 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRCF: Two-Stage Groupwise Ranking and Calibration Framework for Multimodal Sentiment Analysis
Jan 14, 2026Most Multimodal Sentiment Analysis research has focused on point-wise regression. While straightforward, this approach is sensitive to label noise and neglects whether one sample is more positive than another, resulting in unstable predictions and poor correlation alignment. Pairwise ordinal learning frameworks emerged to address this gap, capturing relative order by learning from comparisons. Yet, they introduce two new trade-offs: First, they assign uniform importance to all comparisons, failing to adaptively focus on hard-to-rank samples. Second, they employ static ranking margins, which fail to reflect the varying semantic distances between sentiment groups. To address this, we propose a Two-Stage Group-wise Ranking and Calibration Framework (GRCF) that adapts the philosophy of Group Relative Policy Optimization (GRPO). Our framework resolves these trade-offs by simultaneously preserving relative ordinal structure, ensuring absolute score calibration, and adaptively focusing on difficult samples. Specifically, Stage 1 introduces a GRPO-inspired Advantage-Weighted Dynamic Margin Ranking Loss to build a fine-grained ordinal structure. Stage 2 then employs an MAE-driven objective to align prediction magnitudes. To validate its generalizability, we extend GRCF to classification tasks, including multimodal humor detection and sarcasm detection. GRCF achieves state-of-the-art performance on core regression benchmarks, while also showing strong generalizability in classification tasks.
Generative Image Compression by Estimating Gradients of the Rate-variable Feature Distribution
May 27, 2025While learned image compression (LIC) focuses on efficient data transmission, generative image compression (GIC) extends this framework by integrating generative modeling to produce photo-realistic reconstructed images. In this paper, we propose a novel diffusion-based generative modeling framework tailored for generative image compression. Unlike prior diffusion-based approaches that indirectly exploit diffusion modeling, we reinterpret the compression process itself as a forward diffusion path governed by stochastic differential equations (SDEs). A reverse neural network is trained to reconstruct images by reversing the compression process directly, without requiring Gaussian noise initialization. This approach achieves smooth rate adjustment and photo-realistic reconstructions with only a minimal number of sampling steps. Extensive experiments on benchmark datasets demonstrate that our method outperforms existing generative image compression approaches across a range of metrics, including perceptual distortion, statistical fidelity, and no-reference quality assessments.
Neural Stereo Video Compression with Hybrid Disparity Compensation
Apr 29, 2025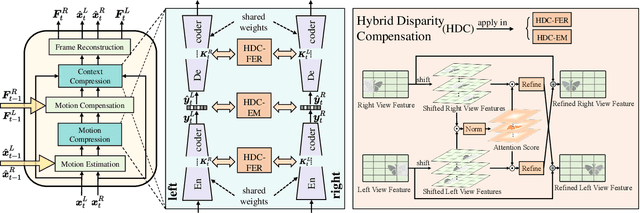
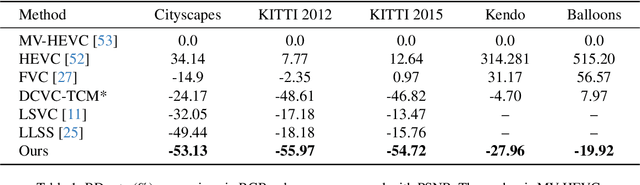
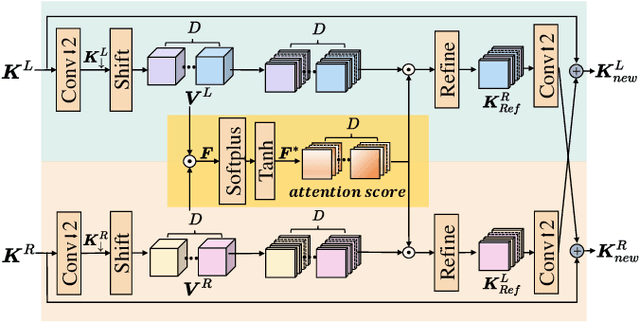
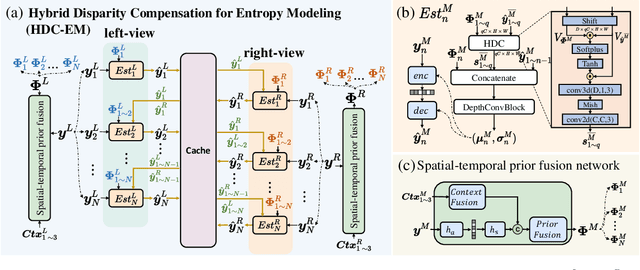
Disparity compensation represents the primary strategy in stereo video compression (SVC) for exploiting cross-view redundancy. These mechanisms can be broadly categorized into two types: one that employs explicit horizontal shifting, and another that utilizes an implicit cross-attention mechanism to reduce cross-view disparity redundancy. In this work, we propose a hybrid disparity compensation (HDC) strategy that leverages explicit pixel displacement as a robust prior feature to simplify optimization and perform implicit cross-attention mechanisms for subsequent warping operations, thereby capturing a broader range of disparity information. Specifically, HDC first computes a similarity map by fusing the horizontally shifted cross-view features to capture pixel displacement information. This similarity map is then normalized into an "explicit pixel-wise attention score" to perform the cross-attention mechanism, implicitly aligning features from one view to another. Building upon HDC, we introduce a novel end-to-end optimized neural stereo video compression framework, which integrates HDC-based modules into key coding operations, including cross-view feature extraction and reconstruction (HDC-FER) and cross-view entropy modeling (HDC-EM). Extensive experiments on SVC benchmarks, including KITTI 2012, KITTI 2015, and Nagoya, which cover both autonomous driving and general scenes, demonstrate that our framework outperforms both neural and traditional SVC methodologies.
