 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Selection to Scheduling: Federated Geometry-Aware Correction Makes Exemplar Replay Work Better under Continual Dynamic Heterogeneity
Apr 09, 2026Exemplar replay has become an effective strategy for mitigating catastrophic forgetting in federated continual learning (FCL) by retaining representative samples from past tasks. Existing studies focus on designing sample-importance estimation mechanisms to identify information-rich samples. However, they typically overlook strategies for effectively utilizing the selected exemplars, which limits their performance under continual dynamic heterogeneity across clients and tasks. To address this issue, this paper proposes a Federated gEometry-Aware correcTion method, termed FEAT, which alleviates imbalance-induced representation collapse that drags rare-class features toward frequent classes across clients. Specifically, it consists of two key modules: 1) the Geometric Structure Alignment module performs structural knowledge distillation by aligning the pairwise angular similarities between feature representations and their corresponding Equiangular Tight Frame prototypes, which are fixed and shared across clients to serve as a class-discriminative reference structure. This encourages geometric consistency across tasks and helps mitigate representation drift; 2) the Energy-based Geometric Correction module removes task-irrelevant directional components from feature embeddings, which reduces prediction bias toward majority classes. This improves sensitivity to minority classes and enhances the model's robustness under class-imbalanced distributions.
ProtoConNet: Prototypical Augmentation and Alignment for Open-Set Few-Shot Image Classification
Jul 16, 2025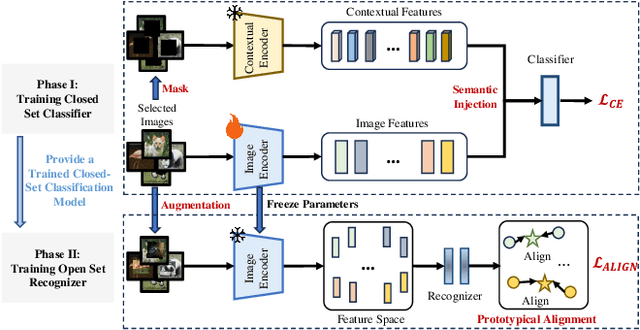
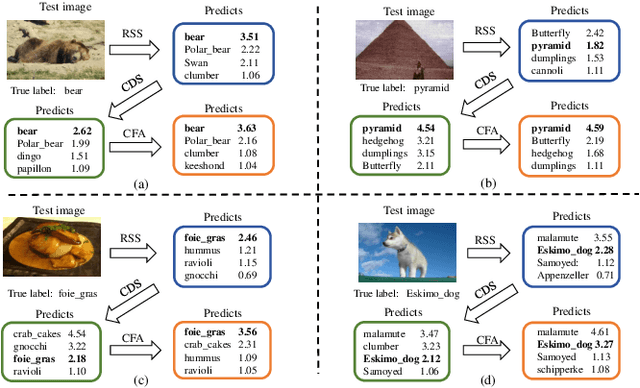
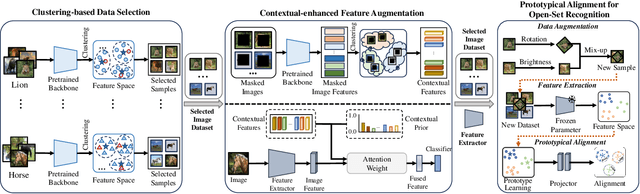
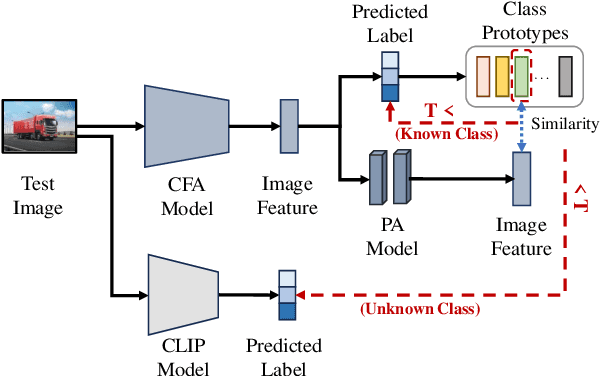
Open-set few-shot image classification aims to train models using a small amount of labeled data, enabling them to achieve good generalization when confronted with unknown environments. Existing methods mainly use visual information from a single image to learn class representations to distinguish known from unknown categories. However, these methods often overlook the benefits of integrating rich contextual information. To address this issue, this paper proposes a prototypical augmentation and alignment method, termed ProtoConNet, which incorporates background information from different samples to enhance the diversity of the feature space, breaking the spurious associations between context and image subjects in few-shot scenarios. Specifically, it consists of three main modules: the clustering-based data selection (CDS) module mines diverse data patterns while preserving core features; the contextual-enhanced semantic refinement (CSR) module builds a context dictionary to integrate into image representations, which boosts the model's robustness in various scenarios; and the prototypical alignment (PA) module reduces the gap between image representations and class prototypes, amplifying feature distances for known and unknown classes. Experimental results from two datasets verified that ProtoConNet enhances the effectiveness of representation learning in few-shot scenarios and identifies open-set samples, making it superior to existing methods.
