 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
Jan 30, 2026The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON's improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.
DSVM-UNet : Enhancing VM-UNet with Dual Self-distillation for Medical Image Segmentation
Jan 27, 2026Vision Mamba models have been extensively researched in various fields, which address the limitations of previous models by effectively managing long-range dependencies with a linear-time overhead. Several prospective studies have further designed Vision Mamba based on UNet(VM-UNet) for medical image segmentation. These approaches primarily focus on optimizing architectural designs by creating more complex structures to enhance the model's ability to perceive semantic features. In this paper, we propose a simple yet effective approach to improve the model by Dual Self-distillation for VM-UNet (DSVM-UNet) without any complex architectural designs. To achieve this goal, we develop double self-distillation methods to align the features at both the global and local levels. Extensive experiments conducted on the ISIC2017, ISIC2018, and Synapse benchmarks demonstrate that our approach achieves state-of-the-art performance while maintaining computational efficiency. Code is available at https://github.com/RoryShao/DSVM-UNet.git.
* 5 pages, 1 figures
Efficient Mixture-of-Agents Serving via Tree-Structured Routing, Adaptive Pruning, and Dependency-Aware Prefill-Decode Overlap
Dec 19, 2025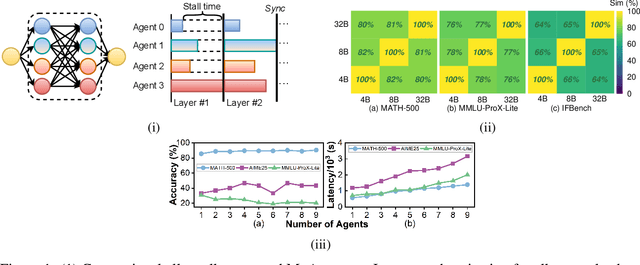
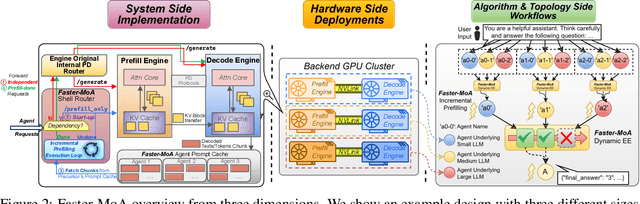
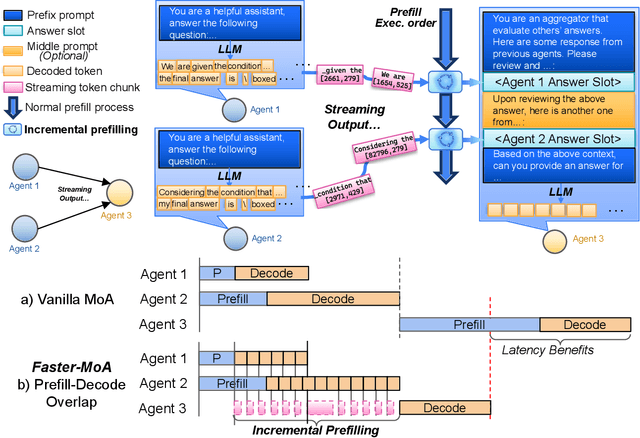
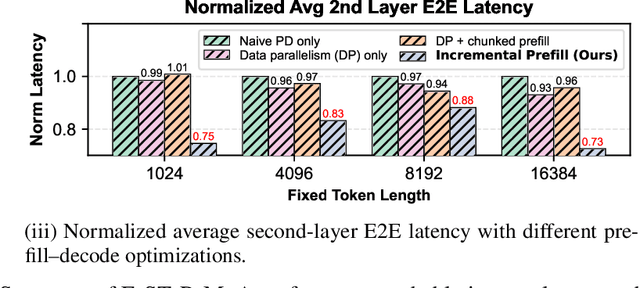
Mixture-of-Agents (MoA) inference can suffer from dense inter-agent communication and low hardware utilization, which jointly inflate serving latency. We present a serving design that targets these bottlenecks through an algorithm-system co-design. First, we replace dense agent interaction graphs with a hierarchical tree topology that induces structured sparsity in inter-agent communication. Second, we introduce a runtime adaptive mechanism that selectively terminates or skips downstream agent invocations using semantic agreement and confidence signals from intermediate outputs. Third, we pipeline agent execution by overlapping incremental prefilling with decoding across dependency-related agents, improving utilization and reducing inference latency. Across representative tasks, this approach substantially reduces end-to-end latency (up to 90%) while maintaining comparable accuracy (within $\pm$1%) relative to dense-connectivity MoA baselines, and can improve accuracy in certain settings.
