 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich-U-Net: A medical image segmentation model for fusing spatial depth features and capturing minute structural details
Mar 31, 2026Medical image segmentation is of great significance in analysis of illness. The use of deep neural networks in medical image segmentation can help doctors extract regions of interest from complex medical images, thereby improving diagnostic accuracy and enabling better assessment of the condition to formulate treatment plans. However, most current medical image segmentation methods underperform in accurately extracting spatial information from medical images and mining potential complex structures and variations. In this article, we introduce the Rich-U-Net model, which effectively integrates both spatial and depth features. This fusion enhances the model's capability to detect fine structures and intricate details within complex medical images. Our multi-level and multi-dimensional feature fusion and optimization strategies enable our model to achieve fine structure localization and accurate segmentation results in medical image segmentation. Experiments on the ISIC2018, BUSI, GLAS, and CVC datasets show that Rich-U-Net surpasses other state-of-the-art models in Dice, IoU, and HD95 metrics.
Orthogonal Model Merging
Feb 05, 2026Merging finetuned Large Language Models (LLMs) has become increasingly important for integrating diverse capabilities into a single unified model. However, prevailing model merging methods rely on linear arithmetic in Euclidean space, which often destroys the intrinsic geometric properties of pretrained weights, such as hyperspherical energy. To address this, we propose Orthogonal Model Merging (OrthoMerge), a method that performs merging operations on the Riemannian manifold formed by the orthogonal group to preserve the geometric structure of the model's weights. By mapping task-specific orthogonal matrices learned by Orthogonal Finetuning (OFT) to the Lie algebra, OrthoMerge enables a principled yet efficient integration that takes into account both the direction and intensity of adaptations. In addition to directly leveraging orthogonal matrices obtained by OFT, we further extend this approach to general models finetuned with non-OFT methods (i.e., low-rank finetuning, full finetuning) via an Orthogonal-Residual Decoupling strategy. This technique extracts the orthogonal components of expert models by solving the orthogonal Procrustes problem, which are then merged on the manifold of the orthogonal group, while the remaining linear residuals are processed through standard additive merging. Extensive empirical results demonstrate the effectiveness of OrthoMerge in mitigating catastrophic forgetting and maintaining model performance across diverse tasks.
ProtoConNet: Prototypical Augmentation and Alignment for Open-Set Few-Shot Image Classification
Jul 16, 2025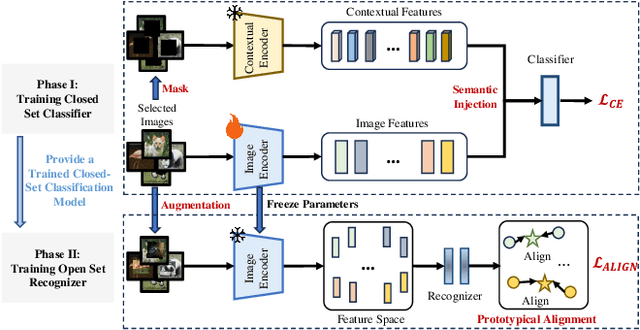
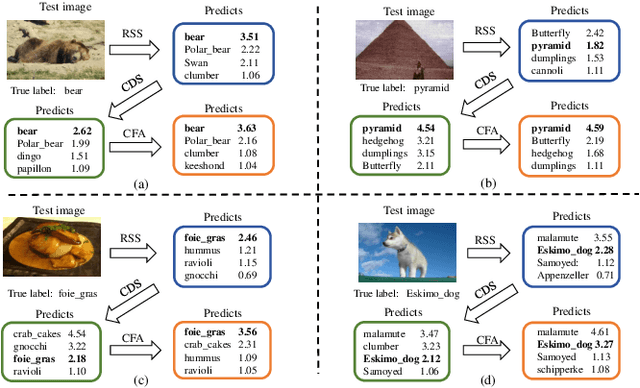
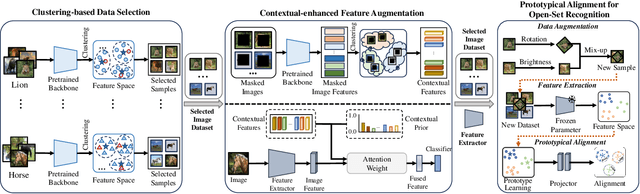
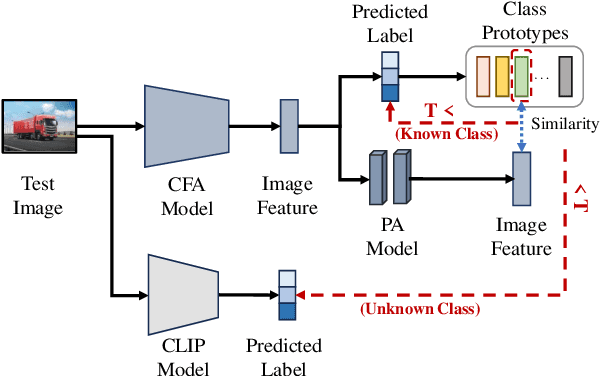
Open-set few-shot image classification aims to train models using a small amount of labeled data, enabling them to achieve good generalization when confronted with unknown environments. Existing methods mainly use visual information from a single image to learn class representations to distinguish known from unknown categories. However, these methods often overlook the benefits of integrating rich contextual information. To address this issue, this paper proposes a prototypical augmentation and alignment method, termed ProtoConNet, which incorporates background information from different samples to enhance the diversity of the feature space, breaking the spurious associations between context and image subjects in few-shot scenarios. Specifically, it consists of three main modules: the clustering-based data selection (CDS) module mines diverse data patterns while preserving core features; the contextual-enhanced semantic refinement (CSR) module builds a context dictionary to integrate into image representations, which boosts the model's robustness in various scenarios; and the prototypical alignment (PA) module reduces the gap between image representations and class prototypes, amplifying feature distances for known and unknown classes. Experimental results from two datasets verified that ProtoConNet enhances the effectiveness of representation learning in few-shot scenarios and identifies open-set samples, making it superior to existing methods.