Empowering Vision Transformers with Multi-Scale Causal Intervention for Long-Tailed Image Classification
May 13, 2025Causal inference has emerged as a promising approach to mitigate long-tail classification by handling the biases introduced by class imbalance. However, along with the change of advanced backbone models from Convolutional Neural Networks (CNNs) to Visual Transformers (ViT), existing causal models may not achieve an expected performance gain. This paper investigates the influence of existing causal models on CNNs and ViT variants, highlighting that ViT's global feature representation makes it hard for causal methods to model associations between fine-grained features and predictions, which leads to difficulties in classifying tail classes with similar visual appearance. To address these issues, this paper proposes TSCNet, a two-stage causal modeling method to discover fine-grained causal associations through multi-scale causal interventions. Specifically, in the hierarchical causal representation learning stage (HCRL), it decouples the background and objects, applying backdoor interventions at both the patch and feature level to prevent model from using class-irrelevant areas to infer labels which enhances fine-grained causal representation. In the counterfactual logits bias calibration stage (CLBC), it refines the optimization of model's decision boundary by adaptive constructing counterfactual balanced data distribution to remove the spurious associations in the logits caused by data distribution. Extensive experiments conducted on various long-tail benchmarks demonstrate that the proposed TSCNet can eliminate multiple biases introduced by data imbalance, which outperforms existing methods.
Semantic-Space-Intervened Diffusive Alignment for Visual Classification
May 09, 2025Cross-modal alignment is an effective approach to improving visual classification. Existing studies typically enforce a one-step mapping that uses deep neural networks to project the visual features to mimic the distribution of textual features. However, they typically face difficulties in finding such a projection due to the two modalities in both the distribution of class-wise samples and the range of their feature values. To address this issue, this paper proposes a novel Semantic-Space-Intervened Diffusive Alignment method, termed SeDA, models a semantic space as a bridge in the visual-to-textual projection, considering both types of features share the same class-level information in classification. More importantly, a bi-stage diffusion framework is developed to enable the progressive alignment between the two modalities. Specifically, SeDA first employs a Diffusion-Controlled Semantic Learner to model the semantic features space of visual features by constraining the interactive features of the diffusion model and the category centers of visual features. In the later stage of SeDA, the Diffusion-Controlled Semantic Translator focuses on learning the distribution of textual features from the semantic space. Meanwhile, the Progressive Feature Interaction Network introduces stepwise feature interactions at each alignment step, progressively integrating textual information into mapped features. Experimental results show that SeDA achieves stronger cross-modal feature alignment, leading to superior performance over existing methods across multiple scenarios.
Federated Deconfounding and Debiasing Learning for Out-of-Distribution Generalization
May 08, 2025Attribute bias in federated learning (FL) typically leads local models to optimize inconsistently due to the learning of non-causal associations, resulting degraded performance. Existing methods either use data augmentation for increasing sample diversity or knowledge distillation for learning invariant representations to address this problem. However, they lack a comprehensive analysis of the inference paths, and the interference from confounding factors limits their performance. To address these limitations, we propose the \underline{Fed}erated \underline{D}econfounding and \underline{D}ebiasing \underline{L}earning (FedDDL) method. It constructs a structured causal graph to analyze the model inference process, and performs backdoor adjustment to eliminate confounding paths. Specifically, we design an intra-client deconfounding learning module for computer vision tasks to decouple background and objects, generating counterfactual samples that establish a connection between the background and any label, which stops the model from using the background to infer the label. Moreover, we design an inter-client debiasing learning module to construct causal prototypes to reduce the proportion of the background in prototype components. Notably, it bridges the gap between heterogeneous representations via causal prototypical regularization. Extensive experiments on 2 benchmarking datasets demonstrate that \methodname{} significantly enhances the model capability to focus on main objects in unseen data, leading to 4.5\% higher Top-1 Accuracy on average over 9 state-of-the-art existing methods.
