 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Enhancing VLM for Compressed Image Understanding
Dec 24, 2025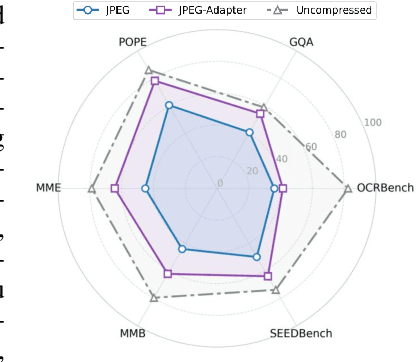


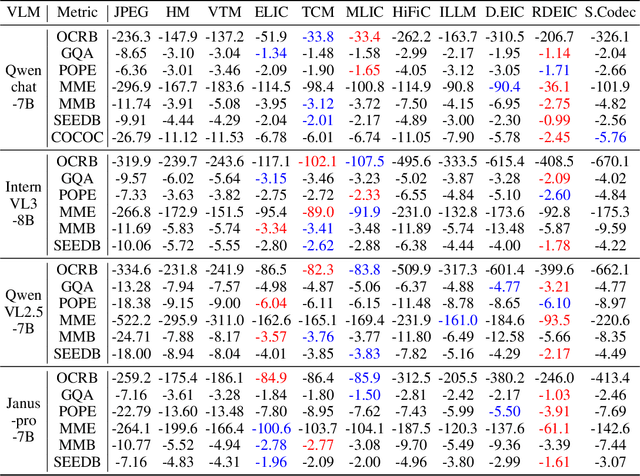
With the rapid development of Vision-Language Models (VLMs) and the growing demand for their applications, efficient compression of the image inputs has become increasingly important. Existing VLMs predominantly digest and understand high-bitrate compressed images, while their ability to interpret low-bitrate compressed images has yet to be explored by far. In this paper, we introduce the first comprehensive benchmark to evaluate the ability of VLM against compressed images, varying existing widely used image codecs and diverse set of tasks, encompassing over one million compressed images in our benchmark. Next, we analyse the source of performance gap, by categorising the gap from a) the information loss during compression and b) generalisation failure of VLM. We visualize these gaps with concrete examples and identify that for compressed images, only the generalization gap can be mitigated. Finally, we propose a universal VLM adaptor to enhance model performance on images compressed by existing codecs. Consequently, we demonstrate that a single adaptor can improve VLM performance across images with varying codecs and bitrates by 10%-30%. We believe that our benchmark and enhancement method provide valuable insights and contribute toward bridging the gap between VLMs and compressed images.
Machines Serve Human: A Novel Variable Human-machine Collaborative Compression Framework
Nov 12, 2025


Human-machine collaborative compression has been receiving increasing research efforts for reducing image/video data, serving as the basis for both human perception and machine intelligence. Existing collaborative methods are dominantly built upon the de facto human-vision compression pipeline, witnessing deficiency on complexity and bit-rates when aggregating the machine-vision compression. Indeed, machine vision solely focuses on the core regions within the image/video, requiring much less information compared with the compressed information for human vision. In this paper, we thus set out the first successful attempt by a novel collaborative compression method based on the machine-vision-oriented compression, instead of human-vision pipeline. In other words, machine vision serves as the basis for human vision within collaborative compression. A plug-and-play variable bit-rate strategy is also developed for machine vision tasks. Then, we propose to progressively aggregate the semantics from the machine-vision compression, whilst seamlessly tailing the diffusion prior to restore high-fidelity details for human vision, thus named as diffusion-prior based feature compression for human and machine visions (Diff-FCHM). Experimental results verify the consistently superior performances of our Diff-FCHM, on both machine-vision and human-vision compression with remarkable margins. Our code will be released upon acceptance.
Continuous Patch Stitching for Block-wise Image Compression
Feb 24, 2025

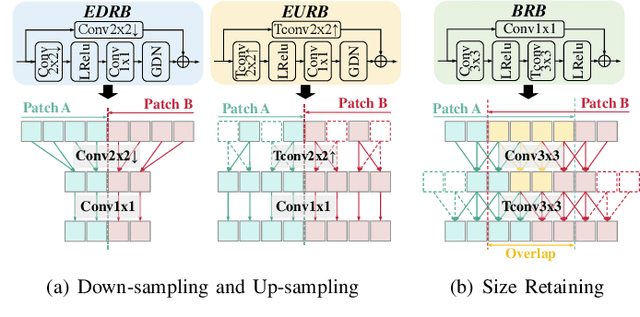

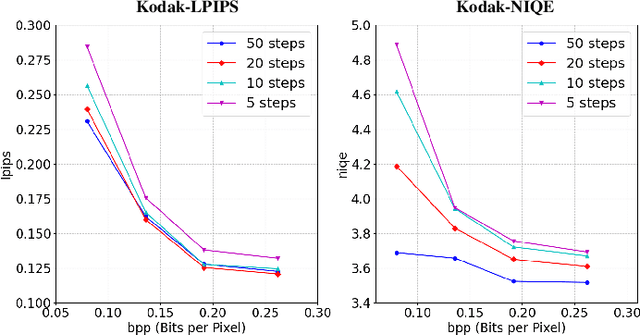
Most recently, learned image compression methods have outpaced traditional hand-crafted standard codecs. However, their inference typically requires to input the whole image at the cost of heavy computing resources, especially for high-resolution image compression; otherwise, the block artefact can exist when compressed by blocks within existing learned image compression methods. To address this issue, we propose a novel continuous patch stitching (CPS) framework for block-wise image compression that is able to achieve seamlessly patch stitching and mathematically eliminate block artefact, thus capable of significantly reducing the required computing resources when compressing images. More specifically, the proposed CPS framework is achieved by padding-free operations throughout, with a newly established parallel overlapping stitching strategy to provide a general upper bound for ensuring the continuity. Upon this, we further propose functional residual blocks with even-sized kernels to achieve down-sampling and up-sampling, together with bottleneck residual blocks retaining feature size to increase network depth. Experimental results demonstrate that our CPS framework achieves the state-of-the-art performance against existing baselines, whilst requiring less than half of computing resources of existing models. Our code shall be released upon acceptance.
Hierarchical Semantic Compression for Consistent Image Semantic Restoration
Feb 24, 2025The emerging semantic compression has been receiving increasing research efforts most recently, capable of achieving high fidelity restoration during compression, even at extremely low bitrates. However, existing semantic compression methods typically combine standard pipelines with either pre-defined or high-dimensional semantics, thus suffering from deficiency in compression. To address this issue, we propose a novel hierarchical semantic compression (HSC) framework that purely operates within intrinsic semantic spaces from generative models, which is able to achieve efficient compression for consistent semantic restoration. More specifically, we first analyse the entropy models for the semantic compression, which motivates us to employ a hierarchical architecture based on a newly developed general inversion encoder. Then, we propose the feature compression network (FCN) and semantic compression network (SCN), such that the middle-level semantic feature and core semantics are hierarchically compressed to restore both accuracy and consistency of image semantics, via an entropy model progressively shared by channel-wise context. Experimental results demonstrate that the proposed HSC framework achieves the state-of-the-art performance on subjective quality and consistency for human vision, together with superior performances on machine vision tasks given compressed bitstreams. This essentially coincides with human visual system in understanding images, thus providing a new framework for future image/video compression paradigms. Our code shall be released upon acceptance.