 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround Reaction Inertial Poser: Physics-based Human Motion Capture from Sparse IMUs and Insole Pressure Sensors
Mar 17, 2026We propose Ground Reaction Inertial Poser (GRIP), a method that reconstructs physically plausible human motion using four wearable devices. Unlike conventional IMU-only approaches, GRIP combines IMU signals with foot pressure data to capture both body dynamics and ground interactions. Furthermore, rather than relying solely on kinematic estimation, GRIP uses a digital twin of a person, in the form of a synthetic humanoid in a physics simulator, to reconstruct realistic and physically plausible motion. At its core, GRIP consists of two modules: KinematicsNet, which estimates body poses and velocities from sensor data, and DynamicsNet, which controls the humanoid in the simulator using the residual between the KinematicsNet prediction and the simulated humanoid state. To enable robust training and fair evaluation, we introduce a large-scale dataset, Pressure and Inertial Sensing for Human Motion and Interaction (PRISM), that captures diverse human motions with synchronized IMUs and insole pressure sensors. Experimental results show that GRIP outperforms existing IMU-only and IMU-pressure fusion methods across all evaluated datasets, achieving higher global pose accuracy and improved physical consistency.
DuoMo: Dual Motion Diffusion for World-Space Human Reconstruction
Mar 03, 2026We present DuoMo, a generative method that recovers human motion in world-space coordinates from unconstrained videos with noisy or incomplete observations. Reconstructing such motion requires solving a fundamental trade-off: generalizing from diverse and noisy video inputs while maintaining global motion consistency. Our approach addresses this problem by factorizing motion learning into two diffusion models. The camera-space model first estimates motion from videos in camera coordinates. The world-space model then lifts this initial estimate into world coordinates and refines it to be globally consistent. Together, the two models can reconstruct motion across diverse scenes and trajectories, even from highly noisy or incomplete observations. Moreover, our formulation is general, generating the motion of mesh vertices directly and bypassing parametric models. DuoMo achieves state-of-the-art performance. On EMDB, our method obtains a 16% reduction in world-space reconstruction error while maintaining low foot skating. On RICH, it obtains a 30% reduction in world-space error. Project page: https://yufu-wang.github.io/duomo/
SAM 3D Body: Robust Full-Body Human Mesh Recovery
Feb 17, 2026We introduce SAM 3D Body (3DB), a promptable model for single-image full-body 3D human mesh recovery (HMR) that demonstrates state-of-the-art performance, with strong generalization and consistent accuracy in diverse in-the-wild conditions. 3DB estimates the human pose of the body, feet, and hands. It is the first model to use a new parametric mesh representation, Momentum Human Rig (MHR), which decouples skeletal structure and surface shape. 3DB employs an encoder-decoder architecture and supports auxiliary prompts, including 2D keypoints and masks, enabling user-guided inference similar to the SAM family of models. We derive high-quality annotations from a multi-stage annotation pipeline that uses various combinations of manual keypoint annotation, differentiable optimization, multi-view geometry, and dense keypoint detection. Our data engine efficiently selects and processes data to ensure data diversity, collecting unusual poses and rare imaging conditions. We present a new evaluation dataset organized by pose and appearance categories, enabling nuanced analysis of model behavior. Our experiments demonstrate superior generalization and substantial improvements over prior methods in both qualitative user preference studies and traditional quantitative analysis. Both 3DB and MHR are open-source.
MAMMA: Markerless & Automatic Multi-Person Motion Action Capture
Jun 16, 2025We present MAMMA, a markerless motion-capture pipeline that accurately recovers SMPL-X parameters from multi-view video of two-person interaction sequences. Traditional motion-capture systems rely on physical markers. Although they offer high accuracy, their requirements of specialized hardware, manual marker placement, and extensive post-processing make them costly and time-consuming. Recent learning-based methods attempt to overcome these limitations, but most are designed for single-person capture, rely on sparse keypoints, or struggle with occlusions and physical interactions. In this work, we introduce a method that predicts dense 2D surface landmarks conditioned on segmentation masks, enabling person-specific correspondence estimation even under heavy occlusion. We employ a novel architecture that exploits learnable queries for each landmark. We demonstrate that our approach can handle complex person--person interaction and offers greater accuracy than existing methods. To train our network, we construct a large, synthetic multi-view dataset combining human motions from diverse sources, including extreme poses, hand motions, and close interactions. Our dataset yields high-variability synthetic sequences with rich body contact and occlusion, and includes SMPL-X ground-truth annotations with dense 2D landmarks. The result is a system capable of capturing human motion without the need for markers. Our approach offers competitive reconstruction quality compared to commercial marker-based motion-capture solutions, without the extensive manual cleanup. Finally, we address the absence of common benchmarks for dense-landmark prediction and markerless motion capture by introducing two evaluation settings built from real multi-view sequences. We will release our dataset, benchmark, method, training code, and pre-trained model weights for research purposes.
