 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREMAC: Reference-Based Martian Asymmetrical Image Compression
Jan 26, 2026To expedite space exploration on Mars, it is indispensable to develop an efficient Martian image compression method for transmitting images through the constrained Mars-to-Earth communication channel. Although the existing learned compression methods have achieved promising results for natural images from earth, there remain two critical issues that hinder their effectiveness for Martian image compression: 1) They overlook the highly-limited computational resources on Mars; 2) They do not utilize the strong \textit{inter-image} similarities across Martian images to advance image compression performance. Motivated by our empirical analysis of the strong \textit{intra-} and \textit{inter-image} similarities from the perspective of texture, color, and semantics, we propose a reference-based Martian asymmetrical image compression (REMAC) approach, which shifts computational complexity from the encoder to the resource-rich decoder and simultaneously improves compression performance. To leverage \textit{inter-image} similarities, we propose a reference-guided entropy module and a ref-decoder that utilize useful information from reference images, reducing redundant operations at the encoder and achieving superior compression performance. To exploit \textit{intra-image} similarities, the ref-decoder adopts a deep, multi-scale architecture with enlarged receptive field size to model long-range spatial dependencies. Additionally, we develop a latent feature recycling mechanism to further alleviate the extreme computational constraints on Mars. Experimental results show that REMAC reduces encoder complexity by 43.51\% compared to the state-of-the-art method, while achieving a BD-PSNR gain of 0.2664 dB.
* Accepted for publication in IEEE Transactions on Geoscience and Remote Sensing (TGRS). 2025 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. 18 pages, 20 figures
Benchmarking and Enhancing VLM for Compressed Image Understanding
Dec 24, 2025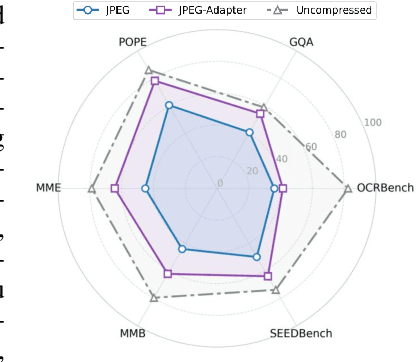


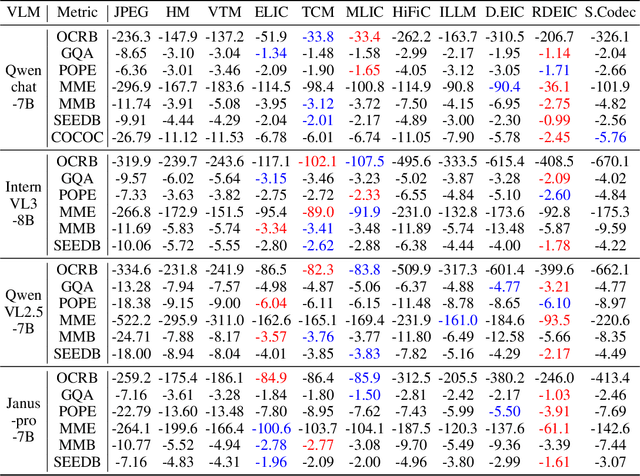
With the rapid development of Vision-Language Models (VLMs) and the growing demand for their applications, efficient compression of the image inputs has become increasingly important. Existing VLMs predominantly digest and understand high-bitrate compressed images, while their ability to interpret low-bitrate compressed images has yet to be explored by far. In this paper, we introduce the first comprehensive benchmark to evaluate the ability of VLM against compressed images, varying existing widely used image codecs and diverse set of tasks, encompassing over one million compressed images in our benchmark. Next, we analyse the source of performance gap, by categorising the gap from a) the information loss during compression and b) generalisation failure of VLM. We visualize these gaps with concrete examples and identify that for compressed images, only the generalization gap can be mitigated. Finally, we propose a universal VLM adaptor to enhance model performance on images compressed by existing codecs. Consequently, we demonstrate that a single adaptor can improve VLM performance across images with varying codecs and bitrates by 10%-30%. We believe that our benchmark and enhancement method provide valuable insights and contribute toward bridging the gap between VLMs and compressed images.
Machines Serve Human: A Novel Variable Human-machine Collaborative Compression Framework
Nov 12, 2025


