 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Semantic Encoders Can Harm Relighting Performance: Probing Visual Priors via Augmented Latent Intrinsics
Feb 01, 2026Image-to-image relighting requires representations that disentangle scene properties from illumination. Recent methods rely on latent intrinsic representations but remain under-constrained and often fail on challenging materials such as metal and glass. A natural hypothesis is that stronger pretrained visual priors should resolve these failures. We find the opposite: features from top-performing semantic encoders often degrade relighting quality, revealing a fundamental trade-off between semantic abstraction and photometric fidelity. We study this trade-off and introduce Augmented Latent Intrinsics (ALI), which balances semantic context and dense photometric structure by fusing features from a pixel-aligned visual encoder into a latent-intrinsic framework, together with a self-supervised refinement strategy to mitigate the scarcity of paired real-world data. Trained only on unlabeled real-world image pairs and paired with a dense, pixel-aligned visual prior, ALI achieves strong improvements in relighting, with the largest gains on complex, specular materials. Project page: https:\\augmented-latent-intrinsics.github.io
Chorus: Multi-Teacher Pretraining for Holistic 3D Gaussian Scene Encoding
Dec 22, 2025While 3DGS has emerged as a high-fidelity scene representation, encoding rich, general-purpose features directly from its primitives remains under-explored. We address this gap by introducing Chorus, a multi-teacher pretraining framework that learns a holistic feed-forward 3D Gaussian Splatting (3DGS) scene encoder by distilling complementary signals from 2D foundation models. Chorus employs a shared 3D encoder and teacher-specific projectors to learn from language-aligned, generalist, and object-aware teachers, encouraging a shared embedding space that captures signals from high-level semantics to fine-grained structure. We evaluate Chorus on a wide range of tasks: open-vocabulary semantic and instance segmentation, linear and decoder probing, as well as data-efficient supervision. Besides 3DGS, we also test Chorus on several benchmarks that only support point clouds by pretraining a variant using only Gaussians' centers, colors, estimated normals as inputs. Interestingly, this encoder shows strong transfer and outperforms the point clouds baseline while using 39.9 times fewer training scenes. Finally, we propose a render-and-distill adaptation that facilitates out-of-domain finetuning. Our code and model will be released upon publication.
Grab-3D: Detecting AI-Generated Videos from 3D Geometric Temporal Consistency
Dec 15, 2025Recent advances in diffusion-based generation techniques enable AI models to produce highly realistic videos, heightening the need for reliable detection mechanisms. However, existing detection methods provide only limited exploration of the 3D geometric patterns present in generated videos. In this paper, we use vanishing points as an explicit representation of 3D geometry patterns, revealing fundamental discrepancies in geometric consistency between real and AI-generated videos. We introduce Grab-3D, a geometry-aware transformer framework for detecting AI-generated videos based on 3D geometric temporal consistency. To enable reliable evaluation, we construct an AI-generated video dataset of static scenes, allowing stable 3D geometric feature extraction. We propose a geometry-aware transformer equipped with geometric positional encoding, temporal-geometric attention, and an EMA-based geometric classifier head to explicitly inject 3D geometric awareness into temporal modeling. Experiments demonstrate that Grab-3D significantly outperforms state-of-the-art detectors, achieving robust cross-domain generalization to unseen generators.
