 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosterVerse: A Full-Workflow Framework for Commercial-Grade Poster Generation with HTML-Based Scalable Typography
Jan 07, 2026Commercial-grade poster design demands the seamless integration of aesthetic appeal with precise, informative content delivery. Current automated poster generation systems face significant limitations, including incomplete design workflows, poor text rendering accuracy, and insufficient flexibility for commercial applications. To address these challenges, we propose PosterVerse, a full-workflow, commercial-grade poster generation method that seamlessly automates the entire design process while delivering high-density and scalable text rendering. PosterVerse replicates professional design through three key stages: (1) blueprint creation using fine-tuned LLMs to extract key design elements from user requirements, (2) graphical background generation via customized diffusion models to create visually appealing imagery, and (3) unified layout-text rendering with an MLLM-powered HTML engine to guarantee high text accuracy and flexible customization. In addition, we introduce PosterDNA, a commercial-grade, HTML-based dataset tailored for training and validating poster design models. To the best of our knowledge, PosterDNA is the first Chinese poster generation dataset to introduce HTML typography files, enabling scalable text rendering and fundamentally solving the challenges of rendering small and high-density text. Experimental results demonstrate that PosterVerse consistently produces commercial-grade posters with appealing visuals, accurate text alignment, and customizable layouts, making it a promising solution for automating commercial poster design. The code and model are available at https://github.com/wuhaer/PosterVerse.
HiLLIE: Human-in-the-Loop Training for Low-Light Image Enhancement
May 04, 2025Developing effective approaches to generate enhanced results that align well with human visual preferences for high-quality well-lit images remains a challenge in low-light image enhancement (LLIE). In this paper, we propose a human-in-the-loop LLIE training framework that improves the visual quality of unsupervised LLIE model outputs through iterative training stages, named HiLLIE. At each stage, we introduce human guidance into the training process through efficient visual quality annotations of enhanced outputs. Subsequently, we employ a tailored image quality assessment (IQA) model to learn human visual preferences encoded in the acquired labels, which is then utilized to guide the training process of an enhancement model. With only a small amount of pairwise ranking annotations required at each stage, our approach continually improves the IQA model's capability to simulate human visual assessment of enhanced outputs, thus leading to visually appealing LLIE results. Extensive experiments demonstrate that our approach significantly improves unsupervised LLIE model performance in terms of both quantitative and qualitative performance. The code and collected ranking dataset will be available at https://github.com/LabShuHangGU/HiLLIE.
Cross Attention Based Style Distribution for Controllable Person Image Synthesis
Aug 01, 2022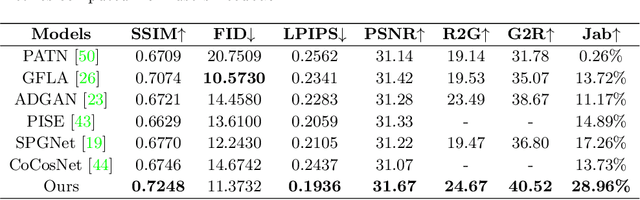
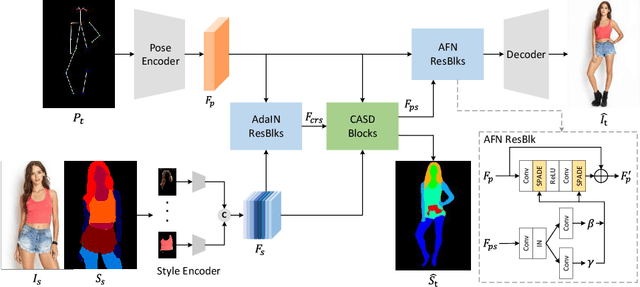
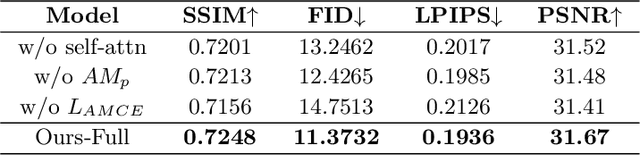
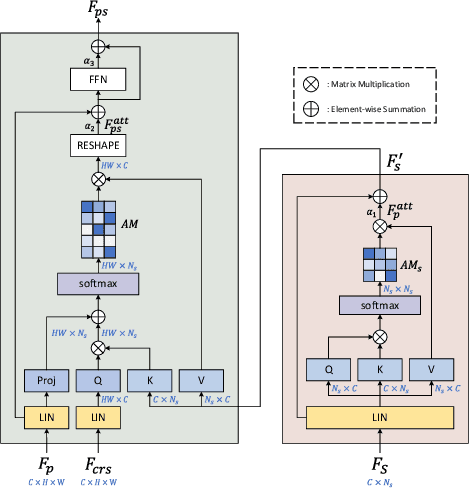
Controllable person image synthesis task enables a wide range of applications through explicit control over body pose and appearance. In this paper, we propose a cross attention based style distribution module that computes between the source semantic styles and target pose for pose transfer. The module intentionally selects the style represented by each semantic and distributes them according to the target pose. The attention matrix in cross attention expresses the dynamic similarities between the target pose and the source styles for all semantics. Therefore, it can be utilized to route the color and texture from the source image, and is further constrained by the target parsing map to achieve a clearer objective. At the same time, to encode the source appearance accurately, the self attention among different semantic styles is also added. The effectiveness of our model is validated quantitatively and qualitatively on pose transfer and virtual try-on tasks.
