 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human Hands to Robot Arms: Manipulation Skills Transfer via Trajectory Alignment
Oct 01, 2025Learning diverse manipulation skills for real-world robots is severely bottlenecked by the reliance on costly and hard-to-scale teleoperated demonstrations. While human videos offer a scalable alternative, effectively transferring manipulation knowledge is fundamentally hindered by the significant morphological gap between human and robotic embodiments. To address this challenge and facilitate skill transfer from human to robot, we introduce Traj2Action,a novel framework that bridges this embodiment gap by using the 3D trajectory of the operational endpoint as a unified intermediate representation, and then transfers the manipulation knowledge embedded in this trajectory to the robot's actions. Our policy first learns to generate a coarse trajectory, which forms an high-level motion plan by leveraging both human and robot data. This plan then conditions the synthesis of precise, robot-specific actions (e.g., orientation and gripper state) within a co-denoising framework. Extensive real-world experiments on a Franka robot demonstrate that Traj2Action boosts the performance by up to 27% and 22.25% over $\pi_0$ baseline on short- and long-horizon real-world tasks, and achieves significant gains as human data scales in robot policy learning. Our project website, featuring code and video demonstrations, is available at https://anonymous.4open.science/w/Traj2Action-4A45/.
InfLVG: Reinforce Inference-Time Consistent Long Video Generation with GRPO
May 23, 2025Recent advances in text-to-video generation, particularly with autoregressive models, have enabled the synthesis of high-quality videos depicting individual scenes. However, extending these models to generate long, cross-scene videos remains a significant challenge. As the context length grows during autoregressive decoding, computational costs rise sharply, and the model's ability to maintain consistency and adhere to evolving textual prompts deteriorates. We introduce InfLVG, an inference-time framework that enables coherent long video generation without requiring additional long-form video data. InfLVG leverages a learnable context selection policy, optimized via Group Relative Policy Optimization (GRPO), to dynamically identify and retain the most semantically relevant context throughout the generation process. Instead of accumulating the entire generation history, the policy ranks and selects the top-$K$ most contextually relevant tokens, allowing the model to maintain a fixed computational budget while preserving content consistency and prompt alignment. To optimize the policy, we design a hybrid reward function that jointly captures semantic alignment, cross-scene consistency, and artifact reduction. To benchmark performance, we introduce the Cross-scene Video Benchmark (CsVBench) along with an Event Prompt Set (EPS) that simulates complex multi-scene transitions involving shared subjects and varied actions/backgrounds. Experimental results show that InfLVG can extend video length by up to 9$\times$, achieving strong consistency and semantic fidelity across scenes. Our code is available at https://github.com/MAPLE-AIGC/InfLVG.
Flow Generator Matching
Oct 25, 2024



In the realm of Artificial Intelligence Generated Content (AIGC), flow-matching models have emerged as a powerhouse, achieving success due to their robust theoretical underpinnings and solid ability for large-scale generative modeling. These models have demonstrated state-of-the-art performance, but their brilliance comes at a cost. The process of sampling from these models is notoriously demanding on computational resources, as it necessitates the use of multi-step numerical ordinary differential equations (ODEs). Against this backdrop, this paper presents a novel solution with theoretical guarantees in the form of Flow Generator Matching (FGM), an innovative approach designed to accelerate the sampling of flow-matching models into a one-step generation, while maintaining the original performance. On the CIFAR10 unconditional generation benchmark, our one-step FGM model achieves a new record Fr\'echet Inception Distance (FID) score of 3.08 among few-step flow-matching-based models, outperforming original 50-step flow-matching models. Furthermore, we use the FGM to distill the Stable Diffusion 3, a leading text-to-image flow-matching model based on the MM-DiT architecture. The resulting MM-DiT-FGM one-step text-to-image model demonstrates outstanding industry-level performance. When evaluated on the GenEval benchmark, MM-DiT-FGM has delivered remarkable generating qualities, rivaling other multi-step models in light of the efficiency of a single generation step.