Edge-Centric Relational Reasoning for 3D Scene Graph Prediction
Nov 19, 2025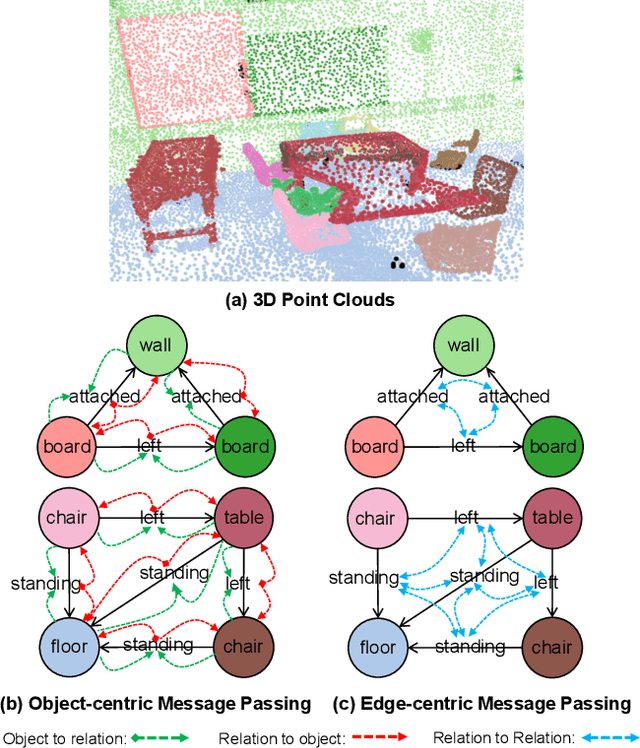
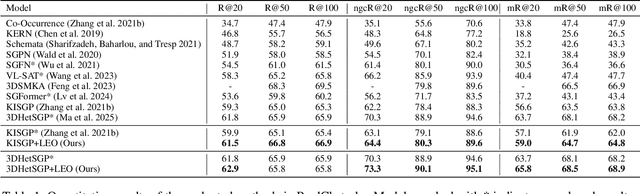
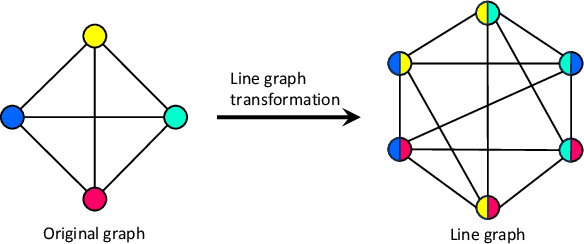
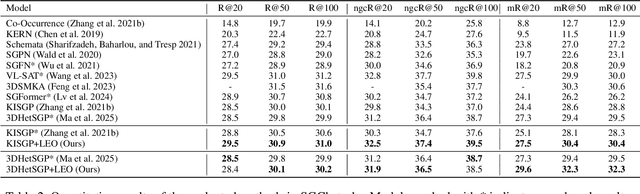
3D scene graph prediction aims to abstract complex 3D environments into structured graphs consisting of objects and their pairwise relationships. Existing approaches typically adopt object-centric graph neural networks, where relation edge features are iteratively updated by aggregating messages from connected object nodes. However, this design inherently restricts relation representations to pairwise object context, making it difficult to capture high-order relational dependencies that are essential for accurate relation prediction. To address this limitation, we propose a Link-guided Edge-centric relational reasoning framework with Object-aware fusion, namely LEO, which enables progressive reasoning from relation-level context to object-level understanding. Specifically, LEO first predicts potential links between object pairs to suppress irrelevant edges, and then transforms the original scene graph into a line graph where each relation is treated as a node. A line graph neural network is applied to perform edge-centric relational reasoning to capture inter-relation context. The enriched relation features are subsequently integrated into the original object-centric graph to enhance object-level reasoning and improve relation prediction. Our framework is model-agnostic and can be integrated with any existing object-centric method. Experiments on the 3DSSG dataset with two competitive baselines show consistent improvements, highlighting the effectiveness of our edge-to-object reasoning paradigm.
SceneSplat++: A Large Dataset and Comprehensive Benchmark for Language Gaussian Splatting
Jun 10, 20253D Gaussian Splatting (3DGS) serves as a highly performant and efficient encoding of scene geometry, appearance, and semantics. Moreover, grounding language in 3D scenes has proven to be an effective strategy for 3D scene understanding. Current Language Gaussian Splatting line of work fall into three main groups: (i) per-scene optimization-based, (ii) per-scene optimization-free, and (iii) generalizable approach. However, most of them are evaluated only on rendered 2D views of a handful of scenes and viewpoints close to the training views, limiting ability and insight into holistic 3D understanding. To address this gap, we propose the first large-scale benchmark that systematically assesses these three groups of methods directly in 3D space, evaluating on 1060 scenes across three indoor datasets and one outdoor dataset. Benchmark results demonstrate a clear advantage of the generalizable paradigm, particularly in relaxing the scene-specific limitation, enabling fast feed-forward inference on novel scenes, and achieving superior segmentation performance. We further introduce GaussianWorld-49K a carefully curated 3DGS dataset comprising around 49K diverse indoor and outdoor scenes obtained from multiple sources, with which we demonstrate the generalizable approach could harness strong data priors. Our codes, benchmark, and datasets will be made public to accelerate research in generalizable 3DGS scene understanding.