ChineseEEG-2: An EEG Dataset for Multimodal Semantic Alignment and Neural Decoding during Reading and Listening
Aug 06, 2025EEG-based neural decoding requires large-scale benchmark datasets. Paired brain-language data across speaking, listening, and reading modalities are essential for aligning neural activity with the semantic representation of large language models (LLMs). However, such datasets are rare, especially for non-English languages. Here, we present ChineseEEG-2, a high-density EEG dataset designed for benchmarking neural decoding models under real-world language tasks. Building on our previous ChineseEEG dataset, which focused on silent reading, ChineseEEG-2 adds two active modalities: Reading Aloud (RA) and Passive Listening (PL), using the same Chinese corpus. EEG and audio were simultaneously recorded from four participants during ~10.7 hours of reading aloud. These recordings were then played to eight other participants, collecting ~21.6 hours of EEG during listening. This setup enables speech temporal and semantic alignment across the RA and PL modalities. ChineseEEG-2 includes EEG signals, precise audio, aligned semantic embeddings from pre-trained language models, and task labels. Together with ChineseEEG, this dataset supports joint semantic alignment learning across speaking, listening, and reading. It enables benchmarking of neural decoding algorithms and promotes brain-LLM alignment under multimodal language tasks, especially in Chinese. ChineseEEG-2 provides a benchmark dataset for next-generation neural semantic decoding.
BELLE: A Bi-Level Multi-Agent Reasoning Framework for Multi-Hop Question Answering
May 17, 2025Multi-hop question answering (QA) involves finding multiple relevant passages and performing step-by-step reasoning to answer complex questions. Previous works on multi-hop QA employ specific methods from different modeling perspectives based on large language models (LLMs), regardless of the question types. In this paper, we first conduct an in-depth analysis of public multi-hop QA benchmarks, dividing the questions into four types and evaluating five types of cutting-edge methods for multi-hop QA: Chain-of-Thought (CoT), Single-step, Iterative-step, Sub-step, and Adaptive-step. We find that different types of multi-hop questions have varying degrees of sensitivity to different types of methods. Thus, we propose a Bi-levEL muLti-agEnt reasoning (BELLE) framework to address multi-hop QA by specifically focusing on the correspondence between question types and methods, where each type of method is regarded as an ''operator'' by prompting LLMs differently. The first level of BELLE includes multiple agents that debate to obtain an executive plan of combined ''operators'' to address the multi-hop QA task comprehensively. During the debate, in addition to the basic roles of affirmative debater, negative debater, and judge, at the second level, we further leverage fast and slow debaters to monitor whether changes in viewpoints are reasonable. Extensive experiments demonstrate that BELLE significantly outperforms strong baselines in various datasets. Additionally, the model consumption of BELLE is higher cost-effectiveness than that of single models in more complex multi-hop QA scenarios.