Towards Initialization-Agnostic Clustering with Iterative Adaptive Resonance Theory
May 07, 2025The clustering performance of Fuzzy Adaptive Resonance Theory (Fuzzy ART) is highly dependent on the preset vigilance parameter, where deviations in its value can lead to significant fluctuations in clustering results, severely limiting its practicality for non-expert users. Existing approaches generally enhance vigilance parameter robustness through adaptive mechanisms such as particle swarm optimization and fuzzy logic rules. However, they often introduce additional hyperparameters or complex frameworks that contradict the original simplicity of the algorithm. To address this, we propose Iterative Refinement Adaptive Resonance Theory (IR-ART), which integrates three key phases into a unified iterative framework: (1) Cluster Stability Detection: A dynamic stability detection module that identifies unstable clusters by analyzing the change of sample size (number of samples in the cluster) in iteration. (2) Unstable Cluster Deletion: An evolutionary pruning module that eliminates low-quality clusters. (3) Vigilance Region Expansion: A vigilance region expansion mechanism that adaptively adjusts similarity thresholds. Independent of the specific execution of clustering, these three phases sequentially focus on analyzing the implicit knowledge within the iterative process, adjusting weights and vigilance parameters, thereby laying a foundation for the next iteration. Experimental evaluation on 15 datasets demonstrates that IR-ART improves tolerance to suboptimal vigilance parameter values while preserving the parameter simplicity of Fuzzy ART. Case studies visually confirm the algorithm's self-optimization capability through iterative refinement, making it particularly suitable for non-expert users in resource-constrained scenarios.
LLM-Enabled Style and Content Regularization for Personalized Text-to-Image Generation
Apr 19, 2025The personalized text-to-image generation has rapidly advanced with the emergence of Stable Diffusion. Existing methods, which typically fine-tune models using embedded identifiers, often struggle with insufficient stylization and inaccurate image content due to reduced textual controllability. In this paper, we propose style refinement and content preservation strategies. The style refinement strategy leverages the semantic information of visual reasoning prompts and reference images to optimize style embeddings, allowing a more precise and consistent representation of style information. The content preservation strategy addresses the content bias problem by preserving the model's generalization capabilities, ensuring enhanced textual controllability without compromising stylization. Experimental results verify that our approach achieves superior performance in generating consistent and personalized text-to-image outputs.
Global Intervention and Distillation for Federated Out-of-Distribution Generalization
Apr 01, 2025Attribute skew in federated learning leads local models to focus on learning non-causal associations, guiding them towards inconsistent optimization directions, which inevitably results in performance degradation and unstable convergence. Existing methods typically leverage data augmentation to enhance sample diversity or employ knowledge distillation to learn invariant representations. However, the instability in the quality of generated data and the lack of domain information limit their performance on unseen samples. To address these issues, this paper presents a global intervention and distillation method, termed FedGID, which utilizes diverse attribute features for backdoor adjustment to break the spurious association between background and label. It includes two main modules, where the global intervention module adaptively decouples objects and backgrounds in images, injects background information into random samples to intervene in the sample distribution, which links backgrounds to all categories to prevent the model from treating background-label associations as causal. The global distillation module leverages a unified knowledge base to guide the representation learning of client models, preventing local models from overfitting to client-specific attributes. Experimental results on three datasets demonstrate that FedGID enhances the model's ability to focus on the main subjects in unseen data and outperforms existing methods in collaborative modeling.