Gaussian Mapping for Evolving Scenes
Jun 07, 2025Mapping systems with novel view synthesis (NVS) capabilities are widely used in computer vision, with augmented reality, robotics, and autonomous driving applications. Most notably, 3D Gaussian Splatting-based systems show high NVS performance; however, many current approaches are limited to static scenes. While recent works have started addressing short-term dynamics (motion within the view of the camera), long-term dynamics (the scene evolving through changes out of view) remain less explored. To overcome this limitation, we introduce a dynamic scene adaptation mechanism that continuously updates the 3D representation to reflect the latest changes. In addition, since maintaining geometric and semantic consistency remains challenging due to stale observations disrupting the reconstruction process, we propose a novel keyframe management mechanism that discards outdated observations while preserving as much information as possible. We evaluate Gaussian Mapping for Evolving Scenes (GaME) on both synthetic and real-world datasets and find it to be more accurate than the state of the art.
LumiNet: Latent Intrinsics Meets Diffusion Models for Indoor Scene Relighting
Dec 03, 2024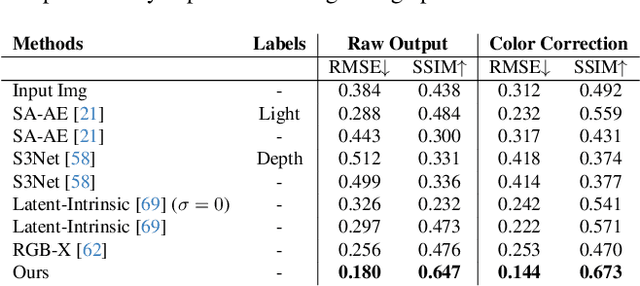



We introduce LumiNet, a novel architecture that leverages generative models and latent intrinsic representations for effective lighting transfer. Given a source image and a target lighting image, LumiNet synthesizes a relit version of the source scene that captures the target's lighting. Our approach makes two key contributions: a data curation strategy from the StyleGAN-based relighting model for our training, and a modified diffusion-based ControlNet that processes both latent intrinsic properties from the source image and latent extrinsic properties from the target image. We further improve lighting transfer through a learned adaptor (MLP) that injects the target's latent extrinsic properties via cross-attention and fine-tuning. Unlike traditional ControlNet, which generates images with conditional maps from a single scene, LumiNet processes latent representations from two different images - preserving geometry and albedo from the source while transferring lighting characteristics from the target. Experiments demonstrate that our method successfully transfers complex lighting phenomena including specular highlights and indirect illumination across scenes with varying spatial layouts and materials, outperforming existing approaches on challenging indoor scenes using only images as input.
MAGiC-SLAM: Multi-Agent Gaussian Globally Consistent SLAM
Nov 25, 2024
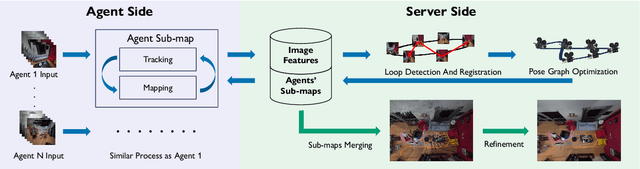
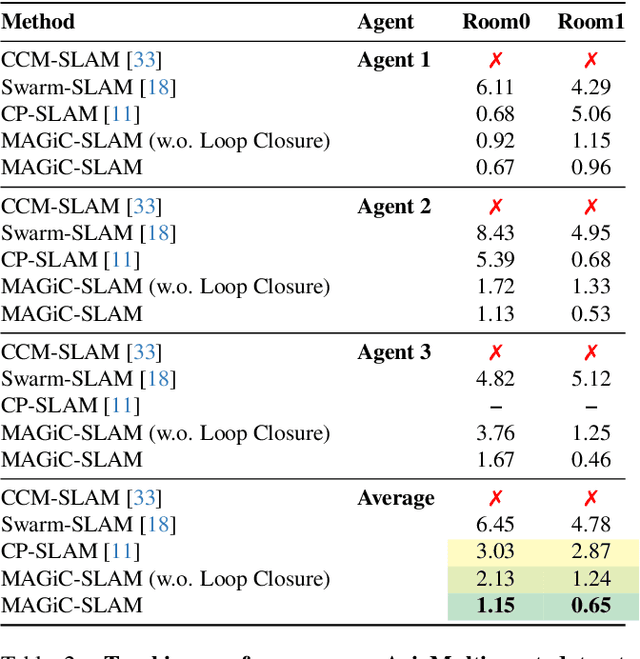

Simultaneous localization and mapping (SLAM) systems with novel view synthesis capabilities are widely used in computer vision, with applications in augmented reality, robotics, and autonomous driving. However, existing approaches are limited to single-agent operation. Recent work has addressed this problem using a distributed neural scene representation. Unfortunately, existing methods are slow, cannot accurately render real-world data, are restricted to two agents, and have limited tracking accuracy. In contrast, we propose a rigidly deformable 3D Gaussian-based scene representation that dramatically speeds up the system. However, improving tracking accuracy and reconstructing a globally consistent map from multiple agents remains challenging due to trajectory drift and discrepancies across agents' observations. Therefore, we propose new tracking and map-merging mechanisms and integrate loop closure in the Gaussian-based SLAM pipeline. We evaluate MAGiC-SLAM on synthetic and real-world datasets and find it more accurate and faster than the state of the art.