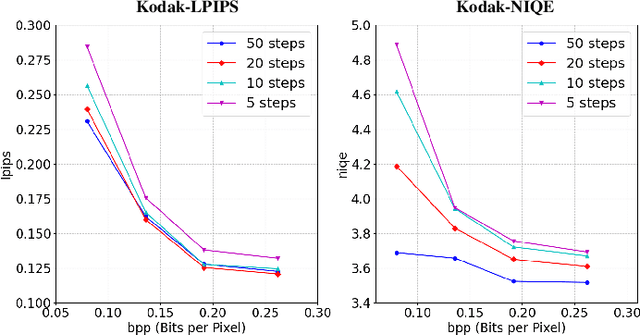
Human-machine collaborative compression has been receiving increasing research efforts for reducing image/video data, serving as the basis for both human perception and machine intelligence. Existing collaborative methods are dominantly built upon the de facto human-vision compression pipeline, witnessing deficiency on complexity and bit-rates when aggregating the machine-vision compression. Indeed, machine vision solely focuses on the core regions within the image/video, requiring much less information compared with the compressed information for human vision. In this paper, we thus set out the first successful attempt by a novel collaborative compression method based on the machine-vision-oriented compression, instead of human-vision pipeline. In other words, machine vision serves as the basis for human vision within collaborative compression. A plug-and-play variable bit-rate strategy is also developed for machine vision tasks. Then, we propose to progressively aggregate the semantics from the machine-vision compression, whilst seamlessly tailing the diffusion prior to restore high-fidelity details for human vision, thus named as diffusion-prior based feature compression for human and machine visions (Diff-FCHM). Experimental results verify the consistently superior performances of our Diff-FCHM, on both machine-vision and human-vision compression with remarkable margins. Our code will be released upon acceptance.
Burst Image Quality Assessment: A New Benchmark and Unified Framework for Multiple Downstream Tasks
Nov 11, 2025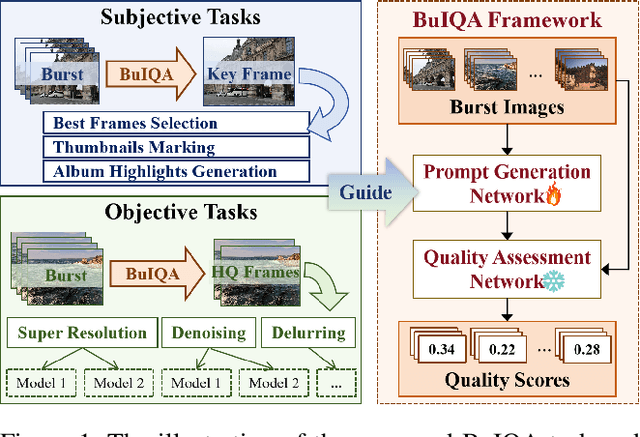
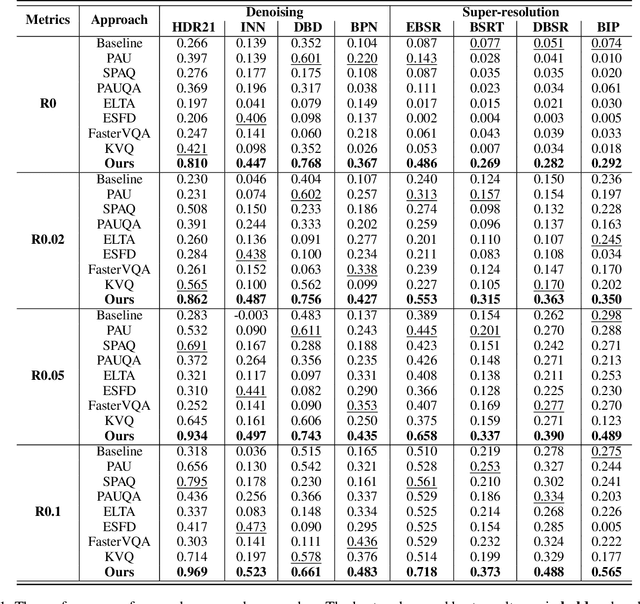

