 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAMMA: Markerless & Automatic Multi-Person Motion Action Capture
Jun 16, 2025We present MAMMA, a markerless motion-capture pipeline that accurately recovers SMPL-X parameters from multi-view video of two-person interaction sequences. Traditional motion-capture systems rely on physical markers. Although they offer high accuracy, their requirements of specialized hardware, manual marker placement, and extensive post-processing make them costly and time-consuming. Recent learning-based methods attempt to overcome these limitations, but most are designed for single-person capture, rely on sparse keypoints, or struggle with occlusions and physical interactions. In this work, we introduce a method that predicts dense 2D surface landmarks conditioned on segmentation masks, enabling person-specific correspondence estimation even under heavy occlusion. We employ a novel architecture that exploits learnable queries for each landmark. We demonstrate that our approach can handle complex person--person interaction and offers greater accuracy than existing methods. To train our network, we construct a large, synthetic multi-view dataset combining human motions from diverse sources, including extreme poses, hand motions, and close interactions. Our dataset yields high-variability synthetic sequences with rich body contact and occlusion, and includes SMPL-X ground-truth annotations with dense 2D landmarks. The result is a system capable of capturing human motion without the need for markers. Our approach offers competitive reconstruction quality compared to commercial marker-based motion-capture solutions, without the extensive manual cleanup. Finally, we address the absence of common benchmarks for dense-landmark prediction and markerless motion capture by introducing two evaluation settings built from real multi-view sequences. We will release our dataset, benchmark, method, training code, and pre-trained model weights for research purposes.
Generative Zoo
Dec 11, 2024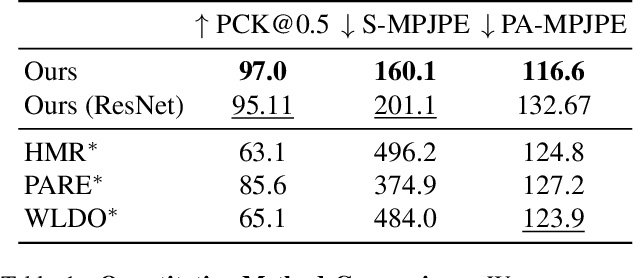
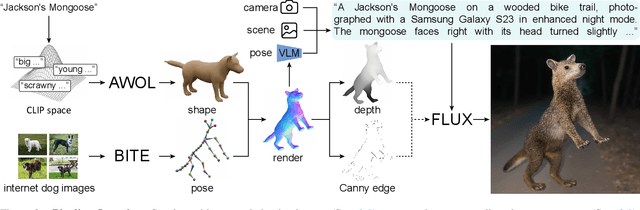
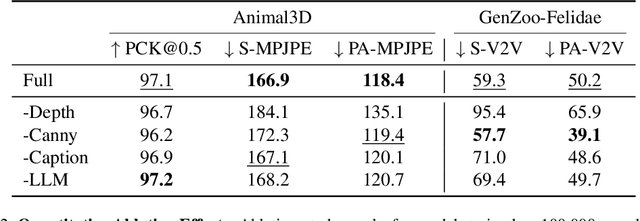

The model-based estimation of 3D animal pose and shape from images enables computational modeling of animal behavior. Training models for this purpose requires large amounts of labeled image data with precise pose and shape annotations. However, capturing such data requires the use of multi-view or marker-based motion-capture systems, which are impractical to adapt to wild animals in situ and impossible to scale across a comprehensive set of animal species. Some have attempted to address the challenge of procuring training data by pseudo-labeling individual real-world images through manual 2D annotation, followed by 3D-parameter optimization to those labels. While this approach may produce silhouette-aligned samples, the obtained pose and shape parameters are often implausible due to the ill-posed nature of the monocular fitting problem. Sidestepping real-world ambiguity, others have designed complex synthetic-data-generation pipelines leveraging video-game engines and collections of artist-designed 3D assets. Such engines yield perfect ground-truth annotations but are often lacking in visual realism and require considerable manual effort to adapt to new species or environments. Motivated by these shortcomings, we propose an alternative approach to synthetic-data generation: rendering with a conditional image-generation model. We introduce a pipeline that samples a diverse set of poses and shapes for a variety of mammalian quadrupeds and generates realistic images with corresponding ground-truth pose and shape parameters. To demonstrate the scalability of our approach, we introduce GenZoo, a synthetic dataset containing one million images of distinct subjects. We train a 3D pose and shape regressor on GenZoo, which achieves state-of-the-art performance on a real-world animal pose and shape estimation benchmark, despite being trained solely on synthetic data. https://genzoo.is.tue.mpg.de
Toward Human Understanding with Controllable Synthesis
Nov 13, 2024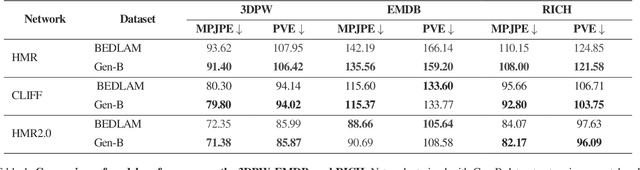
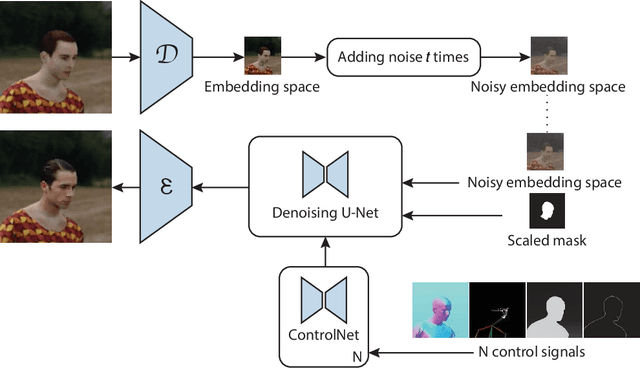
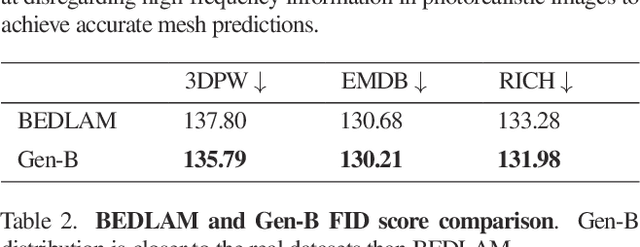