WHAM: Reconstructing World-grounded Humans with Accurate 3D Motion
Dec 12, 2023
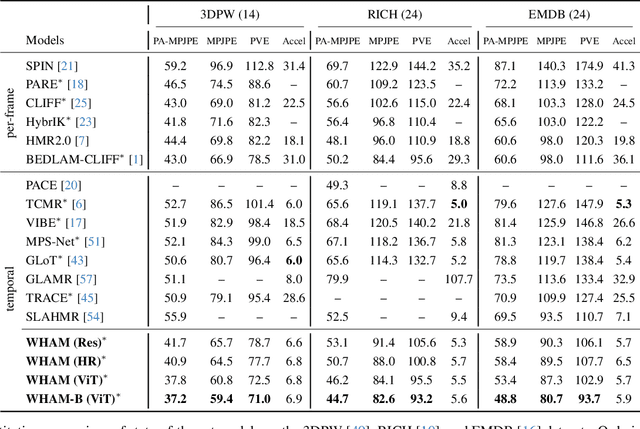


The estimation of 3D human motion from video has progressed rapidly but current methods still have several key limitations. First, most methods estimate the human in camera coordinates. Second, prior work on estimating humans in global coordinates often assumes a flat ground plane and produces foot sliding. Third, the most accurate methods rely on computationally expensive optimization pipelines, limiting their use to offline applications. Finally, existing video-based methods are surprisingly less accurate than single-frame methods. We address these limitations with WHAM (World-grounded Humans with Accurate Motion), which accurately and efficiently reconstructs 3D human motion in a global coordinate system from video. WHAM learns to lift 2D keypoint sequences to 3D using motion capture data and fuses this with video features, integrating motion context and visual information. WHAM exploits camera angular velocity estimated from a SLAM method together with human motion to estimate the body's global trajectory. We combine this with a contact-aware trajectory refinement method that lets WHAM capture human motion in diverse conditions, such as climbing stairs. WHAM outperforms all existing 3D human motion recovery methods across multiple in-the-wild benchmarks. Code will be available for research purposes at http://wham.is.tue.mpg.de/
Multi-view Human Pose and Shape Estimation Using Learnable Volumetric Aggregation
Nov 26, 2020
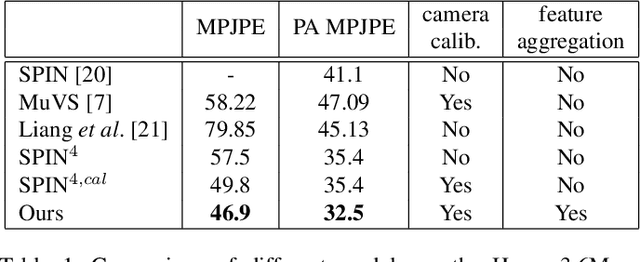
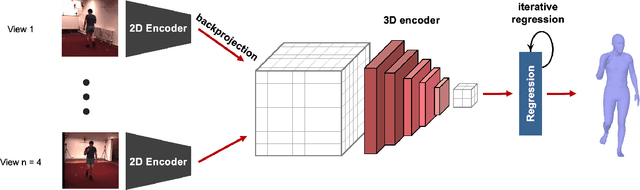
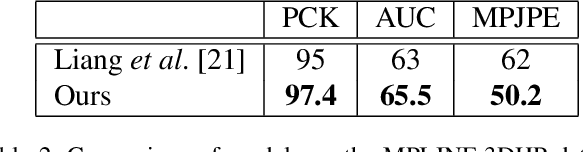
Human pose and shape estimation from RGB images is a highly sought after alternative to marker-based motion capture, which is laborious, requires expensive equipment, and constrains capture to laboratory environments. Monocular vision-based algorithms, however, still suffer from rotational ambiguities and are not ready for translation in healthcare applications, where high accuracy is paramount. While fusion of data from multiple viewpoints could overcome these challenges, current algorithms require further improvement to obtain clinically acceptable accuracies. In this paper, we propose a learnable volumetric aggregation approach to reconstruct 3D human body pose and shape from calibrated multi-view images. We use a parametric representation of the human body, which makes our approach directly applicable to medical applications. Compared to previous approaches, our framework shows higher accuracy and greater promise for real-time prediction, given its cost efficiency.