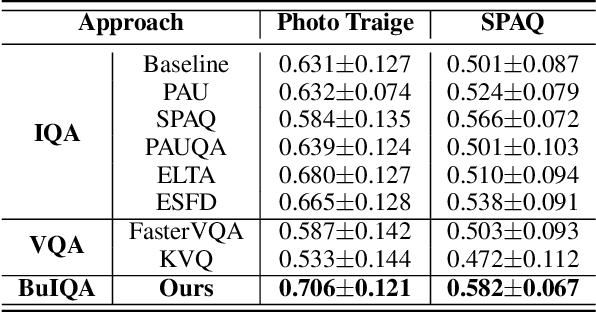
In recent years, the development of burst imaging technology has improved the capture and processing capabilities of visual data, enabling a wide range of applications. However, the redundancy in burst images leads to the increased storage and transmission demands, as well as reduced efficiency of downstream tasks. To address this, we propose a new task of Burst Image Quality Assessment (BuIQA), to evaluate the task-driven quality of each frame within a burst sequence, providing reasonable cues for burst image selection. Specifically, we establish the first benchmark dataset for BuIQA, consisting of $7,346$ burst sequences with $45,827$ images and $191,572$ annotated quality scores for multiple downstream scenarios. Inspired by the data analysis, a unified BuIQA framework is proposed to achieve an efficient adaption for BuIQA under diverse downstream scenarios. Specifically, a task-driven prompt generation network is developed with heterogeneous knowledge distillation, to learn the priors of the downstream task. Then, the task-aware quality assessment network is introduced to assess the burst image quality based on the task prompt. Extensive experiments across 10 downstream scenarios demonstrate the impressive BuIQA performance of the proposed approach, outperforming the state-of-the-art. Furthermore, it can achieve $0.33$ dB PSNR improvement in the downstream tasks of denoising and super-resolution, by applying our approach to select the high-quality burst frames.
Breaking the Multi-Enhancement Bottleneck: Domain-Consistent Quality Enhancement for Compressed Images
Jun 17, 2025Quality enhancement methods have been widely integrated into visual communication pipelines to mitigate artifacts in compressed images. Ideally, these quality enhancement methods should perform robustly when applied to images that have already undergone prior enhancement during transmission. We refer to this scenario as multi-enhancement, which generalizes the well-known multi-generation scenario of image compression. Unfortunately, current quality enhancement methods suffer from severe degradation when applied in multi-enhancement. To address this challenge, we propose a novel adaptation method that transforms existing quality enhancement models into domain-consistent ones. Specifically, our method enhances a low-quality compressed image into a high-quality image within the natural domain during the first enhancement, and ensures that subsequent enhancements preserve this quality without further degradation. Extensive experiments validate the effectiveness of our method and show that various existing models can be successfully adapted to maintain both fidelity and perceptual quality in multi-enhancement scenarios.
NTIRE 2025 Challenge on UGC Video Enhancement: Methods and Results
May 05, 2025This paper presents an overview of the NTIRE 2025 Challenge on UGC Video Enhancement. The challenge constructed a set of 150 user-generated content videos without reference ground truth, which suffer from real-world degradations such as noise, blur, faded colors, compression artifacts, etc. The goal of the participants was to develop an algorithm capable of improving the visual quality of such videos. Given the widespread use of UGC on short-form video platforms, this task holds substantial practical importance. The evaluation was based on subjective quality assessment in crowdsourcing, obtaining votes from over 8000 assessors. The challenge attracted more than 25 teams submitting solutions, 7 of which passed the final phase with source code verification. The outcomes may provide insights into the state-of-the-art in UGC video enhancement and highlight emerging trends and effective strategies in this evolving research area. All data, including the processed videos and subjective comparison votes and scores, is made publicly available at https://github.com/msu-video-group/NTIRE25_UGC_Video_Enhancement.
Continuous Patch Stitching for Block-wise Image Compression
Feb 24, 2025

