 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATD: Improved Transformer with Adaptive Token Dictionary for Image Restoration
Mar 03, 2026Recently, Transformers have gained significant popularity in image restoration tasks such as image super-resolution and denoising, owing to their superior performance. However, balancing performance and computational burden remains a long-standing problem for transformer-based architectures. Due to the quadratic complexity of self-attention, existing methods often restrict attention to local windows, resulting in limited receptive field and suboptimal performance. To address this issue, we propose Adaptive Token Dictionary (ATD), a novel transformer-based architecture for image restoration that enables global dependency modeling with linear complexity relative to image size. The ATD model incorporates a learnable token dictionary, which summarizes external image priors (i.e., typical image structures) during the training process. To utilize this information, we introduce a token dictionary cross-attention (TDCA) mechanism that enhances the input features via interaction with the learned dictionary. Furthermore, we exploit the category information embedded in the TDCA attention maps to group input features into multiple categories, each representing a cluster of similar features across the image and serving as an attention group. We also integrate the learned category information into the feed-forward network to further improve feature fusion. ATD and its lightweight version ATD-light, achieve state-of-the-art performance on multiple image super-resolution benchmarks. Moreover, we develop ATD-U, a multi-scale variant of ATD, to address other image restoration tasks, including image denoising and JPEG compression artifacts removal. Extensive experiments demonstrate the superiority of out proposed models, both quantitatively and qualitatively.
Learning Pixel-adaptive Multi-layer Perceptrons for Real-time Image Enhancement
Jul 16, 2025Deep learning-based bilateral grid processing has emerged as a promising solution for image enhancement, inherently encoding spatial and intensity information while enabling efficient full-resolution processing through slicing operations. However, existing approaches are limited to linear affine transformations, hindering their ability to model complex color relationships. Meanwhile, while multi-layer perceptrons (MLPs) excel at non-linear mappings, traditional MLP-based methods employ globally shared parameters, which is hard to deal with localized variations. To overcome these dual challenges, we propose a Bilateral Grid-based Pixel-Adaptive Multi-layer Perceptron (BPAM) framework. Our approach synergizes the spatial modeling of bilateral grids with the non-linear capabilities of MLPs. Specifically, we generate bilateral grids containing MLP parameters, where each pixel dynamically retrieves its unique transformation parameters and obtain a distinct MLP for color mapping based on spatial coordinates and intensity values. In addition, we propose a novel grid decomposition strategy that categorizes MLP parameters into distinct types stored in separate subgrids. Multi-channel guidance maps are used to extract category-specific parameters from corresponding subgrids, ensuring effective utilization of color information during slicing while guiding precise parameter generation. Extensive experiments on public datasets demonstrate that our method outperforms state-of-the-art methods in performance while maintaining real-time processing capabilities.
HiLLIE: Human-in-the-Loop Training for Low-Light Image Enhancement
May 04, 2025Developing effective approaches to generate enhanced results that align well with human visual preferences for high-quality well-lit images remains a challenge in low-light image enhancement (LLIE). In this paper, we propose a human-in-the-loop LLIE training framework that improves the visual quality of unsupervised LLIE model outputs through iterative training stages, named HiLLIE. At each stage, we introduce human guidance into the training process through efficient visual quality annotations of enhanced outputs. Subsequently, we employ a tailored image quality assessment (IQA) model to learn human visual preferences encoded in the acquired labels, which is then utilized to guide the training process of an enhancement model. With only a small amount of pairwise ranking annotations required at each stage, our approach continually improves the IQA model's capability to simulate human visual assessment of enhanced outputs, thus leading to visually appealing LLIE results. Extensive experiments demonstrate that our approach significantly improves unsupervised LLIE model performance in terms of both quantitative and qualitative performance. The code and collected ranking dataset will be available at https://github.com/LabShuHangGU/HiLLIE.
