 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Binary Edits Robust Multimodal Knowledge Editing with Adversarial Subspace Alignment
May 22, 2026Multimodal large language models (MLLMs) need efficient mechanisms to update knowledge without degrading existing capabilities. While intrinsic multimodal knowledge editing achieves strong reliability and locality, it often exhibits limited generality, failing to propagate edits across semantically equivalent visual and linguistic variations. This issue arises from the lack of explicit semantic supervision, rigid editing scopes, and biased anchoring to individual samples in high-dimensional multimodal spaces. We address robust intrinsic multimodal knowledge editing by explicitly targeting generalization. We formalize robustness through knowledge units that group semantically equivalent multimodal inputs and define generality as consistent predictions within each unit. To expose fragile semantic regions, we introduce Latent Adversarial Robustification (LAR), which generates adversarial yet semantically coherent variants in the joint latent space. We further propose Rank-Constrained Subspace Learning (RCSL), enforcing low-rank alignment of adversarial representations at the edit layer via a singular value-based objective. Extensive analysis demonstrates the effectiveness of ASAM empirically.
QuantClaw: Precision Where It Matters for OpenClaw
Apr 24, 2026Autonomous agent systems such as OpenClaw introduce significant efficiency challenges due to long-context inputs and multi-turn reasoning. This results in prohibitively high computational and monetary costs in real-world development. While quantization is a standard approach for reducing cost and latency, its impact on agent performance in realistic scenarios remains unclear. In this work, we analyze quantization sensitivity across diverse complex workflows over OpenClaw, and show that precision requirements are highly task-dependent. Based on this observation, we propose QuantClaw, a plug-and-play precision routing plugin that dynamically assigns precision according to task characteristics. QuantClaw routes lightweight tasks to lower-cost configurations while preserving higher precision for demanding workloads, saving cost and accelerating inference without increasing user complexity. Experiments show that our QuantClaw maintains or improves task performance while reducing both latency and computational cost. Across a range of agent tasks, it achieves up to 21.4% cost savings and 15.7% latency reduction on GLM-5 (FP8 baseline). These results highlight the benefit of treating precision as a dynamic resource in agent systems.
Omnimodal Dataset Distillation via High-order Proxy Alignment
Apr 12, 2026Dataset distillation compresses large-scale datasets into compact synthetic sets while preserving training performance, but existing methods are largely restricted to single-modal or bimodal settings. Extending dataset distillation to scenarios involving more than two modalities, i.e., Omnimodal Dataset Distillation, remains underexplored and challenging due to increased heterogeneity and complex cross-modal interactions. In this work, we identify the key determinant that bounds the endpoint discrepancy in the omnimodal setting, which is exacerbated with an increasing number of modalities. To this end, we propose HoPA, a unified method that captures high-order cross-modal alignments via a compact proxy, which is compatible with trajectory matching as well. By abstracting omnimodal alignment with a shared similarity structure, our method avoids the combinatorial complexity of pairwise modality modeling and enables scalable joint distillation across heterogeneous modalities. Theoretical analysis from the spectral perspective reveals the rationality of our proposed method against bimodal dataset distillation techniques. Extensive experiments on various benchmarks demonstrate that the proposed method achieves superior compression-performance trade-offs compared to existing competitors. The source code will be publicly released.
FreeAct: Freeing Activations for LLM Quantization
Mar 05, 2026Quantization is pivotal for mitigating the significant memory and computational overhead of Large Language Models (LLMs). While emerging transformation-based methods have successfully enhanced quantization by projecting feature spaces onto smoother manifolds using orthogonal matrices, they typically enforce a rigid one-to-one transformation constraint. This static approach fails to account for the dynamic patterns inherent in input activations, particularly within diffusion LLMs (dLLMs) and Multimodal LLMs (MLLMs), where varying token types exhibit distinct distributions. To advance this, we propose FreeAct, a novel quantization framework that relaxes the static one-to-one constraint to accommodate dynamic activation disparities. Theoretically, we leverage the rank-deficient nature of activations to derive a solution space that extends beyond simple inverse matrices, enabling the decoupling of activation transformations from weights. Methodologically, FreeAct identifies token-specific dynamics (i.e., vision v.s. text, or masked tokens) and allocates distinct transformation matrices to the activation side, while maintaining a unified, static transformation for the weights. Extensive experiments across dLLMs and MLLMs demonstrate that FreeAct significantly outperforms baselines, up to 5.3% performance improvement, with in-depth analyses. Our code will be publicly released.
