 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Vector Quantization for Rate-Distortion Optimization of Generative Image Compression
Apr 12, 2026The rapid growth of visual data under stringent storage and bandwidth constraints makes extremely low-bitrate image compression increasingly important. While Vector Quantization (VQ) offers strong structural fidelity, existing methods lack a principled mechanism for joint rate-distortion (RD) optimization due to the disconnect between representation learning and entropy modeling. We propose RDVQ, a unified framework that enables end-to-end RD optimization for VQ-based compression via a differentiable relaxation of the codebook distribution, allowing the entropy loss to directly shape the latent prior. We further develop an autoregressive entropy model that supports accurate entropy modeling and test-time rate control. Extensive experiments demonstrate that RDVQ achieves strong performance at extremely low bitrates with a lightweight architecture, attaining competitive or superior perceptual quality with significantly fewer parameters. Compared with RDEIC, RDVQ reduces bitrate by up to 75.71% on DISTS and 37.63% on LPIPS on DIV2K-val. Beyond empirical gains, RDVQ introduces an entropy-constrained formulation of VQ, highlighting the potential for a more unified view of image tokenization and compression. The code will be available at https://github.com/CVL-UESTC/RDVQ.
IDESplat: Iterative Depth Probability Estimation for Generalizable 3D Gaussian Splatting
Jan 07, 2026Generalizable 3D Gaussian Splatting aims to directly predict Gaussian parameters using a feed-forward network for scene reconstruction. Among these parameters, Gaussian means are particularly difficult to predict, so depth is usually estimated first and then unprojected to obtain the Gaussian sphere centers. Existing methods typically rely solely on a single warp to estimate depth probability, which hinders their ability to fully leverage cross-view geometric cues, resulting in unstable and coarse depth maps. To address this limitation, we propose IDESplat, which iteratively applies warp operations to boost depth probability estimation for accurate Gaussian mean prediction. First, to eliminate the inherent instability of a single warp, we introduce a Depth Probability Boosting Unit (DPBU) that integrates epipolar attention maps produced by cascading warp operations in a multiplicative manner. Next, we construct an iterative depth estimation process by stacking multiple DPBUs, progressively identifying potential depth candidates with high likelihood. As IDESplat iteratively boosts depth probability estimates and updates the depth candidates, the depth map is gradually refined, resulting in accurate Gaussian means. We conduct experiments on RealEstate10K, ACID, and DL3DV. IDESplat achieves outstanding reconstruction quality and state-of-the-art performance with real-time efficiency. On RE10K, it outperforms DepthSplat by 0.33 dB in PSNR, using only 10.7% of the parameters and 70% of the memory. Additionally, our IDESplat improves PSNR by 2.95 dB over DepthSplat on the DTU dataset in cross-dataset experiments, demonstrating its strong generalization ability.
Small Clips, Big Gains: Learning Long-Range Refocused Temporal Information for Video Super-Resolution
May 04, 2025Video super-resolution (VSR) can achieve better performance compared to single image super-resolution by additionally leveraging temporal information. In particular, the recurrent-based VSR model exploits long-range temporal information during inference and achieves superior detail restoration. However, effectively learning these long-term dependencies within long videos remains a key challenge. To address this, we propose LRTI-VSR, a novel training framework for recurrent VSR that efficiently leverages Long-Range Refocused Temporal Information. Our framework includes a generic training strategy that utilizes temporal propagation features from long video clips while training on shorter video clips. Additionally, we introduce a refocused intra&inter-frame transformer block which allows the VSR model to selectively prioritize useful temporal information through its attention module while further improving inter-frame information utilization in the FFN module. We evaluate LRTI-VSR on both CNN and transformer-based VSR architectures, conducting extensive ablation studies to validate the contribution of each component. Experiments on long-video test sets demonstrate that LRTI-VSR achieves state-of-the-art performance while maintaining training and computational efficiency.
