 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNGL-Prompter: Training-Free Sewing Pattern Estimation from a Single Image
Feb 24, 2026Estimating sewing patterns from images is a practical approach for creating high-quality 3D garments. Due to the lack of real-world pattern-image paired data, prior approaches fine-tune large vision language models (VLMs) on synthetic garment datasets generated by randomly sampling from a parametric garment model GarmentCode. However, these methods often struggle to generalize to in-the-wild images, fail to capture real-world correlations between garment parts, and are typically restricted to single-layer outfits. In contrast, we observe that VLMs are effective at describing garments in natural language, yet perform poorly when asked to directly regress GarmentCode parameters from images. To bridge this gap, we propose NGL (Natural Garment Language), a novel intermediate language that restructures GarmentCode into a representation more understandable to language models. Leveraging this language, we introduce NGL-Prompter, a training-free pipeline that queries large VLMs to extract structured garment parameters, which are then deterministically mapped to valid GarmentCode. We evaluate our method on the Dress4D, CloSe and a newly collected dataset of approximately 5,000 in-the-wild fashion images. Our approach achieves state-of-the-art performance on standard geometry metrics and is strongly preferred in both human and GPT-based perceptual evaluations compared to existing baselines. Furthermore, NGL-prompter can recover multi-layer outfits whereas competing methods focus mostly on single-layer garments, highlighting its strong generalization to real-world images even with occluded parts. These results demonstrate that accurate sewing pattern reconstruction is possible without costly model training. Our code and data will be released for research use.
NeuralFur: Animal Fur Reconstruction From Multi-View Images
Jan 18, 2026Reconstructing realistic animal fur geometry from images is a challenging task due to the fine-scale details, self-occlusion, and view-dependent appearance of fur. In contrast to human hairstyle reconstruction, there are also no datasets that can be leveraged to learn a fur prior for different animals. In this work, we present a first multi-view-based method for high-fidelity 3D fur modeling of animals using a strand-based representation, leveraging the general knowledge of a vision language model. Given multi-view RGB images, we first reconstruct a coarse surface geometry using traditional multi-view stereo techniques. We then use a vision language model (VLM) system to retrieve information about the realistic length structure of the fur for each part of the body. We use this knowledge to construct the animal's furless geometry and grow strands atop it. The fur reconstruction is supervised with both geometric and photometric losses computed from multi-view images. To mitigate orientation ambiguities stemming from the Gabor filters that are applied to the input images, we additionally utilize the VLM to guide the strands' growth direction and their relation to the gravity vector that we incorporate as a loss. With this new schema of using a VLM to guide 3D reconstruction from multi-view inputs, we show generalization across a variety of animals with different fur types. For additional results and code, please refer to https://neuralfur.is.tue.mpg.de.
BEDLAM2.0: Synthetic Humans and Cameras in Motion
Nov 18, 2025Inferring 3D human motion from video remains a challenging problem with many applications. While traditional methods estimate the human in image coordinates, many applications require human motion to be estimated in world coordinates. This is particularly challenging when there is both human and camera motion. Progress on this topic has been limited by the lack of rich video data with ground truth human and camera movement. We address this with BEDLAM2.0, a new dataset that goes beyond the popular BEDLAM dataset in important ways. In addition to introducing more diverse and realistic cameras and camera motions, BEDLAM2.0 increases diversity and realism of body shape, motions, clothing, hair, and 3D environments. Additionally, it adds shoes, which were missing in BEDLAM. BEDLAM has become a key resource for training 3D human pose and motion regressors today and we show that BEDLAM2.0 is significantly better, particularly for training methods that estimate humans in world coordinates. We compare state-of-the art methods trained on BEDLAM and BEDLAM2.0, and find that BEDLAM2.0 significantly improves accuracy over BEDLAM. For research purposes, we provide the rendered videos, ground truth body parameters, and camera motions. We also provide the 3D assets to which we have rights and links to those from third parties.
MAMMA: Markerless & Automatic Multi-Person Motion Action Capture
Jun 16, 2025We present MAMMA, a markerless motion-capture pipeline that accurately recovers SMPL-X parameters from multi-view video of two-person interaction sequences. Traditional motion-capture systems rely on physical markers. Although they offer high accuracy, their requirements of specialized hardware, manual marker placement, and extensive post-processing make them costly and time-consuming. Recent learning-based methods attempt to overcome these limitations, but most are designed for single-person capture, rely on sparse keypoints, or struggle with occlusions and physical interactions. In this work, we introduce a method that predicts dense 2D surface landmarks conditioned on segmentation masks, enabling person-specific correspondence estimation even under heavy occlusion. We employ a novel architecture that exploits learnable queries for each landmark. We demonstrate that our approach can handle complex person--person interaction and offers greater accuracy than existing methods. To train our network, we construct a large, synthetic multi-view dataset combining human motions from diverse sources, including extreme poses, hand motions, and close interactions. Our dataset yields high-variability synthetic sequences with rich body contact and occlusion, and includes SMPL-X ground-truth annotations with dense 2D landmarks. The result is a system capable of capturing human motion without the need for markers. Our approach offers competitive reconstruction quality compared to commercial marker-based motion-capture solutions, without the extensive manual cleanup. Finally, we address the absence of common benchmarks for dense-landmark prediction and markerless motion capture by introducing two evaluation settings built from real multi-view sequences. We will release our dataset, benchmark, method, training code, and pre-trained model weights for research purposes.