Headache to Overstock? Promoting Long-tail Items through Debiased Product Bundling
Nov 28, 2024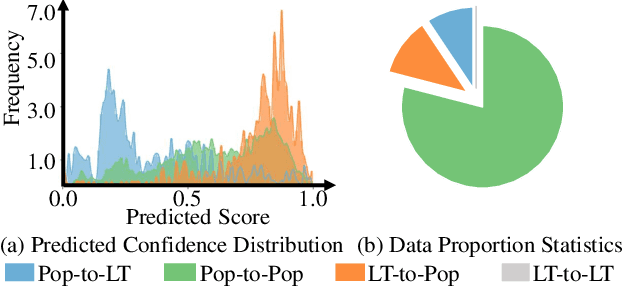

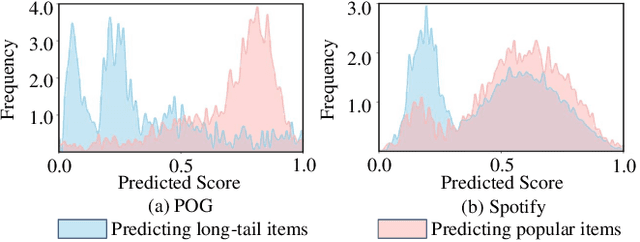
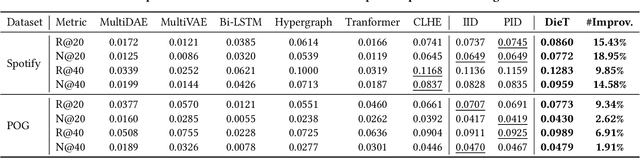
Product bundling aims to organize a set of thematically related items into a combined bundle for shipment facilitation and item promotion. To increase the exposure of fresh or overstocked products, sellers typically bundle these items with popular products for inventory clearance. This specific task can be formulated as a long-tail product bundling scenario, which leverages the user-item interactions to define the popularity of each item. The inherent popularity bias in the pre-extracted user feedback features and the insufficient utilization of other popularity-independent knowledge may force the conventional bundling methods to find more popular items, thereby struggling with this long-tail bundling scenario. Through intuitive and empirical analysis, we navigate the core solution for this challenge, which is maximally mining the popularity-free features and effectively incorporating them into the bundling process. To achieve this, we propose a Distilled Modality-Oriented Knowledge Transfer framework (DieT) to effectively counter the popularity bias misintroduced by the user feedback features and adhere to the original intent behind the real-world bundling behaviors. Specifically, DieT first proposes the Popularity-free Collaborative Distribution Modeling module (PCD) to capture the popularity-independent information from the bundle-item view, which is proven most effective in the long-tail bundling scenario to enable the directional information transfer. With the tailored Unbiased Bundle-aware Knowledge Transferring module (UBT), DieT can highlight the significance of popularity-free features while mitigating the negative effects of user feedback features in the long-tail scenario via the knowledge distillation paradigm. Extensive experiments on two real-world datasets demonstrate the superiority of DieT over a list of SOTA methods in the long-tail bundling scenario.
Negative Sampling in Recommendation: A Survey and Future Directions
Sep 11, 2024
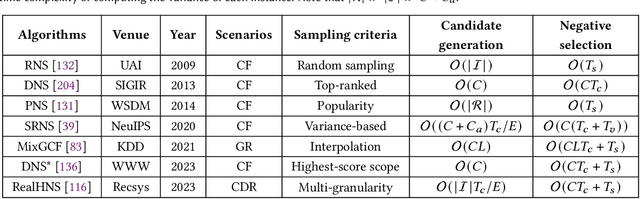

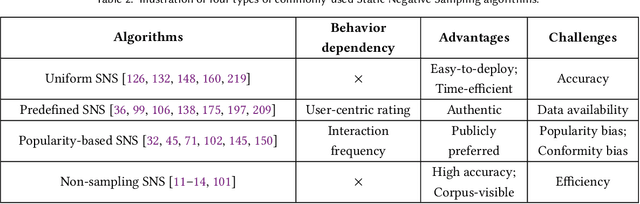
Recommender systems aim to capture users' personalized preferences from the cast amount of user behaviors, making them pivotal in the era of information explosion. However, the presence of the dynamic preference, the "information cocoons", and the inherent feedback loops in recommendation make users interact with a limited number of items. Conventional recommendation algorithms typically focus on the positive historical behaviors, while neglecting the essential role of negative feedback in user interest understanding. As a promising but easy-to-ignored area, negative sampling is proficients in revealing the genuine negative aspect inherent in user behaviors, emerging as an inescapable procedure in recommendation. In this survey, we first discuss the role of negative sampling in recommendation and thoroughly analyze challenges that consistently impede its progress. Then, we conduct an extensive literature review on the existing negative sampling strategies in recommendation and classify them into five categories with their discrepant techniques. Finally, we detail the insights of the tailored negative sampling strategies in diverse recommendation scenarios and outline an overview of the prospective research directions toward which the community may engage and benefit.