 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverybodyDance: Bipartite Graph-Based Identity Correspondence for Multi-Character Animation
Dec 18, 2025
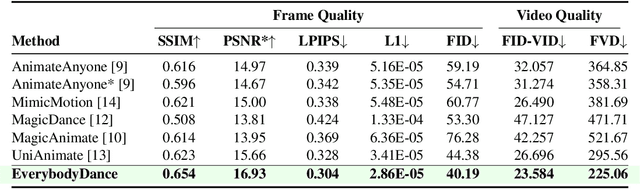

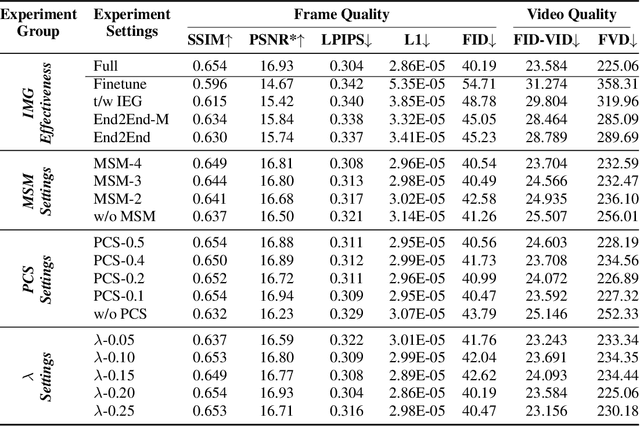
Consistent pose-driven character animation has achieved remarkable progress in single-character scenarios. However, extending these advances to multi-character settings is non-trivial, especially when position swap is involved. Beyond mere scaling, the core challenge lies in enforcing correct Identity Correspondence (IC) between characters in reference and generated frames. To address this, we introduce EverybodyDance, a systematic solution targeting IC correctness in multi-character animation. EverybodyDance is built around the Identity Matching Graph (IMG), which models characters in the generated and reference frames as two node sets in a weighted complete bipartite graph. Edge weights, computed via our proposed Mask-Query Attention (MQA), quantify the affinity between each pair of characters. Our key insight is to formalize IC correctness as a graph structural metric and to optimize it during training. We also propose a series of targeted strategies tailored for multi-character animation, including identity-embedded guidance, a multi-scale matching strategy, and pre-classified sampling, which work synergistically. Finally, to evaluate IC performance, we curate the Identity Correspondence Evaluation benchmark, dedicated to multi-character IC correctness. Extensive experiments demonstrate that EverybodyDance substantially outperforms state-of-the-art baselines in both IC and visual fidelity.
AUV-Fusion: Cross-Modal Adversarial Fusion of User Interactions and Visual Perturbations Against VARS
Jul 30, 2025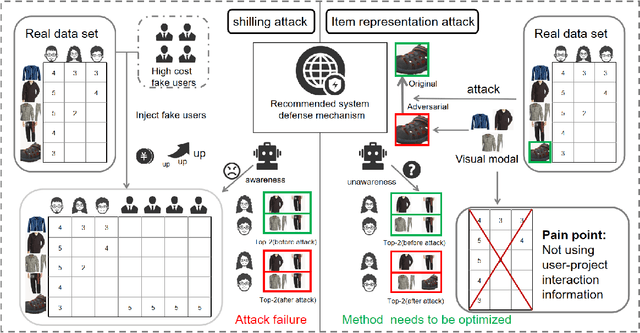



