 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuestion-Answering Dense Video Events
Sep 10, 2024
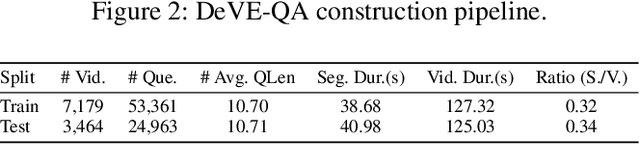
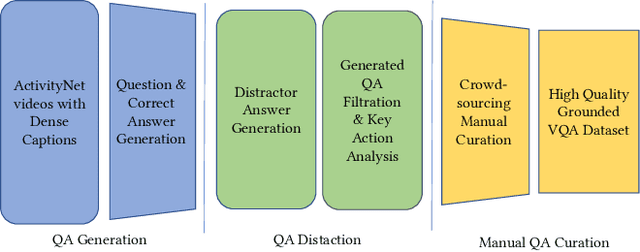
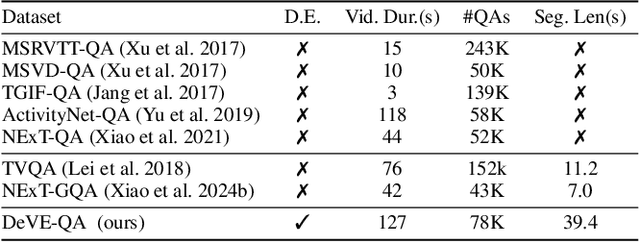
Multimodal Large Language Models (MLLMs) have shown excellent performance in question-answering of single-event videos. In this paper, we present question-answering dense video events, a novel task that requires answering and grounding the dense-event questions in long videos, thus challenging MLLMs to faithfully comprehend and reason about multiple events occurring over extended time periods. To facilitate the study, we construct DeVE-QA - a dataset featuring 78K questions about 26K events on 10.6K long videos. We then benchmark and show that existing MLLMs excelling at single-event QA struggle to perform well in DeVE-QA. For improvement, we propose DeVi, a novel training-free MLLM approach that highlights a hierarchical captioning module, a temporal event memory module, and a self-consistency checking module to respectively detect, contextualize and memorize, and ground dense-events in long videos for question answering. Extensive experiments show that DeVi is superior at answering dense-event questions and grounding relevant video moments. Compared with existing MLLMs, it achieves a remarkable increase of 4.1 percent and 3.7 percent for G(round)QA accuracy on DeVE-QA and NExT-GQA respectively.
VideoQA in the Era of LLMs: An Empirical Study
Aug 08, 2024



Video Large Language Models (Video-LLMs) are flourishing and has advanced many video-language tasks. As a golden testbed, Video Question Answering (VideoQA) plays pivotal role in Video-LLM developing. This work conducts a timely and comprehensive study of Video-LLMs' behavior in VideoQA, aiming to elucidate their success and failure modes, and provide insights towards more human-like video understanding and question answering. Our analyses demonstrate that Video-LLMs excel in VideoQA; they can correlate contextual cues and generate plausible responses to questions about varied video contents. However, models falter in handling video temporality, both in reasoning about temporal content ordering and grounding QA-relevant temporal moments. Moreover, the models behave unintuitively - they are unresponsive to adversarial video perturbations while being sensitive to simple variations of candidate answers and questions. Also, they do not necessarily generalize better. The findings demonstrate Video-LLMs' QA capability in standard condition yet highlight their severe deficiency in robustness and interpretability, suggesting the urgent need on rationales in Video-LLM developing.