Training methods to perform robust 3D human pose and shape (HPS) estimation requires diverse training images with accurate ground truth. While BEDLAM demonstrates the potential of traditional procedural graphics to generate such data, the training images are clearly synthetic. In contrast, generative image models produce highly realistic images but without ground truth. Putting these methods together seems straightforward: use a generative model with the body ground truth as controlling signal. However, we find that, the more realistic the generated images, the more they deviate from the ground truth, making them inappropriate for training and evaluation. Enhancements of realistic details, such as clothing and facial expressions, can lead to subtle yet significant deviations from the ground truth, potentially misleading training models. We empirically verify that this misalignment causes the accuracy of HPS networks to decline when trained with generated images. To address this, we design a controllable synthesis method that effectively balances image realism with precise ground truth. We use this to create the Generative BEDLAM (Gen-B) dataset, which improves the realism of the existing synthetic BEDLAM dataset while preserving ground truth accuracy. We perform extensive experiments, with various noise-conditioning strategies, to evaluate the tradeoff between visual realism and HPS accuracy. We show, for the first time, that generative image models can be controlled by traditional graphics methods to produce training data that increases the accuracy of HPS methods.
Global Point Cloud Registration Network for Large Transformations
Mar 26, 2024Three-dimensional data registration is an established yet challenging problem that is key in many different applications, such as mapping the environment for autonomous vehicles, and modeling objects and people for avatar creation, among many others. Registration refers to the process of mapping multiple data into the same coordinate system by means of matching correspondences and transformation estimation. Novel proposals exploit the benefits of deep learning architectures for this purpose, as they learn the best features for the data, providing better matches and hence results. However, the state of the art is usually focused on cases of relatively small transformations, although in certain applications and in a real and practical environment, large transformations are very common. In this paper, we present ReLaTo (Registration for Large Transformations), an architecture that faces the cases where large transformations happen while maintaining good performance for local transformations. This proposal uses a novel Softmax pooling layer to find correspondences in a bilateral consensus manner between two point sets, sampling the most confident matches. These matches are used to estimate a coarse and global registration using weighted Singular Value Decomposition (SVD). A target-guided denoising step is then applied to both the obtained matches and latent features, estimating the final fine registration considering the local geometry. All these steps are carried out following an end-to-end approach, which has been shown to improve 10 state-of-the-art registration methods in two datasets commonly used for this task (ModelNet40 and KITTI), especially in the case of large transformations.
SimpleEgo: Predicting Probabilistic Body Pose from Egocentric Cameras
Jan 26, 2024



Our work addresses the problem of egocentric human pose estimation from downwards-facing cameras on head-mounted devices (HMD). This presents a challenging scenario, as parts of the body often fall outside of the image or are occluded. Previous solutions minimize this problem by using fish-eye camera lenses to capture a wider view, but these can present hardware design issues. They also predict 2D heat-maps per joint and lift them to 3D space to deal with self-occlusions, but this requires large network architectures which are impractical to deploy on resource-constrained HMDs. We predict pose from images captured with conventional rectilinear camera lenses. This resolves hardware design issues, but means body parts are often out of frame. As such, we directly regress probabilistic joint rotations represented as matrix Fisher distributions for a parameterized body model. This allows us to quantify pose uncertainties and explain out-of-frame or occluded joints. This also removes the need to compute 2D heat-maps and allows for simplified DNN architectures which require less compute. Given the lack of egocentric datasets using rectilinear camera lenses, we introduce the SynthEgo dataset, a synthetic dataset with 60K stereo images containing high diversity of pose, shape, clothing and skin tone. Our approach achieves state-of-the-art results for this challenging configuration, reducing mean per-joint position error by 23% overall and 58% for the lower body. Our architecture also has eight times fewer parameters and runs twice as fast as the current state-of-the-art. Experiments show that training on our synthetic dataset leads to good generalization to real world images without fine-tuning.