Transcending the Limit of Local Window: Advanced Super-Resolution Transformer with Adaptive Token Dictionary
Jan 18, 2024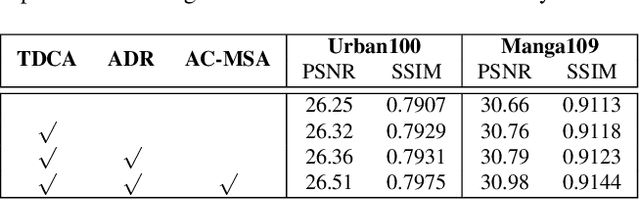
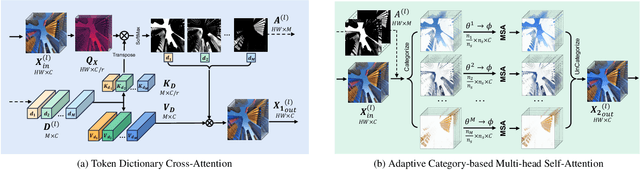
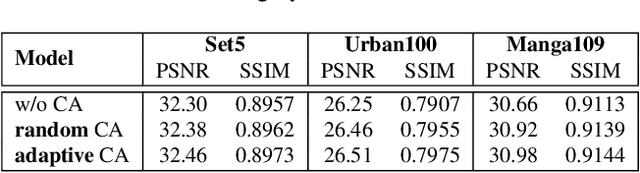
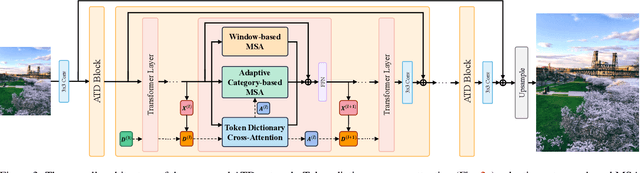
Single Image Super-Resolution is a classic computer vision problem that involves estimating high-resolution (HR) images from low-resolution (LR) ones. Although deep neural networks (DNNs), especially Transformers for super-resolution, have seen significant advancements in recent years, challenges still remain, particularly in limited receptive field caused by window-based self-attention. To address these issues, we introduce a group of auxiliary Adaptive Token Dictionary to SR Transformer and establish an ATD-SR method. The introduced token dictionary could learn prior information from training data and adapt the learned prior to specific testing image through an adaptive refinement step. The refinement strategy could not only provide global information to all input tokens but also group image tokens into categories. Based on category partitions, we further propose a category-based self-attention mechanism designed to leverage distant but similar tokens for enhancing input features. The experimental results show that our method achieves the best performance on various single image super-resolution benchmarks.
Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
Jan 15, 2024


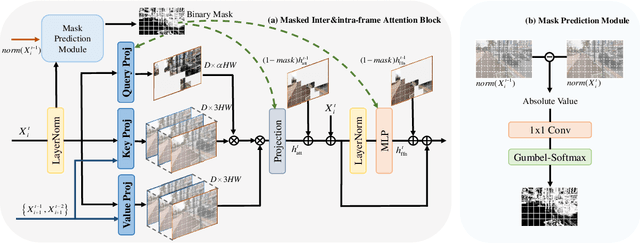
Recently, Vision Transformer has achieved great success in recovering missing details in low-resolution sequences, i.e., the video super-resolution (VSR) task. Despite its superiority in VSR accuracy, the heavy computational burden as well as the large memory footprint hinder the deployment of Transformer-based VSR models on constrained devices. In this paper, we address the above issue by proposing a novel feature-level masked processing framework: VSR with Masked Intra and inter frame Attention (MIA-VSR). The core of MIA-VSR is leveraging feature-level temporal continuity between adjacent frames to reduce redundant computations and make more rational use of previously enhanced SR features. Concretely, we propose an intra-frame and inter-frame attention block which takes the respective roles of past features and input features into consideration and only exploits previously enhanced features to provide supplementary information. In addition, an adaptive block-wise mask prediction module is developed to skip unimportant computations according to feature similarity between adjacent frames. We conduct detailed ablation studies to validate our contributions and compare the proposed method with recent state-of-the-art VSR approaches. The experimental results demonstrate that MIA-VSR improves the memory and computation efficiency over state-of-the-art methods, without trading off PSNR accuracy. The code is available at https://github.com/LabShuHangGU/MIA-VSR.