 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWPFed: Web-based Personalized Federation for Decentralized Systems
Oct 15, 2024



Decentralized learning has become crucial for collaborative model training in environments where data privacy and trust are paramount. In web-based applications, clients are liberated from traditional fixed network topologies, enabling the establishment of arbitrary peer-to-peer (P2P) connections. While this flexibility is highly promising, it introduces a fundamental challenge: the optimal selection of neighbors to ensure effective collaboration. To address this, we introduce WPFed, a fully decentralized, web-based learning framework designed to enable globally optimal neighbor selection. WPFed employs a dynamic communication graph and a weighted neighbor selection mechanism. By assessing inter-client similarity through Locality-Sensitive Hashing (LSH) and evaluating model quality based on peer rankings, WPFed enables clients to identify personalized optimal neighbors on a global scale while preserving data privacy. To enhance security and deter malicious behavior, WPFed integrates verification mechanisms for both LSH codes and performance rankings, leveraging blockchain-driven announcements to ensure transparency and verifiability. Through extensive experiments on multiple real-world datasets, we demonstrate that WPFed significantly improves learning outcomes and system robustness compared to traditional federated learning methods. Our findings highlight WPFed's potential to facilitate effective and secure decentralized collaborative learning across diverse and interconnected web environments.
SimCGNN: Simple Contrastive Graph Neural Network for Session-based Recommendation
Feb 08, 2023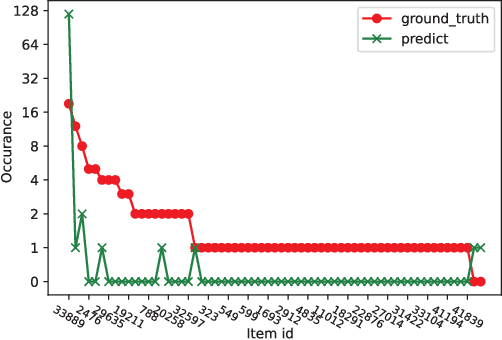
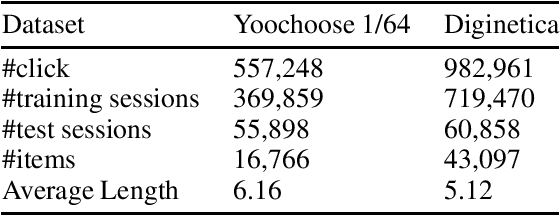
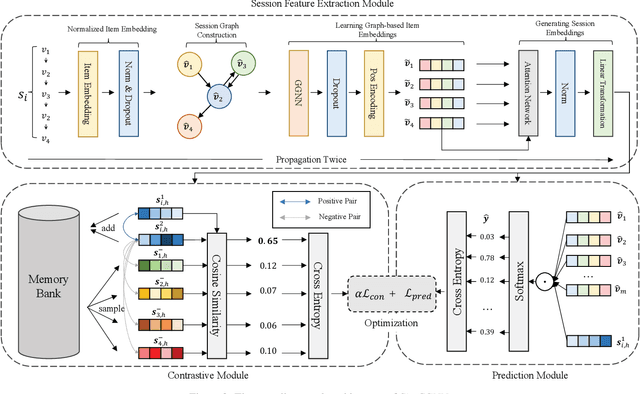
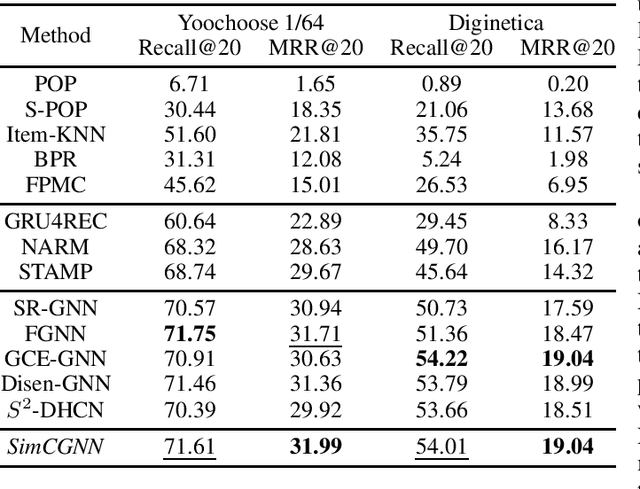
Session-based recommendation (SBR) problem, which focuses on next-item prediction for anonymous users, has received increasingly more attention from researchers. Existing graph-based SBR methods all lack the ability to differentiate between sessions with the same last item, and suffer from severe popularity bias. Inspired by nowadays emerging contrastive learning methods, this paper presents a Simple Contrastive Graph Neural Network for Session-based Recommendation (SimCGNN). In SimCGNN, we first obtain normalized session embeddings on constructed session graphs. We next construct positive and negative samples of the sessions by two forward propagation and a novel negative sample selection strategy, and then calculate the constructive loss. Finally, session embeddings are used to give prediction. Extensive experiments conducted on two real-word datasets show our SimCGNN achieves a significant improvement over state-of-the-art methods.