Learned Image Compression with Dictionary-based Entropy Model
Apr 01, 2025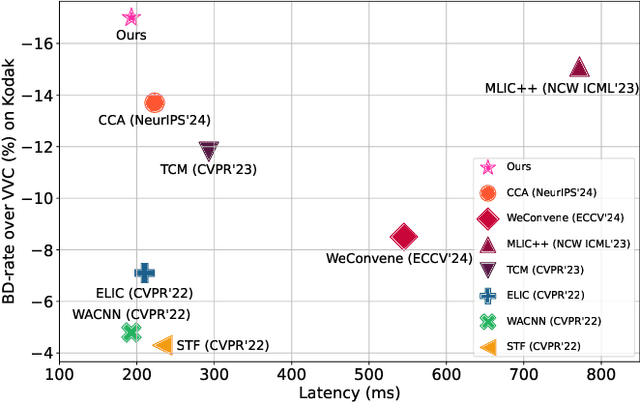
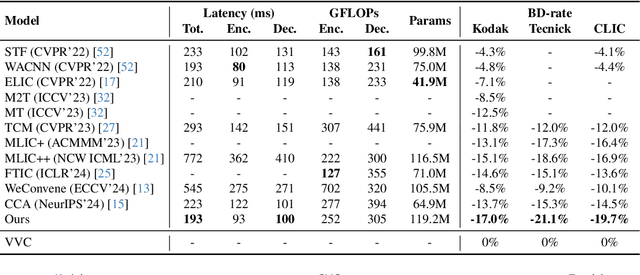
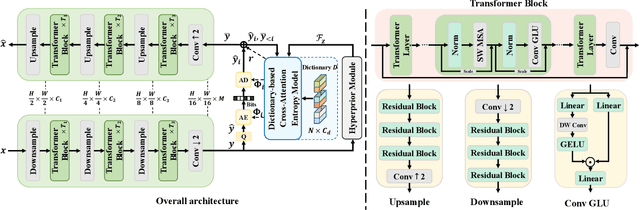
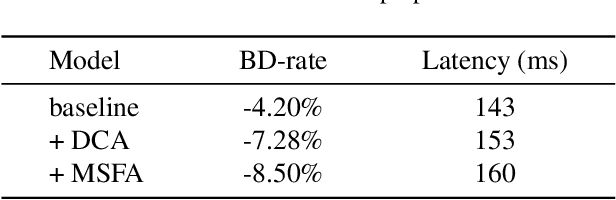
Learned image compression methods have attracted great research interest and exhibited superior rate-distortion performance to the best classical image compression standards of the present. The entropy model plays a key role in learned image compression, which estimates the probability distribution of the latent representation for further entropy coding. Most existing methods employed hyper-prior and auto-regressive architectures to form their entropy models. However, they only aimed to explore the internal dependencies of latent representation while neglecting the importance of extracting prior from training data. In this work, we propose a novel entropy model named Dictionary-based Cross Attention Entropy model, which introduces a learnable dictionary to summarize the typical structures occurring in the training dataset to enhance the entropy model. Extensive experimental results have demonstrated that the proposed model strikes a better balance between performance and latency, achieving state-of-the-art results on various benchmark datasets.