QS-Attn: Query-Selected Attention for Contrastive Learning in I2I Translation
Mar 16, 2022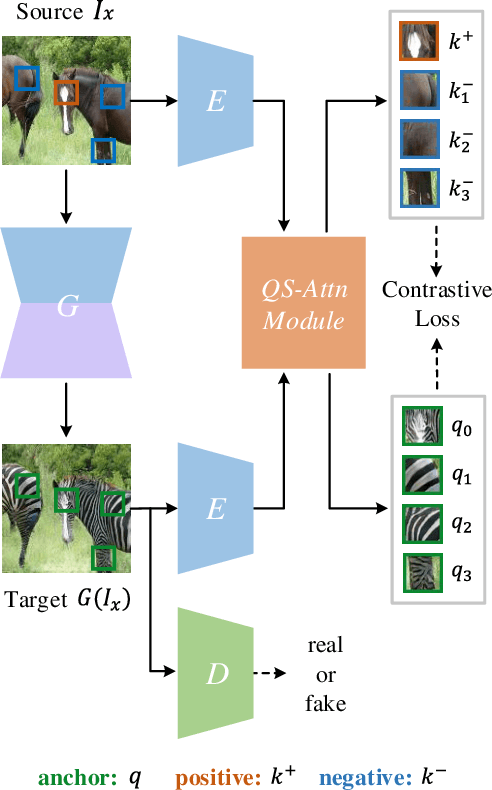
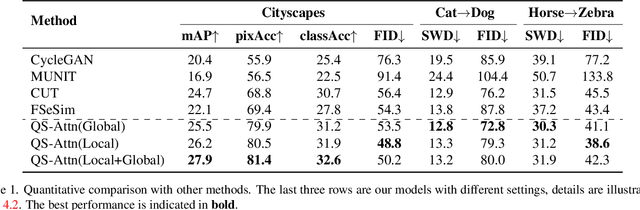

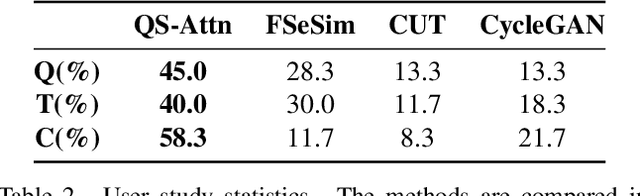
Unpaired image-to-image (I2I) translation often requires to maximize the mutual information between the source and the translated images across different domains, which is critical for the generator to keep the source content and prevent it from unnecessary modifications. The self-supervised contrastive learning has already been successfully applied in the I2I. By constraining features from the same location to be closer than those from different ones, it implicitly ensures the result to take content from the source. However, previous work uses the features from random locations to impose the constraint, which may not be appropriate since some locations contain less information of source domain. Moreover, the feature itself does not reflect the relation with others. This paper deals with these problems by intentionally selecting significant anchor points for contrastive learning. We design a query-selected attention (QS-Attn) module, which compares feature distances in the source domain, giving an attention matrix with a probability distribution in each row. Then we select queries according to their measurement of significance, computed from the distribution. The selected ones are regarded as anchors for contrastive loss. At the same time, the reduced attention matrix is employed to route features in both domains, so that source relations maintain in the synthesis. We validate our proposed method in three different I2I datasets, showing that it increases the image quality without adding learnable parameters.