Concept Based Continuous Prompts for Interpretable Text Classification
Dec 02, 2024

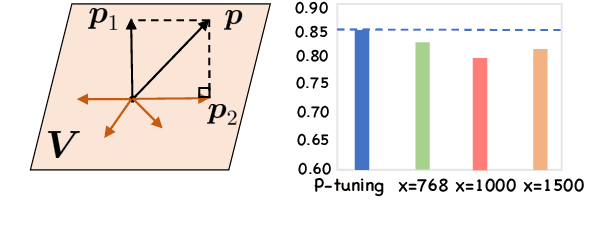
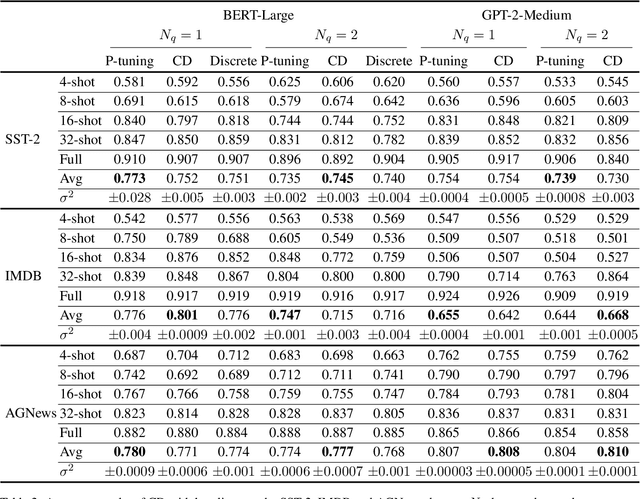
Continuous prompts have become widely adopted for augmenting performance across a wide range of natural language tasks. However, the underlying mechanism of this enhancement remains obscure. Previous studies rely on individual words for interpreting continuous prompts, which lacks comprehensive semantic understanding. Drawing inspiration from Concept Bottleneck Models, we propose a framework for interpreting continuous prompts by decomposing them into human-readable concepts. Specifically, to ensure the feasibility of the decomposition, we demonstrate that a corresponding concept embedding matrix and a coefficient matrix can always be found to replace the prompt embedding matrix. Then, we employ GPT-4o to generate a concept pool and choose potential candidate concepts that are discriminative and representative using a novel submodular optimization algorithm. Experiments demonstrate that our framework can achieve similar results as the original P-tuning and word-based approaches using only a few concepts while providing more plausible results. Our code is available at https://github.com/qq31415926/CD.
Multi-Objective Communication Optimization for Temporal Continuity in Dynamic Vehicular Networks
Nov 30, 2024Vehicular Ad-hoc Networks (VANETs) operate in highly dynamic environments characterized by high mobility, time-varying channel conditions, and frequent network disruptions. Addressing these challenges, this paper presents a novel temporal-aware multi-objective robust optimization framework, which for the first time formally incorporates temporal continuity into the optimization of dynamic multi-hop VANETs. The proposed framework simultaneously optimizes communication delay, throughput, and reliability, ensuring stable and consistent communication paths under rapidly changing conditions. A robust optimization model is formulated to mitigate performance degradation caused by uncertainties in vehicular density and channel fluctuations. To solve the optimization problem, an enhanced Non-dominated Sorting Genetic Algorithm II (NSGA-II) is developed, integrating dynamic encoding, elite inheritance, and adaptive constraint handling to efficiently balance trade-offs among conflicting objectives. Simulation results demonstrate that the proposed framework achieves significant improvements in reliability, delay reduction, and throughput enhancement, while temporal continuity effectively stabilizes communication paths over time. This work provides a pioneering and comprehensive solution for optimizing VANET communication, offering critical insights for robust and efficient strategies in intelligent transportation systems.