Mining and searching association relation of scientific papers based on deep learning
Apr 25, 2022There is a complex correlation among the data of scientific papers. The phenomenon reveals the data characteristics, laws, and correlations contained in the data of scientific and technological papers in specific fields, which can realize the analysis of scientific and technological big data and help to design applications to serve scientific researchers. Therefore, the research on mining and searching the association relationship of scientific papers based on deep learning has far-reaching practical significance.
Research on Domain Information Mining and Theme Evolution of Scientific Papers
Apr 18, 2022In recent years, with the increase of social investment in scientific research, the number of research results in various fields has increased significantly. Cross-disciplinary research results have gradually become an emerging frontier research direction. There is a certain dependence between a large number of research results. It is difficult to effectively analyze today's scientific research results when looking at a single research field in isolation. How to effectively use the huge number of scientific papers to help researchers becomes a challenge. This paper introduces the research status at home and abroad in terms of domain information mining and topic evolution law of scientific and technological papers from three aspects: the semantic feature representation learning of scientific and technological papers, the field information mining of scientific and technological papers, and the mining and prediction of research topic evolution rules of scientific and technological papers.
Research topic trend prediction of scientific papers based on spatial enhancement and dynamic graph convolution network
Mar 30, 2022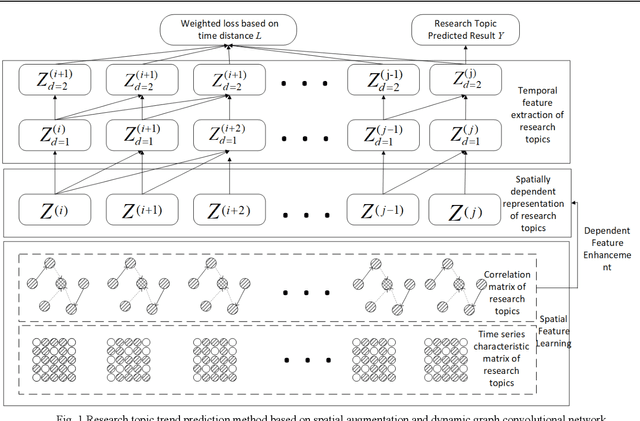
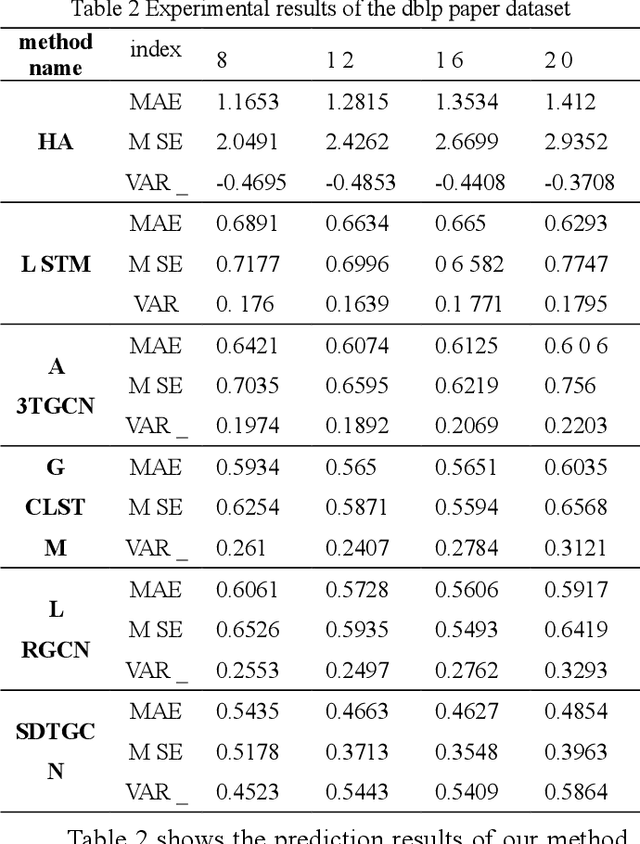
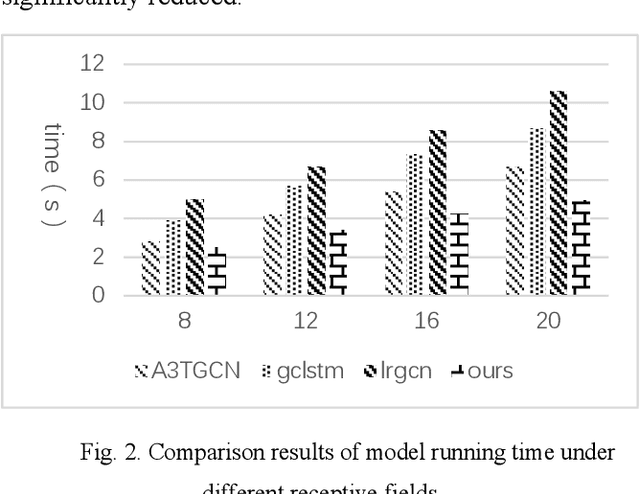
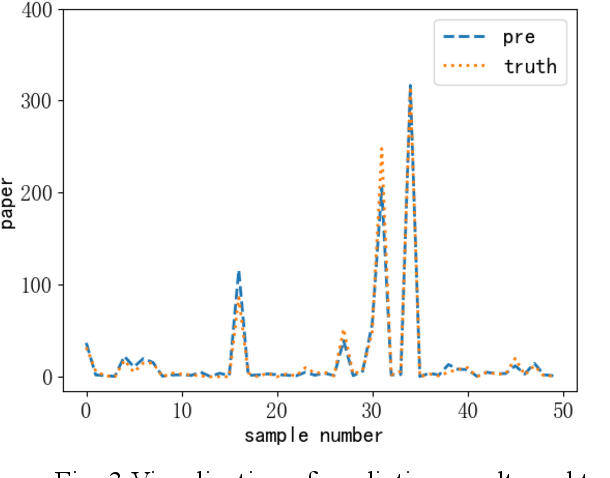
In recent years, with the increase of social investment in scientific research, the number of research results in various fields has increased significantly. Accurately and effectively predicting the trends of future research topics can help researchers discover future research hotspots. However, due to the increasingly close correlation between various research themes, there is a certain dependency relationship between a large number of research themes. Viewing a single research theme in isolation and using traditional sequence problem processing methods cannot effectively explore the spatial dependencies between these research themes. To simultaneously capture the spatial dependencies and temporal changes between research topics, we propose a deep neural network-based research topic hotness prediction algorithm, a spatiotemporal convolutional network model. Our model combines a graph convolutional neural network (GCN) and Temporal Convolutional Network (TCN), specifically, GCNs are used to learn the spatial dependencies of research topics a and use space dependence to strengthen spatial characteristics. TCN is used to learn the dynamics of research topics' trends. Optimization is based on the calculation of weighted losses based on time distance. Compared with the current mainstream sequence prediction models and similar spatiotemporal models on the paper datasets, experiments show that, in research topic prediction tasks, our model can effectively capture spatiotemporal relationships and the predictions outperform state-of-art baselines.