Align Once, Benefit Multilingually: Enforcing Multilingual Consistency for LLM Safety Alignment
Feb 18, 2026The widespread deployment of large language models (LLMs) across linguistic communities necessitates reliable multilingual safety alignment. However, recent efforts to extend alignment to other languages often require substantial resources, either through large-scale, high-quality supervision in the target language or through pairwise alignment with high-resource languages, which limits scalability. In this work, we propose a resource-efficient method for improving multilingual safety alignment. We introduce a plug-and-play Multi-Lingual Consistency (MLC) loss that can be integrated into existing monolingual alignment pipelines. By improving collinearity between multilingual representation vectors, our method encourages directional consistency at the multilingual semantic level in a single update. This allows simultaneous alignment across multiple languages using only multilingual prompt variants without requiring additional response-level supervision in low-resource languages. We validate the proposed method across different model architectures and alignment paradigms, and demonstrate its effectiveness in enhancing multilingual safety with limited impact on general model utility. Further evaluation across languages and tasks indicates improved cross-lingual generalization, suggesting the proposed approach as a practical solution for multilingual consistency alignment under limited supervision.
Calibrated Multimodal Representation Learning with Missing Modalities
Nov 15, 2025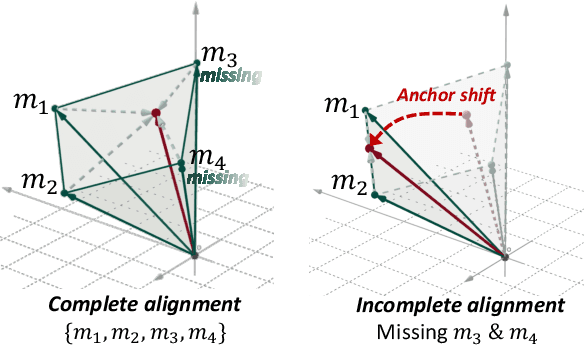
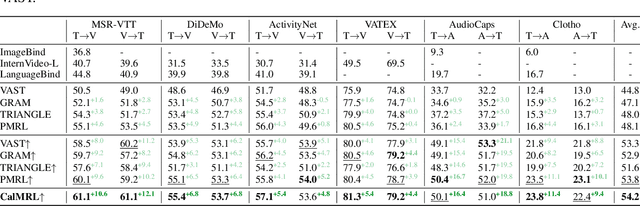
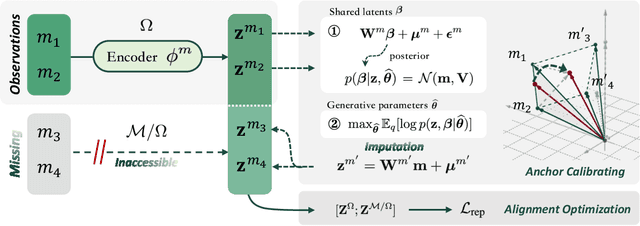
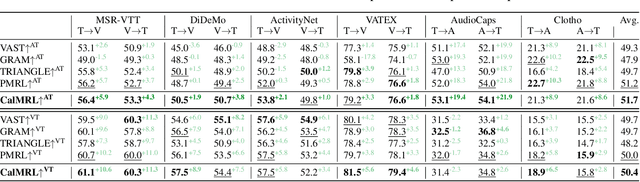
Multimodal representation learning harmonizes distinct modalities by aligning them into a unified latent space. Recent research generalizes traditional cross-modal alignment to produce enhanced multimodal synergy but requires all modalities to be present for a common instance, making it challenging to utilize prevalent datasets with missing modalities. We provide theoretical insights into this issue from an anchor shift perspective. Observed modalities are aligned with a local anchor that deviates from the optimal one when all modalities are present, resulting in an inevitable shift. To address this, we propose CalMRL for multimodal representation learning to calibrate incomplete alignments caused by missing modalities. Specifically, CalMRL leverages the priors and the inherent connections among modalities to model the imputation for the missing ones at the representation level. To resolve the optimization dilemma, we employ a bi-step learning method with the closed-form solution of the posterior distribution of shared latents. We validate its mitigation of anchor shift and convergence with theoretical guidance. By equipping the calibrated alignment with the existing advanced method, we offer new flexibility to absorb data with missing modalities, which is originally unattainable. Extensive experiments and comprehensive analyses demonstrate the superiority of CalMRL. Our code, model checkpoints, and evaluation raw data will be publicly available.