Learning Pixel-adaptive Multi-layer Perceptrons for Real-time Image Enhancement
Jul 16, 2025Deep learning-based bilateral grid processing has emerged as a promising solution for image enhancement, inherently encoding spatial and intensity information while enabling efficient full-resolution processing through slicing operations. However, existing approaches are limited to linear affine transformations, hindering their ability to model complex color relationships. Meanwhile, while multi-layer perceptrons (MLPs) excel at non-linear mappings, traditional MLP-based methods employ globally shared parameters, which is hard to deal with localized variations. To overcome these dual challenges, we propose a Bilateral Grid-based Pixel-Adaptive Multi-layer Perceptron (BPAM) framework. Our approach synergizes the spatial modeling of bilateral grids with the non-linear capabilities of MLPs. Specifically, we generate bilateral grids containing MLP parameters, where each pixel dynamically retrieves its unique transformation parameters and obtain a distinct MLP for color mapping based on spatial coordinates and intensity values. In addition, we propose a novel grid decomposition strategy that categorizes MLP parameters into distinct types stored in separate subgrids. Multi-channel guidance maps are used to extract category-specific parameters from corresponding subgrids, ensuring effective utilization of color information during slicing while guiding precise parameter generation. Extensive experiments on public datasets demonstrate that our method outperforms state-of-the-art methods in performance while maintaining real-time processing capabilities.
Consistency Trajectory Matching for One-Step Generative Super-Resolution
Mar 27, 2025Current diffusion-based super-resolution (SR) approaches achieve commendable performance at the cost of high inference overhead. Therefore, distillation techniques are utilized to accelerate the multi-step teacher model into one-step student model. Nevertheless, these methods significantly raise training costs and constrain the performance of the student model by the teacher model. To overcome these tough challenges, we propose Consistency Trajectory Matching for Super-Resolution (CTMSR), a distillation-free strategy that is able to generate photo-realistic SR results in one step. Concretely, we first formulate a Probability Flow Ordinary Differential Equation (PF-ODE) trajectory to establish a deterministic mapping from low-resolution (LR) images with noise to high-resolution (HR) images. Then we apply the Consistency Training (CT) strategy to directly learn the mapping in one step, eliminating the necessity of pre-trained diffusion model. To further enhance the performance and better leverage the ground-truth during the training process, we aim to align the distribution of SR results more closely with that of the natural images. To this end, we propose to minimize the discrepancy between their respective PF-ODE trajectories from the LR image distribution by our meticulously designed Distribution Trajectory Matching (DTM) loss, resulting in improved realism of our recovered HR images. Comprehensive experimental results demonstrate that the proposed methods can attain comparable or even superior capabilities on both synthetic and real datasets while maintaining minimal inference latency.
Inductive Gradient Adjustment For Spectral Bias In Implicit Neural Representations
Oct 17, 2024



Implicit Neural Representations (INRs), as a versatile representation paradigm, have achieved success in various computer vision tasks. Due to the spectral bias of the vanilla multi-layer perceptrons (MLPs), existing methods focus on designing MLPs with sophisticated architectures or repurposing training techniques for highly accurate INRs. In this paper, we delve into the linear dynamics model of MLPs and theoretically identify the empirical Neural Tangent Kernel (eNTK) matrix as a reliable link between spectral bias and training dynamics. Based on eNTK matrix, we propose a practical inductive gradient adjustment method, which could purposefully improve the spectral bias via inductive generalization of eNTK-based gradient transformation matrix. We evaluate our method on different INRs tasks with various INR architectures and compare to existing training techniques. The superior representation performance clearly validates the advantage of our proposed method. Armed with our gradient adjustment method, better INRs with more enhanced texture details and sharpened edges can be learned from data by tailored improvements on spectral bias.
Improved Implicit Neural Representation with Fourier Bases Reparameterized Training
Feb 05, 2024



Implicit Neural Representation (INR) as a mighty representation paradigm has achieved success in various computer vision tasks recently. Due to the low-frequency bias issue of vanilla multi-layer perceptron (MLP), existing methods have investigated advanced techniques, such as positional encoding and periodic activation function, to improve the accuracy of INR. In this paper, we connect the network training bias with the reparameterization technique and theoretically prove that weight reparameterization could provide us a chance to alleviate the spectral bias of MLP. Based on our theoretical analysis, we propose a Fourier reparameterization method which learns coefficient matrix of fixed Fourier bases to compose the weights of MLP. We evaluate the proposed Fourier reparameterization method on different INR tasks with various MLP architectures, including vanilla MLP, MLP with positional encoding and MLP with advanced activation function, etc. The superiority approximation results on different MLP architectures clearly validate the advantage of our proposed method. Armed with our Fourier reparameterization method, better INR with more textures and less artifacts can be learned from the training data.