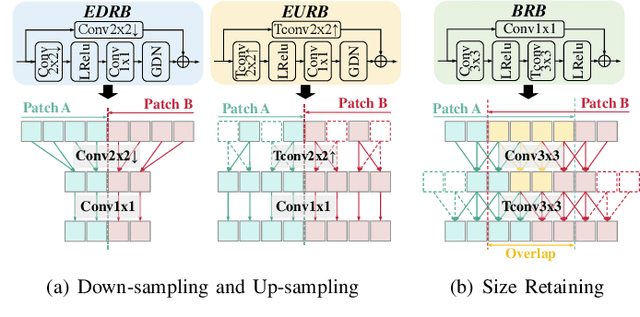

Most recently, learned image compression methods have outpaced traditional hand-crafted standard codecs. However, their inference typically requires to input the whole image at the cost of heavy computing resources, especially for high-resolution image compression; otherwise, the block artefact can exist when compressed by blocks within existing learned image compression methods. To address this issue, we propose a novel continuous patch stitching (CPS) framework for block-wise image compression that is able to achieve seamlessly patch stitching and mathematically eliminate block artefact, thus capable of significantly reducing the required computing resources when compressing images. More specifically, the proposed CPS framework is achieved by padding-free operations throughout, with a newly established parallel overlapping stitching strategy to provide a general upper bound for ensuring the continuity. Upon this, we further propose functional residual blocks with even-sized kernels to achieve down-sampling and up-sampling, together with bottleneck residual blocks retaining feature size to increase network depth. Experimental results demonstrate that our CPS framework achieves the state-of-the-art performance against existing baselines, whilst requiring less than half of computing resources of existing models. Our code shall be released upon acceptance.
Hierarchical Semantic Compression for Consistent Image Semantic Restoration
Feb 24, 2025The emerging semantic compression has been receiving increasing research efforts most recently, capable of achieving high fidelity restoration during compression, even at extremely low bitrates. However, existing semantic compression methods typically combine standard pipelines with either pre-defined or high-dimensional semantics, thus suffering from deficiency in compression. To address this issue, we propose a novel hierarchical semantic compression (HSC) framework that purely operates within intrinsic semantic spaces from generative models, which is able to achieve efficient compression for consistent semantic restoration. More specifically, we first analyse the entropy models for the semantic compression, which motivates us to employ a hierarchical architecture based on a newly developed general inversion encoder. Then, we propose the feature compression network (FCN) and semantic compression network (SCN), such that the middle-level semantic feature and core semantics are hierarchically compressed to restore both accuracy and consistency of image semantics, via an entropy model progressively shared by channel-wise context. Experimental results demonstrate that the proposed HSC framework achieves the state-of-the-art performance on subjective quality and consistency for human vision, together with superior performances on machine vision tasks given compressed bitstreams. This essentially coincides with human visual system in understanding images, thus providing a new framework for future image/video compression paradigms. Our code shall be released upon acceptance.
MarsSQE: Stereo Quality Enhancement for Martian Images Using Bi-level Cross-view Attention
Dec 30, 2024



Stereo images captured by Mars rovers are transmitted after lossy compression due to the limited bandwidth between Mars and Earth. Unfortunately, this process results in undesirable compression artifacts. In this paper, we present a novel stereo quality enhancement approach for Martian images, named MarsSQE. First, we establish the first dataset of stereo Martian images. Through extensive analysis of this dataset, we observe that cross-view correlations in Martian images are notably high. Leveraging this insight, we design a bi-level cross-view attention-based quality enhancement network that fully exploits these inherent cross-view correlations. Specifically, our network integrates pixel-level attention for precise matching and patch-level attention for broader contextual information. Experimental results demonstrate the effectiveness of our MarsSQE approach.
Causal Context Adjustment Loss for Learned Image Compression
Oct 07, 2024



In recent years, learned image compression (LIC) technologies have surpassed conventional methods notably in terms of rate-distortion (RD) performance. Most present learned techniques are VAE-based with an autoregressive entropy model, which obviously promotes the RD performance by utilizing the decoded causal context. However, extant methods are highly dependent on the fixed hand-crafted causal context. The question of how to guide the auto-encoder to generate a more effective causal context benefit for the autoregressive entropy models is worth exploring. In this paper, we make the first attempt in investigating the way to explicitly adjust the causal context with our proposed Causal Context Adjustment loss (CCA-loss). By imposing the CCA-loss, we enable the neural network to spontaneously adjust important information into the early stage of the autoregressive entropy model. Furthermore, as transformer technology develops remarkably, variants of which have been adopted by many state-of-the-art (SOTA) LIC techniques. The existing computing devices have not adapted the calculation of the attention mechanism well, which leads to a burden on computation quantity and inference latency. To overcome it, we establish a convolutional neural network (CNN) image compression model and adopt the unevenly channel-wise grouped strategy for high efficiency. Ultimately, the proposed CNN-based LIC network trained with our Causal Context Adjustment loss attains a great trade-off between inference latency and rate-distortion performance.