Modern Visual-Aware Recommender Systems (VARS) exploit the integration of user interaction data and visual features to deliver personalized recommendations with high precision. However, their robustness against adversarial attacks remains largely underexplored, posing significant risks to system reliability and security. Existing attack strategies suffer from notable limitations: shilling attacks are costly and detectable, and visual-only perturbations often fail to align with user preferences. To address these challenges, we propose AUV-Fusion, a cross-modal adversarial attack framework that adopts high-order user preference modeling and cross-modal adversary generation. Specifically, we obtain robust user embeddings through multi-hop user-item interactions and transform them via an MLP into semantically aligned perturbations. These perturbations are injected onto the latent space of a pre-trained VAE within the diffusion model. By synergistically integrating genuine user interaction data with visually plausible perturbations, AUV-Fusion eliminates the need for injecting fake user profiles and effectively mitigates the challenge of insufficient user preference extraction inherent in traditional visual-only attacks. Comprehensive evaluations on diverse VARS architectures and real-world datasets demonstrate that AUV-Fusion significantly enhances the exposure of target (cold-start) items compared to conventional baseline methods. Moreover, AUV-Fusion maintains exceptional stealth under rigorous scrutiny.
ChronoTailor: Harnessing Attention Guidance for Fine-Grained Video Virtual Try-On
Jun 06, 2025Video virtual try-on aims to seamlessly replace the clothing of a person in a source video with a target garment. Despite significant progress in this field, existing approaches still struggle to maintain continuity and reproduce garment details. In this paper, we introduce ChronoTailor, a diffusion-based framework that generates temporally consistent videos while preserving fine-grained garment details. By employing a precise spatio-temporal attention mechanism to guide the integration of fine-grained garment features, ChronoTailor achieves robust try-on performance. First, ChronoTailor leverages region-aware spatial guidance to steer the evolution of spatial attention and employs an attention-driven temporal feature fusion mechanism to generate more continuous temporal features. This dual approach not only enables fine-grained local editing but also effectively mitigates artifacts arising from video dynamics. Second, ChronoTailor integrates multi-scale garment features to preserve low-level visual details and incorporates a garment-pose feature alignment to ensure temporal continuity during dynamic motion. Additionally, we collect StyleDress, a new dataset featuring intricate garments, varied environments, and diverse poses, offering advantages over existing public datasets, and will be publicly available for research. Extensive experiments show that ChronoTailor maintains spatio-temporal continuity and preserves garment details during motion, significantly outperforming previous methods.
EgoBlind: Towards Egocentric Visual Assistance for the Blind People
Mar 11, 2025We present EgoBlind, the first egocentric VideoQA dataset collected from blind individuals to evaluate the assistive capabilities of contemporary multimodal large language models (MLLMs). EgoBlind comprises 1,210 videos that record the daily lives of real blind users from a first-person perspective. It also features 4,927 questions directly posed or generated and verified by blind individuals to reflect their needs for visual assistance under various scenarios. We provide each question with an average of 3 reference answers to alleviate subjective evaluation. Using EgoBlind, we comprehensively evaluate 15 leading MLLMs and find that all models struggle, with the best performers achieving accuracy around 56\%, far behind human performance of 87.4\%. To guide future advancements, we identify and summarize major limitations of existing MLLMs in egocentric visual assistance for the blind and provide heuristic suggestions for improvement. With these efforts, we hope EgoBlind can serve as a valuable foundation for developing more effective AI assistants to enhance the independence of the blind individuals' lives.
Integrate Temporal Graph Learning into LLM-based Temporal Knowledge Graph Model
Jan 21, 2025Temporal Knowledge Graph Forecasting (TKGF) aims to predict future events based on the observed events in history. Recently, Large Language Models (LLMs) have exhibited remarkable capabilities, generating significant research interest in their application for reasoning over temporal knowledge graphs (TKGs). Existing LLM-based methods have integrated retrieved historical facts or static graph representations into LLMs. Despite the notable performance of LLM-based methods, they are limited by the insufficient modeling of temporal patterns and ineffective cross-modal alignment between graph and language, hindering the ability of LLMs to fully grasp the temporal and structural information in TKGs. To tackle these issues, we propose a novel framework TGL-LLM to integrate temporal graph learning into LLM-based temporal knowledge graph model. Specifically, we introduce temporal graph learning to capture the temporal and relational patterns and obtain the historical graph embedding. Furthermore, we design a hybrid graph tokenization to sufficiently model the temporal patterns within LLMs. To achieve better alignment between graph and language, we employ a two-stage training paradigm to finetune LLMs on high-quality and diverse data, thereby resulting in better performance. Extensive experiments on three real-world datasets show that our approach outperforms a range of state-of-the-art (SOTA) methods.
VideoQA in the Era of LLMs: An Empirical Study
Aug 08, 2024