Consistency Trajectory Matching for One-Step Generative Super-Resolution
Mar 27, 2025Current diffusion-based super-resolution (SR) approaches achieve commendable performance at the cost of high inference overhead. Therefore, distillation techniques are utilized to accelerate the multi-step teacher model into one-step student model. Nevertheless, these methods significantly raise training costs and constrain the performance of the student model by the teacher model. To overcome these tough challenges, we propose Consistency Trajectory Matching for Super-Resolution (CTMSR), a distillation-free strategy that is able to generate photo-realistic SR results in one step. Concretely, we first formulate a Probability Flow Ordinary Differential Equation (PF-ODE) trajectory to establish a deterministic mapping from low-resolution (LR) images with noise to high-resolution (HR) images. Then we apply the Consistency Training (CT) strategy to directly learn the mapping in one step, eliminating the necessity of pre-trained diffusion model. To further enhance the performance and better leverage the ground-truth during the training process, we aim to align the distribution of SR results more closely with that of the natural images. To this end, we propose to minimize the discrepancy between their respective PF-ODE trajectories from the LR image distribution by our meticulously designed Distribution Trajectory Matching (DTM) loss, resulting in improved realism of our recovered HR images. Comprehensive experimental results demonstrate that the proposed methods can attain comparable or even superior capabilities on both synthetic and real datasets while maintaining minimal inference latency.
Progressive Focused Transformer for Single Image Super-Resolution
Mar 26, 2025Transformer-based methods have achieved remarkable results in image super-resolution tasks because they can capture non-local dependencies in low-quality input images. However, this feature-intensive modeling approach is computationally expensive because it calculates the similarities between numerous features that are irrelevant to the query features when obtaining attention weights. These unnecessary similarity calculations not only degrade the reconstruction performance but also introduce significant computational overhead. How to accurately identify the features that are important to the current query features and avoid similarity calculations between irrelevant features remains an urgent problem. To address this issue, we propose a novel and effective Progressive Focused Transformer (PFT) that links all isolated attention maps in the network through Progressive Focused Attention (PFA) to focus attention on the most important tokens. PFA not only enables the network to capture more critical similar features, but also significantly reduces the computational cost of the overall network by filtering out irrelevant features before calculating similarities. Extensive experiments demonstrate the effectiveness of the proposed method, achieving state-of-the-art performance on various single image super-resolution benchmarks.
Inductive Gradient Adjustment For Spectral Bias In Implicit Neural Representations
Oct 17, 2024



Implicit Neural Representations (INRs), as a versatile representation paradigm, have achieved success in various computer vision tasks. Due to the spectral bias of the vanilla multi-layer perceptrons (MLPs), existing methods focus on designing MLPs with sophisticated architectures or repurposing training techniques for highly accurate INRs. In this paper, we delve into the linear dynamics model of MLPs and theoretically identify the empirical Neural Tangent Kernel (eNTK) matrix as a reliable link between spectral bias and training dynamics. Based on eNTK matrix, we propose a practical inductive gradient adjustment method, which could purposefully improve the spectral bias via inductive generalization of eNTK-based gradient transformation matrix. We evaluate our method on different INRs tasks with various INR architectures and compare to existing training techniques. The superior representation performance clearly validates the advantage of our proposed method. Armed with our gradient adjustment method, better INRs with more enhanced texture details and sharpened edges can be learned from data by tailored improvements on spectral bias.
Transcending the Limit of Local Window: Advanced Super-Resolution Transformer with Adaptive Token Dictionary
Jan 18, 2024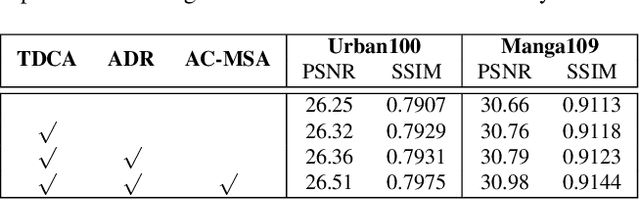
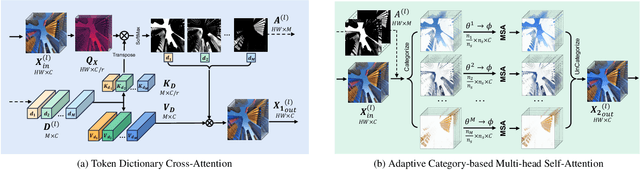
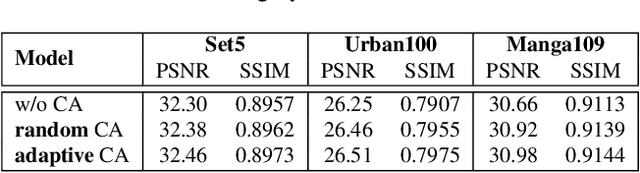
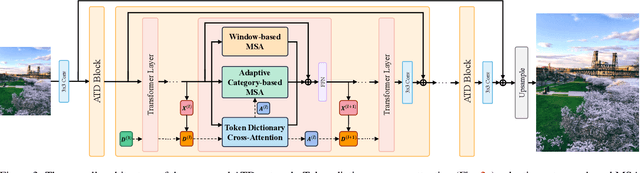
Single Image Super-Resolution is a classic computer vision problem that involves estimating high-resolution (HR) images from low-resolution (LR) ones. Although deep neural networks (DNNs), especially Transformers for super-resolution, have seen significant advancements in recent years, challenges still remain, particularly in limited receptive field caused by window-based self-attention. To address these issues, we introduce a group of auxiliary Adaptive Token Dictionary to SR Transformer and establish an ATD-SR method. The introduced token dictionary could learn prior information from training data and adapt the learned prior to specific testing image through an adaptive refinement step. The refinement strategy could not only provide global information to all input tokens but also group image tokens into categories. Based on category partitions, we further propose a category-based self-attention mechanism designed to leverage distant but similar tokens for enhancing input features. The experimental results show that our method achieves the best performance on various single image super-resolution benchmarks.
Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
Jan 15, 2024


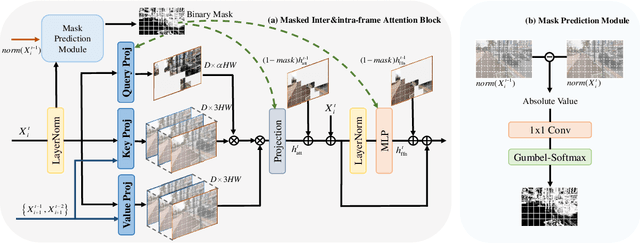
Recently, Vision Transformer has achieved great success in recovering missing details in low-resolution sequences, i.e., the video super-resolution (VSR) task. Despite its superiority in VSR accuracy, the heavy computational burden as well as the large memory footprint hinder the deployment of Transformer-based VSR models on constrained devices. In this paper, we address the above issue by proposing a novel feature-level masked processing framework: VSR with Masked Intra and inter frame Attention (MIA-VSR). The core of MIA-VSR is leveraging feature-level temporal continuity between adjacent frames to reduce redundant computations and make more rational use of previously enhanced SR features. Concretely, we propose an intra-frame and inter-frame attention block which takes the respective roles of past features and input features into consideration and only exploits previously enhanced features to provide supplementary information. In addition, an adaptive block-wise mask prediction module is developed to skip unimportant computations according to feature similarity between adjacent frames. We conduct detailed ablation studies to validate our contributions and compare the proposed method with recent state-of-the-art VSR approaches. The experimental results demonstrate that MIA-VSR improves the memory and computation efficiency over state-of-the-art methods, without trading off PSNR accuracy. The code is available at https://github.com/LabShuHangGU/MIA-VSR.
VITAL: A Visual Interpretation on Text with Adversarial Learning for Image Labeling
Aug 01, 2019

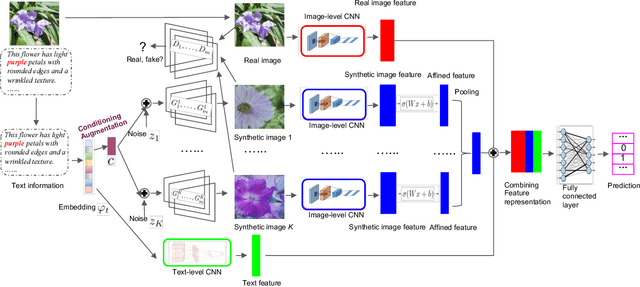
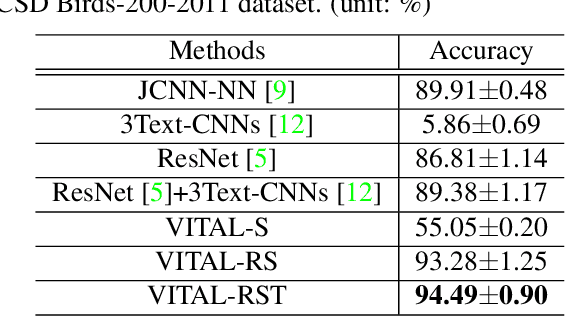
In this paper, we propose a novel way to interpret text information by extracting visual feature presentation from multiple high-resolution and photo-realistic synthetic images generated by Text-to-image Generative Adversarial Network (GAN) to improve the performance of image labeling. Firstly, we design a stacked Generative Multi-Adversarial Network (GMAN), StackGMAN++, a modified version of the current state-of-the-art Text-to-image GAN, StackGAN++, to generate multiple synthetic images with various prior noises conditioned on a text. And then we extract deep visual features from the generated synthetic images to explore the underlying visual concepts for text. Finally, we combine image-level visual feature, text-level feature and visual features based on synthetic images together to predict labels for images. We conduct experiments on two benchmark datasets and the experimental results clearly demonstrate the efficacy of our proposed approach.