 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealisDance: Equip controllable character animation with realistic hands
Sep 10, 2024Controllable character animation is an emerging task that generates character videos controlled by pose sequences from given character images. Although character consistency has made significant progress via reference UNet, another crucial factor, pose control, has not been well studied by existing methods yet, resulting in several issues: 1) The generation may fail when the input pose sequence is corrupted. 2) The hands generated using the DWPose sequence are blurry and unrealistic. 3) The generated video will be shaky if the pose sequence is not smooth enough. In this paper, we present RealisDance to handle all the above issues. RealisDance adaptively leverages three types of poses, avoiding failed generation caused by corrupted pose sequences. Among these pose types, HaMeR provides accurate 3D and depth information of hands, enabling RealisDance to generate realistic hands even for complex gestures. Besides using temporal attention in the main UNet, RealisDance also inserts temporal attention into the pose guidance network, smoothing the video from the pose condition aspect. Moreover, we introduce pose shuffle augmentation during training to further improve generation robustness and video smoothness. Qualitative experiments demonstrate the superiority of RealisDance over other existing methods, especially in hand quality.
RealisHuman: A Two-Stage Approach for Refining Malformed Human Parts in Generated Images
Sep 05, 2024



In recent years, diffusion models have revolutionized visual generation, outperforming traditional frameworks like Generative Adversarial Networks (GANs). However, generating images of humans with realistic semantic parts, such as hands and faces, remains a significant challenge due to their intricate structural complexity. To address this issue, we propose a novel post-processing solution named RealisHuman. The RealisHuman framework operates in two stages. First, it generates realistic human parts, such as hands or faces, using the original malformed parts as references, ensuring consistent details with the original image. Second, it seamlessly integrates the rectified human parts back into their corresponding positions by repainting the surrounding areas to ensure smooth and realistic blending. The RealisHuman framework significantly enhances the realism of human generation, as demonstrated by notable improvements in both qualitative and quantitative metrics. Code is available at https://github.com/Wangbenzhi/RealisHuman.
Self-similarity Driven Scale-invariant Learning for Weakly Supervised Person Search
Feb 25, 2023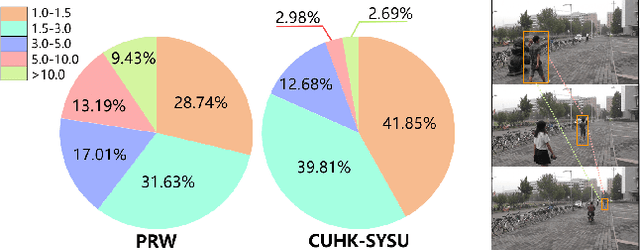
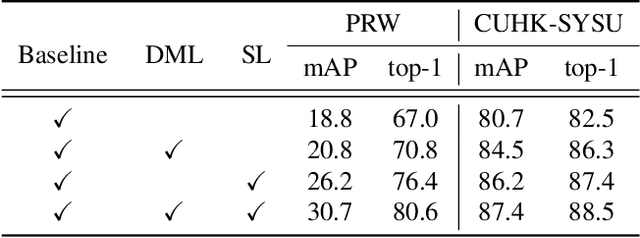
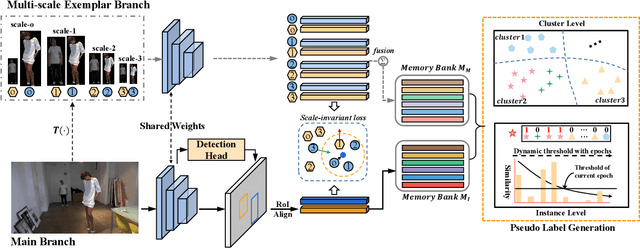
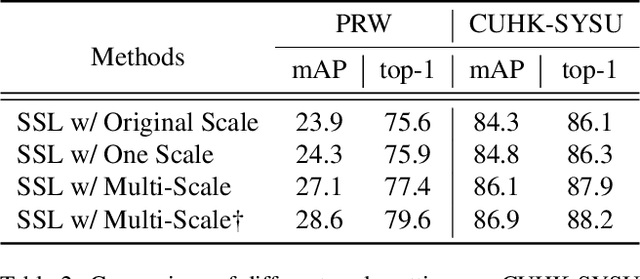