FewViewGS: Gaussian Splatting with Few View Matching and Multi-stage Training
Nov 04, 2024



The field of novel view synthesis from images has seen rapid advancements with the introduction of Neural Radiance Fields (NeRF) and more recently with 3D Gaussian Splatting. Gaussian Splatting became widely adopted due to its efficiency and ability to render novel views accurately. While Gaussian Splatting performs well when a sufficient amount of training images are available, its unstructured explicit representation tends to overfit in scenarios with sparse input images, resulting in poor rendering performance. To address this, we present a 3D Gaussian-based novel view synthesis method using sparse input images that can accurately render the scene from the viewpoints not covered by the training images. We propose a multi-stage training scheme with matching-based consistency constraints imposed on the novel views without relying on pre-trained depth estimation or diffusion models. This is achieved by using the matches of the available training images to supervise the generation of the novel views sampled between the training frames with color, geometry, and semantic losses. In addition, we introduce a locality preserving regularization for 3D Gaussians which removes rendering artifacts by preserving the local color structure of the scene. Evaluation on synthetic and real-world datasets demonstrates competitive or superior performance of our method in few-shot novel view synthesis compared to existing state-of-the-art methods.
SDFit: 3D Object Pose and Shape by Fitting a Morphable SDF to a Single Image
Sep 24, 2024
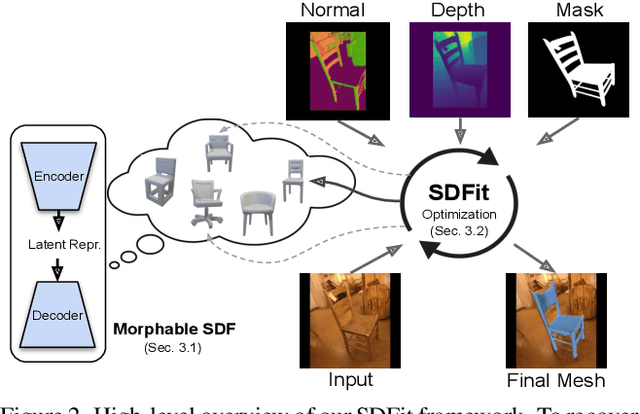


We focus on recovering 3D object pose and shape from single images. This is highly challenging due to strong (self-)occlusions, depth ambiguities, the enormous shape variance, and lack of 3D ground truth for natural images. Recent work relies mostly on learning from finite datasets, so it struggles generalizing, while it focuses mostly on the shape itself, largely ignoring the alignment with pixels. Moreover, it performs feed-forward inference, so it cannot refine estimates. We tackle these limitations with a novel framework, called SDFit. To this end, we make three key observations: (1) Learned signed-distance-function (SDF) models act as a strong morphable shape prior. (2) Foundational models embed 2D images and 3D shapes in a joint space, and (3) also infer rich features from images. SDFit exploits these as follows. First, it uses a category-level morphable SDF (mSDF) model, called DIT, to generate 3D shape hypotheses. This mSDF is initialized by querying OpenShape's latent space conditioned on the input image. Then, it computes 2D-to-3D correspondences, by extracting and matching features from the image and mSDF. Last, it fits the mSDF to the image in an render-and-compare fashion, to iteratively refine estimates. We evaluate SDFit on the Pix3D and Pascal3D+ datasets of real-world images. SDFit performs roughly on par with state-of-the-art learned methods, but, uniquely, requires no re-training. Thus, SDFit is promising for generalizing in the wild, paving the way for future research. Code will be released