the existing attention-based models.