Neural Stereo Video Compression with Hybrid Disparity Compensation
Apr 29, 2025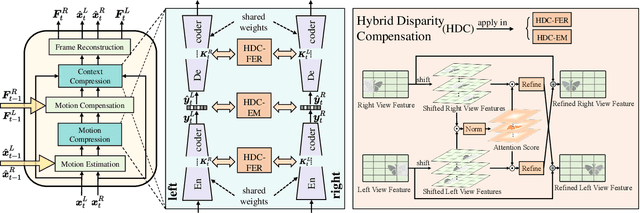
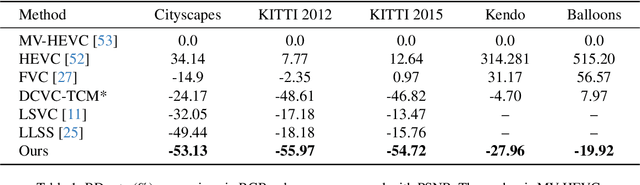
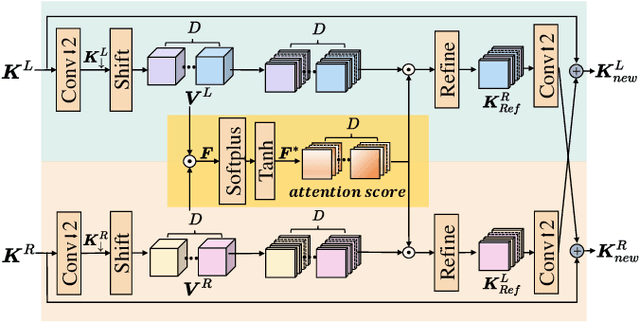
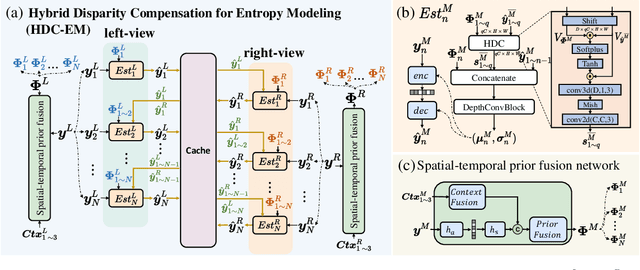
Disparity compensation represents the primary strategy in stereo video compression (SVC) for exploiting cross-view redundancy. These mechanisms can be broadly categorized into two types: one that employs explicit horizontal shifting, and another that utilizes an implicit cross-attention mechanism to reduce cross-view disparity redundancy. In this work, we propose a hybrid disparity compensation (HDC) strategy that leverages explicit pixel displacement as a robust prior feature to simplify optimization and perform implicit cross-attention mechanisms for subsequent warping operations, thereby capturing a broader range of disparity information. Specifically, HDC first computes a similarity map by fusing the horizontally shifted cross-view features to capture pixel displacement information. This similarity map is then normalized into an "explicit pixel-wise attention score" to perform the cross-attention mechanism, implicitly aligning features from one view to another. Building upon HDC, we introduce a novel end-to-end optimized neural stereo video compression framework, which integrates HDC-based modules into key coding operations, including cross-view feature extraction and reconstruction (HDC-FER) and cross-view entropy modeling (HDC-EM). Extensive experiments on SVC benchmarks, including KITTI 2012, KITTI 2015, and Nagoya, which cover both autonomous driving and general scenes, demonstrate that our framework outperforms both neural and traditional SVC methodologies.
Causal Context Adjustment Loss for Learned Image Compression
Oct 07, 2024



In recent years, learned image compression (LIC) technologies have surpassed conventional methods notably in terms of rate-distortion (RD) performance. Most present learned techniques are VAE-based with an autoregressive entropy model, which obviously promotes the RD performance by utilizing the decoded causal context. However, extant methods are highly dependent on the fixed hand-crafted causal context. The question of how to guide the auto-encoder to generate a more effective causal context benefit for the autoregressive entropy models is worth exploring. In this paper, we make the first attempt in investigating the way to explicitly adjust the causal context with our proposed Causal Context Adjustment loss (CCA-loss). By imposing the CCA-loss, we enable the neural network to spontaneously adjust important information into the early stage of the autoregressive entropy model. Furthermore, as transformer technology develops remarkably, variants of which have been adopted by many state-of-the-art (SOTA) LIC techniques. The existing computing devices have not adapted the calculation of the attention mechanism well, which leads to a burden on computation quantity and inference latency. To overcome it, we establish a convolutional neural network (CNN) image compression model and adopt the unevenly channel-wise grouped strategy for high efficiency. Ultimately, the proposed CNN-based LIC network trained with our Causal Context Adjustment loss attains a great trade-off between inference latency and rate-distortion performance.