Two Heads are Better than One: Geometric-Latent Attention for Point Cloud Classification and Segmentation
Oct 30, 2021
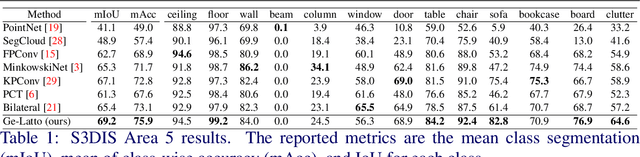
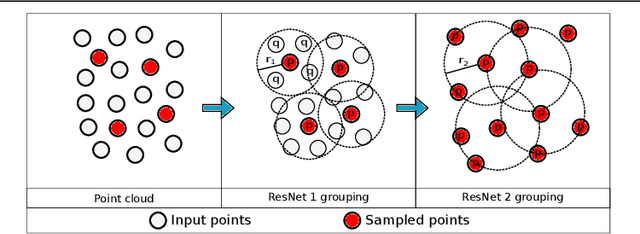

We present an innovative two-headed attention layer that combines geometric and latent features to segment a 3D scene into semantically meaningful subsets. Each head combines local and global information, using either the geometric or latent features, of a neighborhood of points and uses this information to learn better local relationships. This Geometric-Latent attention layer (Ge-Latto) is combined with a sub-sampling strategy to capture global features. Our method is invariant to permutation thanks to the use of shared-MLP layers, and it can also be used with point clouds with varying densities because the local attention layer does not depend on the neighbor order. Our proposal is simple yet robust, which allows it to achieve competitive results in the ShapeNetPart and ModelNet40 datasets, and the state-of-the-art when segmenting the complex dataset S3DIS, with 69.2% IoU on Area 5, and 89.7% overall accuracy using K-fold cross-validation on the 6 areas.
Hybrid Multi-camera Visual Servoing to Moving Target
Aug 02, 2018
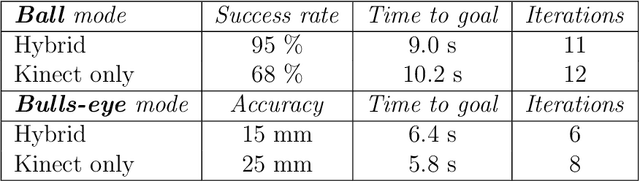
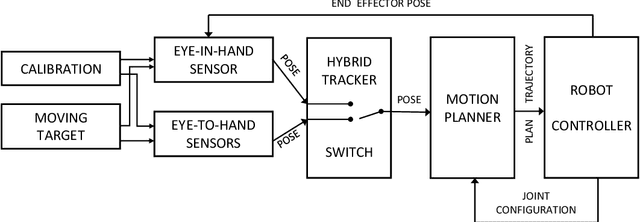
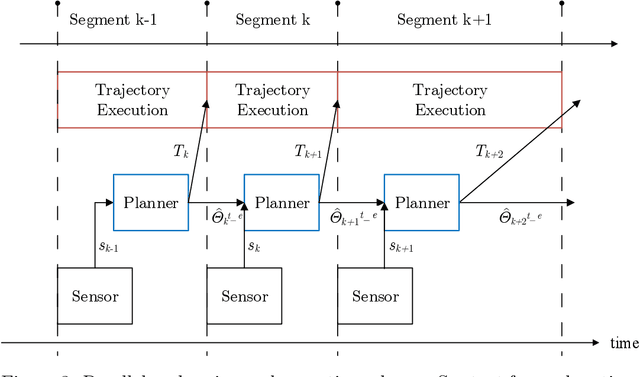
Visual servoing is a well-known task in robotics. However, there are still challenges when multiple visual sources are combined to accurately guide the robot or occlusions appear. In this paper we present a novel visual servoing approach using hybrid multi-camera input data to lead a robot arm accurately to dynamically moving target points in the presence of partial occlusions. The approach uses four RGBD sensors as Eye-to-Hand (EtoH) visual input, and an arm-mounted stereo camera as Eye-in-Hand (EinH). A Master supervisor task selects between using the EtoH or the EinH, depending on the distance between the robot and target. The Master also selects the subset of EtoH cameras that best perceive the target. When the EinH sensor is used, if the target becomes occluded or goes out of the sensor's view-frustum, the Master switches back to the EtoH sensors to re-track the object. Using this adaptive visual input data, the robot is then controlled using an iterative planner that uses position, orientation and joint configuration to estimate the trajectory. Since the target is dynamic, this trajectory is updated every time-step. Experiments show good performance in four different situations: tracking a ball, targeting a bulls-eye, guiding a straw to a mouth and delivering an item to a moving hand. The experiments cover both simple situations such as a ball that is mostly visible from all cameras, and more complex situations such as the mouth which is partially occluded from some of the sensors.