Cross-Media Scientific Research Achievements Retrieval Based on Deep Language Model
Mar 29, 2022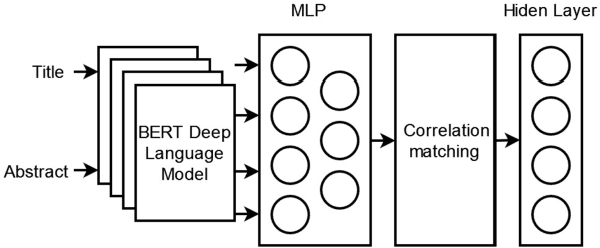

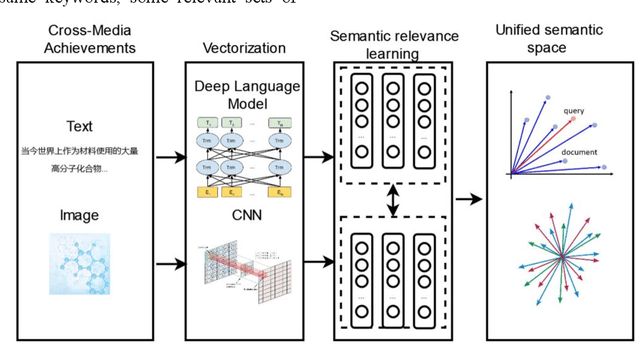
Science and technology big data contain a lot of cross-media information.There are images and texts in the scientific paper.The s ingle modal search method cannot well meet the needs of scientific researchers.This paper proposes a cross-media scientific research achievements retrieval method based on deep language model (CARDL).It achieves a unified cross-media semantic representation by learning the semantic association between different modal data, and is applied to the generation of text semantic vector of scientific research achievements, and then cross-media retrieval is realized through semantic similarity matching between different modal data.Experimental results show that the proposed CARDL method achieves better cross-modal retrieval performance than existing methods. Key words science and technology big data ; cross-media retrieval; cross-media semantic association learning; deep language model; semantic similarity
Scientific and Technological Information Oriented Semantics-adversarial and Media-adversarial Cross-media Retrieval
Mar 16, 2022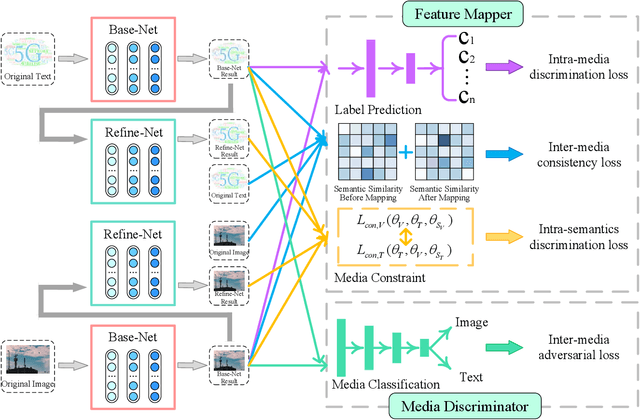

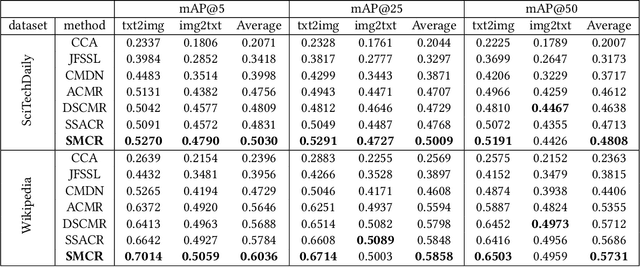
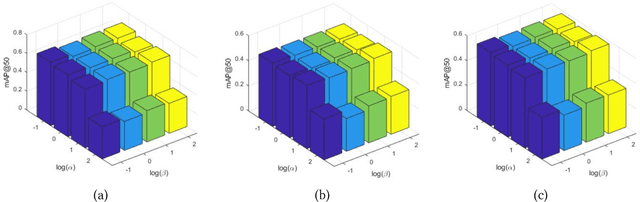
Cross-media retrieval of scientific and technological information is one of the important tasks in the cross-media study. Cross-media scientific and technological information retrieval obtain target information from massive multi-source and heterogeneous scientific and technological resources, which helps to design applications that meet users' needs, including scientific and technological information recommendation, personalized scientific and technological information retrieval, etc. The core of cross-media retrieval is to learn a common subspace, so that data from different media can be directly compared with each other after being mapped into this subspace. In subspace learning, existing methods often focus on modeling the discrimination of intra-media data and the invariance of inter-media data after mapping; however, they ignore the semantic consistency of inter-media data before and after mapping and media discrimination of intra-semantics data, which limit the result of cross-media retrieval. In light of this, we propose a scientific and technological information oriented Semantics-adversarial and Media-adversarial Cross-media Retrieval method (SMCR) to find an effective common subspace. Specifically, SMCR minimizes the loss of inter-media semantic consistency in addition to modeling intra-media semantic discrimination, to preserve semantic similarity before and after mapping. Furthermore, SMCR constructs a basic feature mapping network and a refined feature mapping network to jointly minimize the media discriminative loss within semantics, so as to enhance the feature mapping network's ability to confuse the media discriminant network. Experimental results on two datasets demonstrate that the proposed SMCR outperforms state-of-the-art methods in cross-media retrieval.