Weakly supervised person search aims to jointly detect and match persons with only bounding box annotations. Existing approaches typically focus on improving the features by exploring relations of persons. However, scale variation problem is a more severe obstacle and under-studied that a person often owns images with different scales (resolutions). On the one hand, small-scale images contain less information of a person, thus affecting the accuracy of the generated pseudo labels. On the other hand, the similarity of cross-scale images is often smaller than that of images with the same scale for a person, which will increase the difficulty of matching. In this paper, we address this problem by proposing a novel one-step framework, named Self-similarity driven Scale-invariant Learning (SSL). Scale invariance can be explored based on the self-similarity prior that it shows the same statistical properties of an image at different scales. To this end, we introduce a Multi-scale Exemplar Branch to guide the network in concentrating on the foreground and learning scale-invariant features by hard exemplars mining. To enhance the discriminative power of the features in an unsupervised manner, we introduce a dynamic multi-label prediction which progressively seeks true labels for training. It is adaptable to different types of unlabeled data and serves as a compensation for clustering based strategy. Experiments on PRW and CUHK-SYSU databases demonstrate the effectiveness of our method.
Cross-media Scientific Research Achievements Query based on Ranking Learning
Apr 26, 2022With the advent of the information age, the scale of data on the Internet is getting larger and larger, and it is full of text, images, videos, and other information. Different from social media data and news data, scientific research achievements information has the characteristics of many proper nouns and strong ambiguity. The traditional single-mode query method based on keywords can no longer meet the needs of scientific researchers and managers of the Ministry of Science and Technology. Scientific research project information and scientific research scholar information contain a large amount of valuable scientific research achievement information. Evaluating the output capability of scientific research projects and scientific research teams can effectively assist managers in decision-making. In view of the above background, this paper expounds on the research status from four aspects: characteristic learning of scientific research results, cross-media research results query, ranking learning of scientific research results, and cross-media scientific research achievement query system.
Cross-Media Scientific Research Achievements Retrieval Based on Deep Language Model
Mar 29, 2022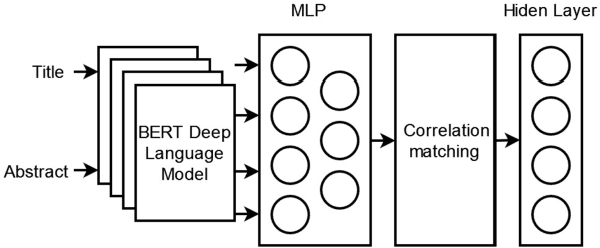

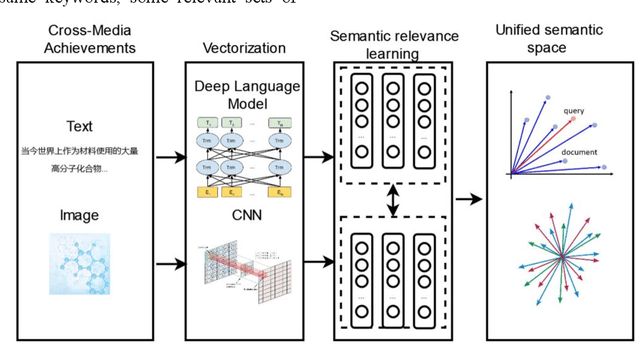
Science and technology big data contain a lot of cross-media information.There are images and texts in the scientific paper.The s ingle modal search method cannot well meet the needs of scientific researchers.This paper proposes a cross-media scientific research achievements retrieval method based on deep language model (CARDL).It achieves a unified cross-media semantic representation by learning the semantic association between different modal data, and is applied to the generation of text semantic vector of scientific research achievements, and then cross-media retrieval is realized through semantic similarity matching between different modal data.Experimental results show that the proposed CARDL method achieves better cross-modal retrieval performance than existing methods. Key words science and technology big data ; cross-media retrieval; cross-media semantic association learning; deep language model; semantic similarity