 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Human Understanding with Controllable Synthesis
Paper and Code
Nov 13, 2024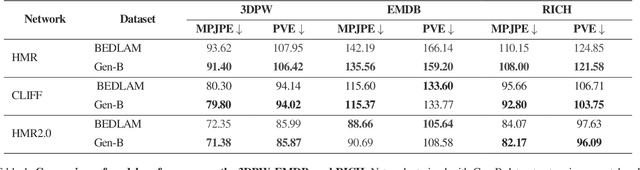
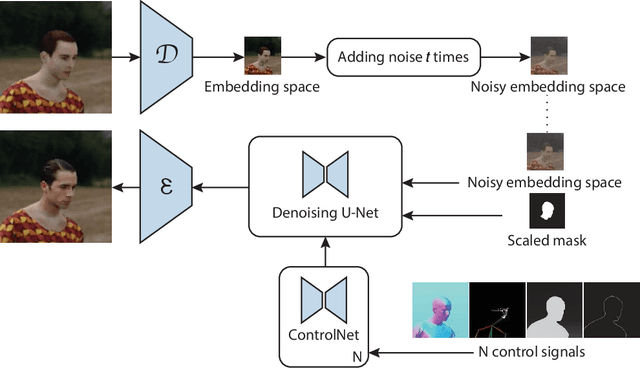
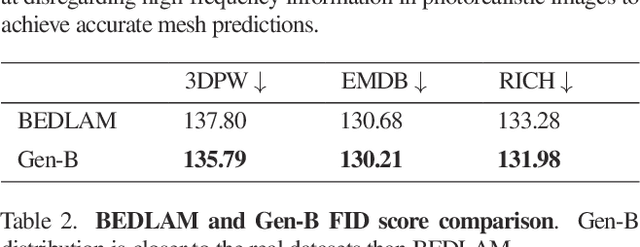

Training methods to perform robust 3D human pose and shape (HPS) estimation requires diverse training images with accurate ground truth. While BEDLAM demonstrates the potential of traditional procedural graphics to generate such data, the training images are clearly synthetic. In contrast, generative image models produce highly realistic images but without ground truth. Putting these methods together seems straightforward: use a generative model with the body ground truth as controlling signal. However, we find that, the more realistic the generated images, the more they deviate from the ground truth, making them inappropriate for training and evaluation. Enhancements of realistic details, such as clothing and facial expressions, can lead to subtle yet significant deviations from the ground truth, potentially misleading training models. We empirically verify that this misalignment causes the accuracy of HPS networks to decline when trained with generated images. To address this, we design a controllable synthesis method that effectively balances image realism with precise ground truth. We use this to create the Generative BEDLAM (Gen-B) dataset, which improves the realism of the existing synthetic BEDLAM dataset while preserving ground truth accuracy. We perform extensive experiments, with various noise-conditioning strategies, to evaluate the tradeoff between visual realism and HPS accuracy. We show, for the first time, that generative image models can be controlled by traditional graphics methods to produce training data that increases the accuracy of HPS methods.