ContourCraft: Learning to Resolve Intersections in Neural Multi-Garment Simulations
May 15, 2024Learning-based approaches to cloth simulation have started to show their potential in recent years. However, handling collisions and intersections in neural simulations remains a largely unsolved problem. In this work, we present \moniker{}, a learning-based solution for handling intersections in neural cloth simulations. Unlike conventional approaches that critically rely on intersection-free inputs, \moniker{} robustly recovers from intersections introduced through missed collisions, self-penetrating bodies, or errors in manually designed multi-layer outfits. The technical core of \moniker{} is a novel intersection contour loss that penalizes interpenetrations and encourages rapid resolution thereof. We integrate our intersection loss with a collision-avoiding repulsion objective into a neural cloth simulation method based on graph neural networks (GNNs). We demonstrate our method's ability across a challenging set of diverse multi-layer outfits under dynamic human motions. Our extensive analysis indicates that \moniker{} significantly improves collision handling for learned simulation and produces visually compelling results.
EMAGE: Towards Unified Holistic Co-Speech Gesture Generation via Masked Audio Gesture Modeling
Jan 02, 2024



We propose EMAGE, a framework to generate full-body human gestures from audio and masked gestures, encompassing facial, local body, hands, and global movements. To achieve this, we first introduce BEATX (BEAT-SMPLX-FLAME), a new mesh-level holistic co-speech dataset. BEATX combines MoShed SMPLX body with FLAME head parameters and further refines the modeling of head, neck, and finger movements, offering a community-standardized, high-quality 3D motion captured dataset. EMAGE leverages masked body gesture priors during training to boost inference performance. It involves a Masked Audio Gesture Transformer, facilitating joint training on audio-to-gesture generation and masked gesture reconstruction to effectively encode audio and body gesture hints. Encoded body hints from masked gestures are then separately employed to generate facial and body movements. Moreover, EMAGE adaptively merges speech features from the audio's rhythm and content and utilizes four compositional VQ-VAEs to enhance the results' fidelity and diversity. Experiments demonstrate that EMAGE generates holistic gestures with state-of-the-art performance and is flexible in accepting predefined spatial-temporal gesture inputs, generating complete, audio-synchronized results. Our code and dataset are available at https://pantomatrix.github.io/EMAGE/
Emotional Speech-driven 3D Body Animation via Disentangled Latent Diffusion
Dec 07, 2023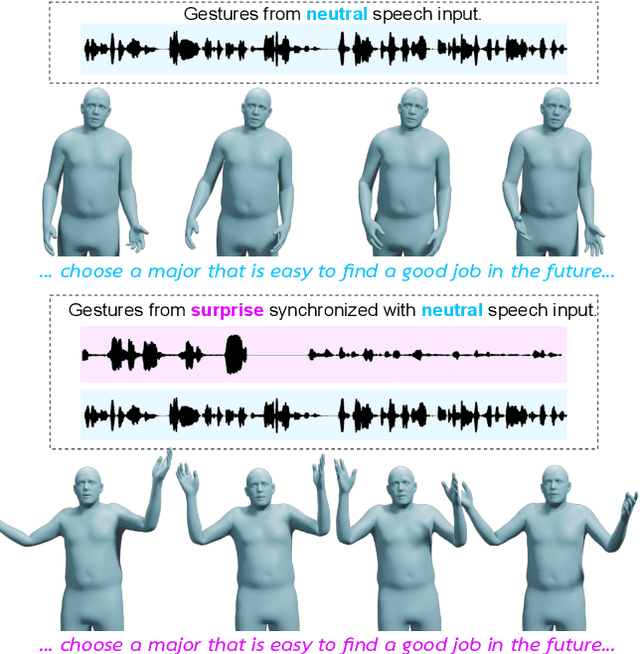



Existing methods for synthesizing 3D human gestures from speech have shown promising results, but they do not explicitly model the impact of emotions on the generated gestures. Instead, these methods directly output animations from speech without control over the expressed emotion. To address this limitation, we present AMUSE, an emotional speech-driven body animation model based on latent diffusion. Our observation is that content (i.e., gestures related to speech rhythm and word utterances), emotion, and personal style are separable. To account for this, AMUSE maps the driving audio to three disentangled latent vectors: one for content, one for emotion, and one for personal style. A latent diffusion model, trained to generate gesture motion sequences, is then conditioned on these latent vectors. Once trained, AMUSE synthesizes 3D human gestures directly from speech with control over the expressed emotions and style by combining the content from the driving speech with the emotion and style of another speech sequence. Randomly sampling the noise of the diffusion model further generates variations of the gesture with the same emotional expressivity. Qualitative, quantitative, and perceptual evaluations demonstrate that AMUSE outputs realistic gesture sequences. Compared to the state of the art, the generated gestures are better synchronized with the speech content and better represent the emotion expressed by the input speech. Our project website is amuse.is.tue.mpg.de.