 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDFit: 3D Object Pose and Shape by Fitting a Morphable SDF to a Single Image
Paper and Code
Sep 24, 2024
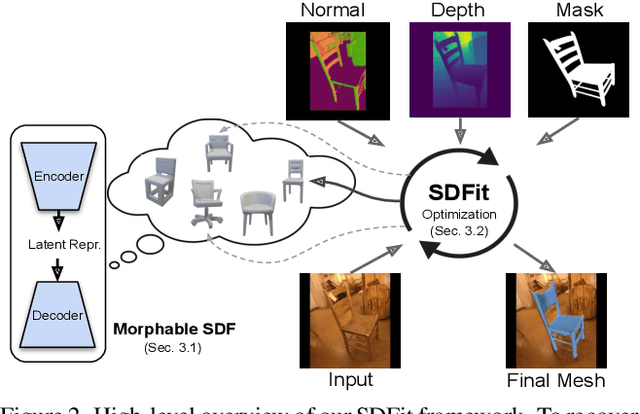


We focus on recovering 3D object pose and shape from single images. This is highly challenging due to strong (self-)occlusions, depth ambiguities, the enormous shape variance, and lack of 3D ground truth for natural images. Recent work relies mostly on learning from finite datasets, so it struggles generalizing, while it focuses mostly on the shape itself, largely ignoring the alignment with pixels. Moreover, it performs feed-forward inference, so it cannot refine estimates. We tackle these limitations with a novel framework, called SDFit. To this end, we make three key observations: (1) Learned signed-distance-function (SDF) models act as a strong morphable shape prior. (2) Foundational models embed 2D images and 3D shapes in a joint space, and (3) also infer rich features from images. SDFit exploits these as follows. First, it uses a category-level morphable SDF (mSDF) model, called DIT, to generate 3D shape hypotheses. This mSDF is initialized by querying OpenShape's latent space conditioned on the input image. Then, it computes 2D-to-3D correspondences, by extracting and matching features from the image and mSDF. Last, it fits the mSDF to the image in an render-and-compare fashion, to iteratively refine estimates. We evaluate SDFit on the Pix3D and Pascal3D+ datasets of real-world images. SDFit performs roughly on par with state-of-the-art learned methods, but, uniquely, requires no re-training. Thus, SDFit is promising for generalizing in the wild, paving the way for future research. Code will be released