One-Step Diffusion Distillation through Score Implicit Matching
Oct 22, 2024
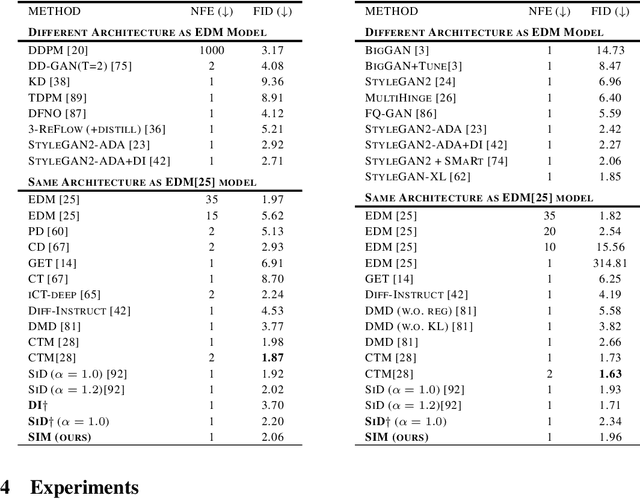


Despite their strong performances on many generative tasks, diffusion models require a large number of sampling steps in order to generate realistic samples. This has motivated the community to develop effective methods to distill pre-trained diffusion models into more efficient models, but these methods still typically require few-step inference or perform substantially worse than the underlying model. In this paper, we present Score Implicit Matching (SIM) a new approach to distilling pre-trained diffusion models into single-step generator models, while maintaining almost the same sample generation ability as the original model as well as being data-free with no need of training samples for distillation. The method rests upon the fact that, although the traditional score-based loss is intractable to minimize for generator models, under certain conditions we can efficiently compute the gradients for a wide class of score-based divergences between a diffusion model and a generator. SIM shows strong empirical performances for one-step generators: on the CIFAR10 dataset, it achieves an FID of 2.06 for unconditional generation and 1.96 for class-conditional generation. Moreover, by applying SIM to a leading transformer-based diffusion model, we distill a single-step generator for text-to-image (T2I) generation that attains an aesthetic score of 6.42 with no performance decline over the original multi-step counterpart, clearly outperforming the other one-step generators including SDXL-TURBO of 5.33, SDXL-LIGHTNING of 5.34 and HYPER-SDXL of 5.85. We will release this industry-ready one-step transformer-based T2I generator along with this paper.
* Accepted by NeurIPS 2024
Self-similarity Driven Scale-invariant Learning for Weakly Supervised Person Search
Feb 25, 2023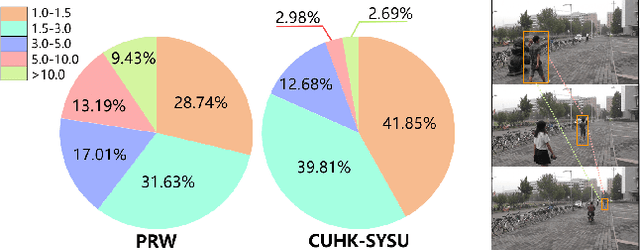
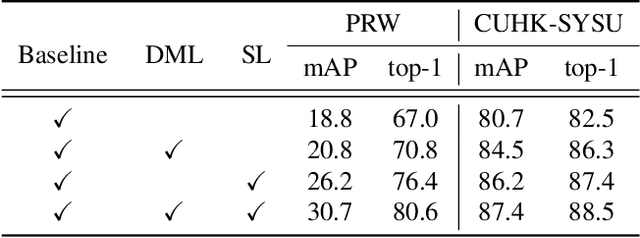
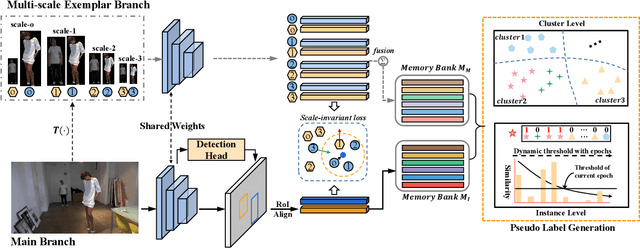
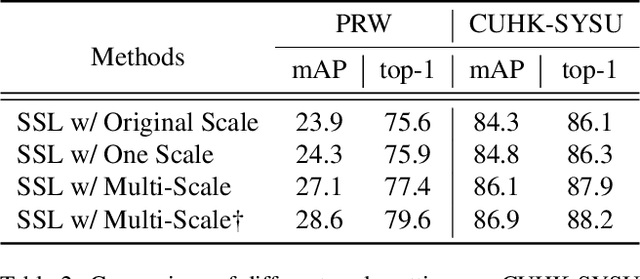
Weakly supervised person search aims to jointly detect and match persons with only bounding box annotations. Existing approaches typically focus on improving the features by exploring relations of persons. However, scale variation problem is a more severe obstacle and under-studied that a person often owns images with different scales (resolutions). On the one hand, small-scale images contain less information of a person, thus affecting the accuracy of the generated pseudo labels. On the other hand, the similarity of cross-scale images is often smaller than that of images with the same scale for a person, which will increase the difficulty of matching. In this paper, we address this problem by proposing a novel one-step framework, named Self-similarity driven Scale-invariant Learning (SSL). Scale invariance can be explored based on the self-similarity prior that it shows the same statistical properties of an image at different scales. To this end, we introduce a Multi-scale Exemplar Branch to guide the network in concentrating on the foreground and learning scale-invariant features by hard exemplars mining. To enhance the discriminative power of the features in an unsupervised manner, we introduce a dynamic multi-label prediction which progressively seeks true labels for training. It is adaptable to different types of unlabeled data and serves as a compensation for clustering based strategy. Experiments on PRW and CUHK-SYSU databases demonstrate the effectiveness of our method.