Adaptive Genetic Selection based Pinning Control with Asymmetric Coupling for Multi-Network Heterogeneous Vehicular Systems
Nov 05, 2024

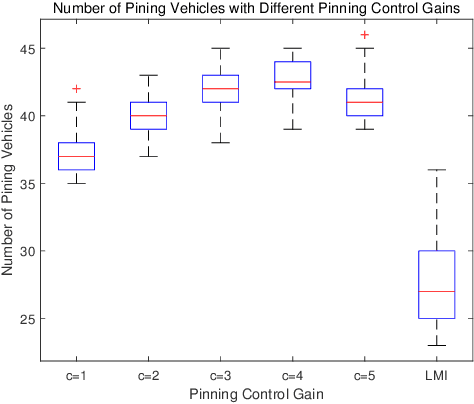
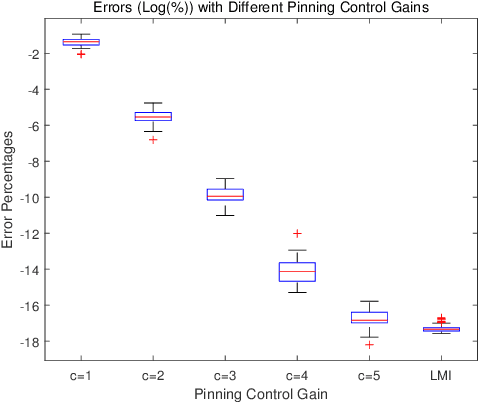
To alleviate computational load on RSUs and cloud platforms, reduce communication bandwidth requirements, and provide a more stable vehicular network service, this paper proposes an optimized pinning control approach for heterogeneous multi-network vehicular ad-hoc networks (VANETs). In such networks, vehicles participate in multiple task-specific networks with asymmetric coupling and dynamic topologies. We first establish a rigorous theoretical foundation by proving the stability of pinning control strategies under both single and multi-network conditions, deriving sufficient stability conditions using Lyapunov theory and linear matrix inequalities (LMIs). Building on this theoretical groundwork, we propose an adaptive genetic algorithm tailored to select optimal pinning nodes, effectively balancing LMI constraints while prioritizing overlapping nodes to enhance control efficiency. Extensive simulations across various network scales demonstrate that our approach achieves rapid consensus with a reduced number of control nodes, particularly when leveraging network overlaps. This work provides a comprehensive solution for efficient control node selection in complex vehicular networks, offering practical implications for deploying large-scale intelligent transportation systems.
Signal Adversarial Examples Generation for Signal Detection Network via White-Box Attack
Oct 02, 2024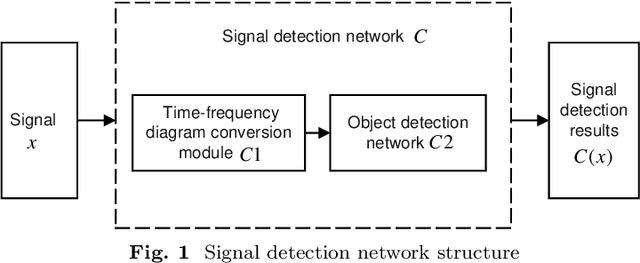



With the development and application of deep learning in signal detection tasks, the vulnerability of neural networks to adversarial attacks has also become a security threat to signal detection networks. This paper defines a signal adversarial examples generation model for signal detection network from the perspective of adding perturbations to the signal. The model uses the inequality relationship of L2-norm between time domain and time-frequency domain to constrain the energy of signal perturbations. Building upon this model, we propose a method for generating signal adversarial examples utilizing gradient-based attacks and Short-Time Fourier Transform. The experimental results show that under the constraint of signal perturbation energy ratio less than 3%, our adversarial attack resulted in a 28.1% reduction in the mean Average Precision (mAP), a 24.7% reduction in recall, and a 30.4% reduction in precision of the signal detection network. Compared to random noise perturbation of equivalent intensity, our adversarial attack demonstrates a significant attack effect.
RealisDance: Equip controllable character animation with realistic hands
Sep 10, 2024Controllable character animation is an emerging task that generates character videos controlled by pose sequences from given character images. Although character consistency has made significant progress via reference UNet, another crucial factor, pose control, has not been well studied by existing methods yet, resulting in several issues: 1) The generation may fail when the input pose sequence is corrupted. 2) The hands generated using the DWPose sequence are blurry and unrealistic. 3) The generated video will be shaky if the pose sequence is not smooth enough. In this paper, we present RealisDance to handle all the above issues. RealisDance adaptively leverages three types of poses, avoiding failed generation caused by corrupted pose sequences. Among these pose types, HaMeR provides accurate 3D and depth information of hands, enabling RealisDance to generate realistic hands even for complex gestures. Besides using temporal attention in the main UNet, RealisDance also inserts temporal attention into the pose guidance network, smoothing the video from the pose condition aspect. Moreover, we introduce pose shuffle augmentation during training to further improve generation robustness and video smoothness. Qualitative experiments demonstrate the superiority of RealisDance over other existing methods, especially in hand quality.