 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Heads are Better than One: Geometric-Latent Attention for Point Cloud Classification and Segmentation
Paper and Code
Oct 30, 2021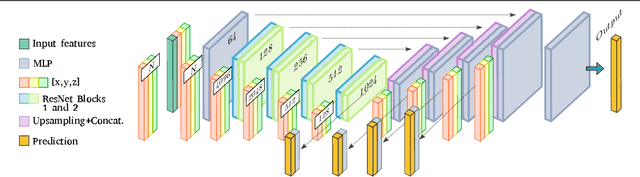
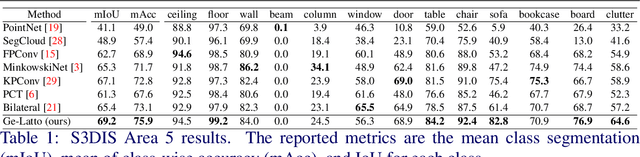
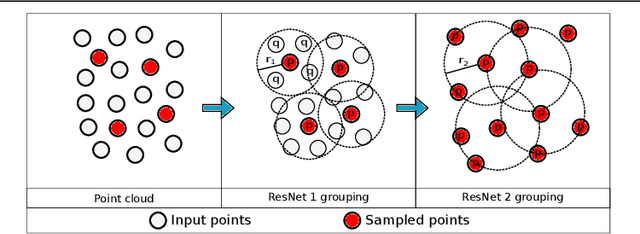

We present an innovative two-headed attention layer that combines geometric and latent features to segment a 3D scene into semantically meaningful subsets. Each head combines local and global information, using either the geometric or latent features, of a neighborhood of points and uses this information to learn better local relationships. This Geometric-Latent attention layer (Ge-Latto) is combined with a sub-sampling strategy to capture global features. Our method is invariant to permutation thanks to the use of shared-MLP layers, and it can also be used with point clouds with varying densities because the local attention layer does not depend on the neighbor order. Our proposal is simple yet robust, which allows it to achieve competitive results in the ShapeNetPart and ModelNet40 datasets, and the state-of-the-art when segmenting the complex dataset S3DIS, with 69.2% IoU on Area 5, and 89.7% overall accuracy using K-fold cross-validation on the 6 areas.