AUV-Fusion: Cross-Modal Adversarial Fusion of User Interactions and Visual Perturbations Against VARS
Jul 30, 2025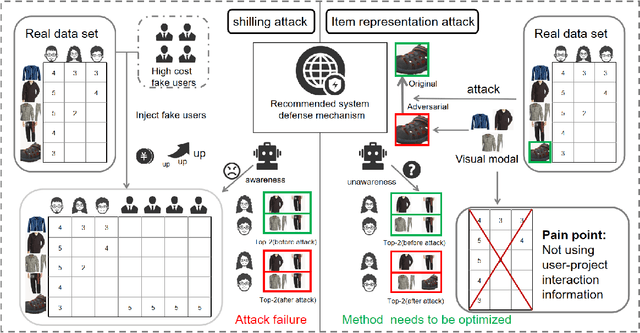



Modern Visual-Aware Recommender Systems (VARS) exploit the integration of user interaction data and visual features to deliver personalized recommendations with high precision. However, their robustness against adversarial attacks remains largely underexplored, posing significant risks to system reliability and security. Existing attack strategies suffer from notable limitations: shilling attacks are costly and detectable, and visual-only perturbations often fail to align with user preferences. To address these challenges, we propose AUV-Fusion, a cross-modal adversarial attack framework that adopts high-order user preference modeling and cross-modal adversary generation. Specifically, we obtain robust user embeddings through multi-hop user-item interactions and transform them via an MLP into semantically aligned perturbations. These perturbations are injected onto the latent space of a pre-trained VAE within the diffusion model. By synergistically integrating genuine user interaction data with visually plausible perturbations, AUV-Fusion eliminates the need for injecting fake user profiles and effectively mitigates the challenge of insufficient user preference extraction inherent in traditional visual-only attacks. Comprehensive evaluations on diverse VARS architectures and real-world datasets demonstrate that AUV-Fusion significantly enhances the exposure of target (cold-start) items compared to conventional baseline methods. Moreover, AUV-Fusion maintains exceptional stealth under rigorous scrutiny.
Principled Multimodal Representation Learning
Jul 23, 2025



Multimodal representation learning seeks to create a unified representation space by integrating diverse data modalities to improve multimodal understanding. Traditional methods often depend on pairwise contrastive learning, which relies on a predefined anchor modality, restricting alignment across all modalities. Recent advances have investigated the simultaneous alignment of multiple modalities, yet several challenges remain, such as limitations imposed by fixed anchor points and instability arising from optimizing the product of singular values. To address the challenges, in this paper, we propose Principled Multimodal Representation Learning (PMRL), a novel framework that achieves simultaneous alignment of multiple modalities without anchor dependency in a more stable manner. Specifically, grounded in the theoretical insight that full alignment corresponds to a rank-1 Gram matrix, PMRL optimizes the dominant singular value of the representation matrix to align modalities along a shared leading direction. We propose a softmax-based loss function that treats singular values as logits to prioritize the largest singular value. Besides, instance-wise contrastive regularization on the leading eigenvectors maintains inter-instance separability and prevents representation collapse. Extensive experiments across diverse tasks demonstrate PMRL's superiority compared to baseline methods. The source code will be publicly available.
AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint
Jun 08, 2025



As LLMs are increasingly deployed in real-world applications, ensuring their ability to refuse malicious prompts, especially jailbreak attacks, is essential for safe and reliable use. Recently, activation steering has emerged as an effective approach for enhancing LLM safety by adding a refusal direction vector to internal activations of LLMs during inference, which will further induce the refusal behaviors of LLMs. However, indiscriminately applying activation steering fundamentally suffers from the trade-off between safety and utility, since the same steering vector can also lead to over-refusal and degraded performance on benign prompts. Although prior efforts, such as vector calibration and conditional steering, have attempted to mitigate this trade-off, their lack of theoretical grounding limits their robustness and effectiveness. To better address the trade-off between safety and utility, we present a theoretically grounded and empirically effective activation steering method called AlphaSteer. Specifically, it considers activation steering as a learnable process with two principled learning objectives: utility preservation and safety enhancement. For utility preservation, it learns to construct a nearly zero vector for steering benign data, with the null-space constraints. For safety enhancement, it learns to construct a refusal direction vector for steering malicious data, with the help of linear regression. Experiments across multiple jailbreak attacks and utility benchmarks demonstrate the effectiveness of AlphaSteer, which significantly improves the safety of LLMs without compromising general capabilities. Our codes are available at https://github.com/AlphaLab-USTC/AlphaSteer.
L-MTP: Leap Multi-Token Prediction Beyond Adjacent Context for Large Language Models
May 23, 2025Large language models (LLMs) have achieved notable progress. Despite their success, next-token prediction (NTP), the dominant method for LLM training and inference, is constrained in both contextual coverage and inference efficiency due to its inherently sequential process. To overcome these challenges, we propose leap multi-token prediction~(L-MTP), an innovative token prediction method that extends the capabilities of multi-token prediction (MTP) by introducing a leap-based mechanism. Unlike conventional MTP, which generates multiple tokens at adjacent positions, L-MTP strategically skips over intermediate tokens, predicting non-sequential ones in a single forward pass. This structured leap not only enhances the model's ability to capture long-range dependencies but also enables a decoding strategy specially optimized for non-sequential leap token generation, effectively accelerating inference. We theoretically demonstrate the benefit of L-MTP in improving inference efficiency. Experiments across diverse benchmarks validate its merit in boosting both LLM performance and inference speed. The source code will be publicly available.