Video Large Language Models (Video-LLMs) are flourishing and has advanced many video-language tasks. As a golden testbed, Video Question Answering (VideoQA) plays pivotal role in Video-LLM developing. This work conducts a timely and comprehensive study of Video-LLMs' behavior in VideoQA, aiming to elucidate their success and failure modes, and provide insights towards more human-like video understanding and question answering. Our analyses demonstrate that Video-LLMs excel in VideoQA; they can correlate contextual cues and generate plausible responses to questions about varied video contents. However, models falter in handling video temporality, both in reasoning about temporal content ordering and grounding QA-relevant temporal moments. Moreover, the models behave unintuitively - they are unresponsive to adversarial video perturbations while being sensitive to simple variations of candidate answers and questions. Also, they do not necessarily generalize better. The findings demonstrate Video-LLMs' QA capability in standard condition yet highlight their severe deficiency in robustness and interpretability, suggesting the urgent need on rationales in Video-LLM developing.
Harnessing Large Language Models for Multimodal Product Bundling
Jul 16, 2024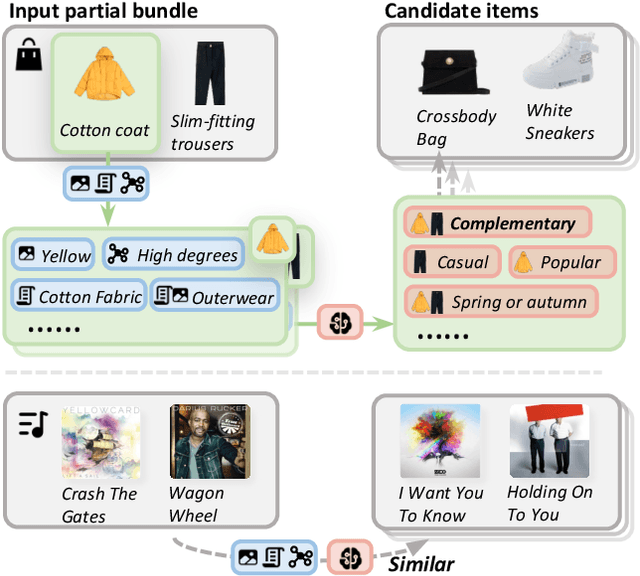

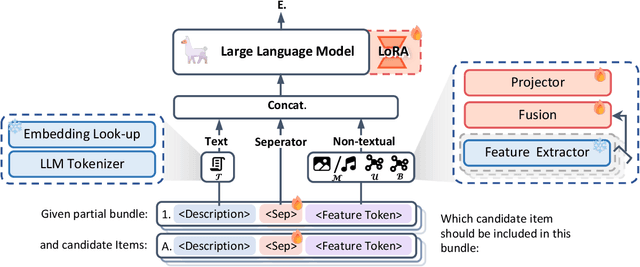
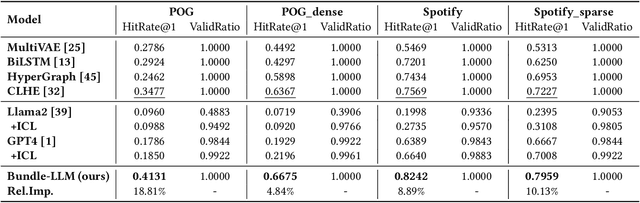
Product bundling provides clients with a strategic combination of individual items.And it has gained significant attention in recent years as a fundamental prerequisite for online services. Recent methods utilize multimodal information through sophisticated extractors for bundling, but remain limited by inferior semantic understanding, the restricted scope of knowledge, and an inability to handle cold-start issues.Despite the extensive knowledge and complex reasoning capabilities of large language models (LLMs), their direct utilization fails to process multimodalities and exploit their knowledge for multimodal product bundling. Adapting LLMs for this purpose involves demonstrating the synergies among different modalities and designing an effective optimization strategy for bundling, which remains challenging.To this end, we introduce Bundle-LLM to bridge the gap between LLMs and product bundling tasks. Sepcifically, we utilize a hybrid item tokenization to integrate multimodal information, where a simple yet powerful multimodal fusion module followed by a trainable projector embeds all non-textual features into a single token. This module not only explicitly exhibits the interplays among modalities but also shortens the prompt length, thereby boosting efficiency.By designing a prompt template, we formulate product bundling as a multiple-choice question given candidate items. Furthermore, we adopt progressive optimization strategy to fine-tune the LLMs for disentangled objectives, achieving effective product bundling capability with comprehensive multimodal semantic understanding.Extensive experiments on four datasets from two application domains show that our approach outperforms a range of state-of-the-art (SOTA) methods.
Leveraging Multimodal Features and Item-level User Feedback for Bundle Construction
Oct 28, 2023



Automatic bundle construction is a crucial prerequisite step in various bundle-aware online services. Previous approaches are mostly designed to model the bundling strategy of existing bundles. However, it is hard to acquire large-scale well-curated bundle dataset, especially for those platforms that have not offered bundle services before. Even for platforms with mature bundle services, there are still many items that are included in few or even zero bundles, which give rise to sparsity and cold-start challenges in the bundle construction models. To tackle these issues, we target at leveraging multimodal features, item-level user feedback signals, and the bundle composition information, to achieve a comprehensive formulation of bundle construction. Nevertheless, such formulation poses two new technical challenges: 1) how to learn effective representations by optimally unifying multiple features, and 2) how to address the problems of modality missing, noise, and sparsity problems induced by the incomplete query bundles. In this work, to address these technical challenges, we propose a Contrastive Learning-enhanced Hierarchical Encoder method (CLHE). Specifically, we use self-attention modules to combine the multimodal and multi-item features, and then leverage both item- and bundle-level contrastive learning to enhance the representation learning, thus to counter the modality missing, noise, and sparsity problems. Extensive experiments on four datasets in two application domains demonstrate that our method outperforms a list of SOTA methods. The code and dataset are available at https://github.com/Xiaohao-Liu/CLHE.
INO at Factify 2: Structure Coherence based Multi-Modal Fact Verification
Mar 02, 2023



This paper describes our approach to the multi-modal fact verification (FACTIFY) challenge at AAAI2023. In recent years, with the widespread use of social media, fake news can spread rapidly and negatively impact social security. Automatic claim verification becomes more and more crucial to combat fake news. In fact verification involving multiple modal data, there should be a structural coherence between claim and document. Therefore, we proposed a structure coherence-based multi-modal fact verification scheme to classify fake news. Our structure coherence includes the following four aspects: sentence length, vocabulary similarity, semantic similarity, and image similarity. Specifically, CLIP and Sentence BERT are combined to extract text features, and ResNet50 is used to extract image features. In addition, we also extract the length of the text as well as the lexical similarity. Then the features were concatenated and passed through the random forest classifier. Finally, our weighted average F1 score has reached 0.8079, achieving 2nd place in FACTIFY2.
BiSTNet: Semantic Image Prior Guided Bidirectional Temporal Feature Fusion for Deep Exemplar-based Video Colorization
Dec 05, 2022



How to effectively explore the colors of reference exemplars and propagate them to colorize each frame is vital for exemplar-based video colorization. In this paper, we present an effective BiSTNet to explore colors of reference exemplars and utilize them to help video colorization by a bidirectional temporal feature fusion with the guidance of semantic image prior. We first establish the semantic correspondence between each frame and the reference exemplars in deep feature space to explore color information from reference exemplars. Then, to better propagate the colors of reference exemplars into each frame and avoid the inaccurate matches colors from exemplars we develop a simple yet effective bidirectional temporal feature fusion module to better colorize each frame. We note that there usually exist color-bleeding artifacts around the boundaries of the important objects in videos. To overcome this problem, we further develop a mixed expert block to extract semantic information for modeling the object boundaries of frames so that the semantic image prior can better guide the colorization process for better performance. In addition, we develop a multi-scale recurrent block to progressively colorize frames in a coarse-to-fine manner. Extensive experimental results demonstrate that the proposed BiSTNet performs favorably against state-of-the-art methods on the benchmark datasets. Our code will be made available at \url{https://yyang181.github.io/BiSTNet/}