 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
HelmetPoser: A Helmet-Mounted IMU Dataset for Data-Driven Estimation of Human Head Motion in Diverse Conditions
Sep 08, 2024Helmet-mounted wearable positioning systems are crucial for enhancing safety and facilitating coordination in industrial, construction, and emergency rescue environments. These systems, including LiDAR-Inertial Odometry (LIO) and Visual-Inertial Odometry (VIO), often face challenges in localization due to adverse environmental conditions such as dust, smoke, and limited visual features. To address these limitations, we propose a novel head-mounted Inertial Measurement Unit (IMU) dataset with ground truth, aimed at advancing data-driven IMU pose estimation. Our dataset captures human head motion patterns using a helmet-mounted system, with data from ten participants performing various activities. We explore the application of neural networks, specifically Long Short-Term Memory (LSTM) and Transformer networks, to correct IMU biases and improve localization accuracy. Additionally, we evaluate the performance of these methods across different IMU data window dimensions, motion patterns, and sensor types. We release a publicly available dataset, demonstrate the feasibility of advanced neural network approaches for helmet-based localization, and provide evaluation metrics to establish a baseline for future studies in this field. Data and code can be found at \url{https://lqiutong.github.io/HelmetPoser.github.io/}.
Unifying Visual and Semantic Feature Spaces with Diffusion Models for Enhanced Cross-Modal Alignment
Jul 26, 2024Image classification models often demonstrate unstable performance in real-world applications due to variations in image information, driven by differing visual perspectives of subject objects and lighting discrepancies. To mitigate these challenges, existing studies commonly incorporate additional modal information matching the visual data to regularize the model's learning process, enabling the extraction of high-quality visual features from complex image regions. Specifically, in the realm of multimodal learning, cross-modal alignment is recognized as an effective strategy, harmonizing different modal information by learning a domain-consistent latent feature space for visual and semantic features. However, this approach may face limitations due to the heterogeneity between multimodal information, such as differences in feature distribution and structure. To address this issue, we introduce a Multimodal Alignment and Reconstruction Network (MARNet), designed to enhance the model's resistance to visual noise. Importantly, MARNet includes a cross-modal diffusion reconstruction module for smoothly and stably blending information across different domains. Experiments conducted on two benchmark datasets, Vireo-Food172 and Ingredient-101, demonstrate that MARNet effectively improves the quality of image information extracted by the model. It is a plug-and-play framework that can be rapidly integrated into various image classification frameworks, boosting model performance.
IntTower: the Next Generation of Two-Tower Model for Pre-Ranking System
Oct 18, 2022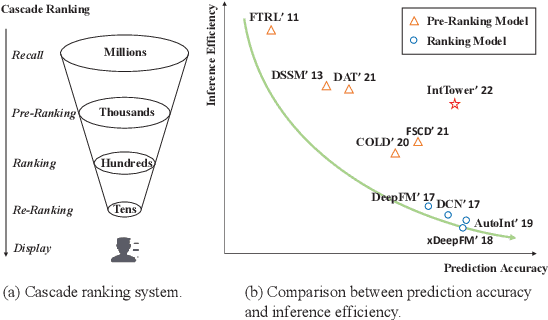
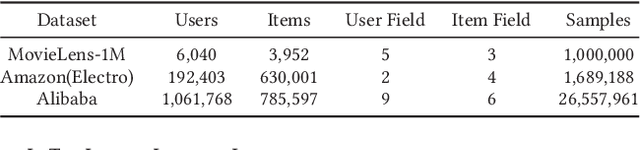
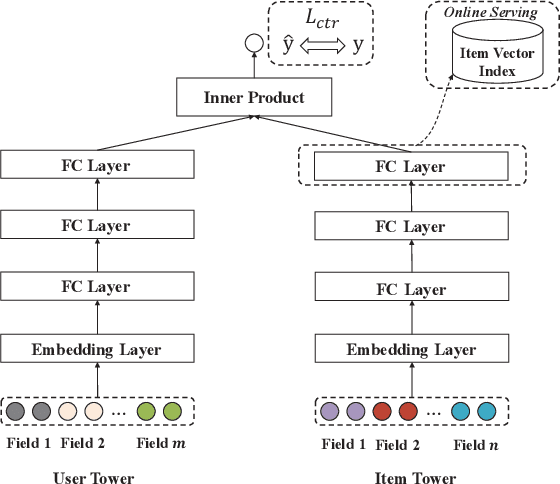
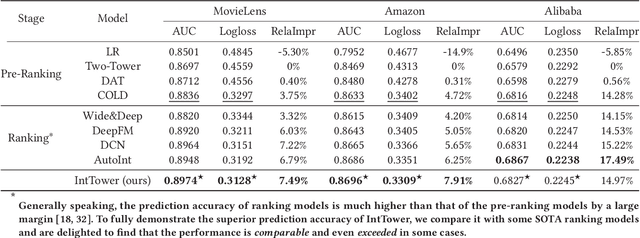
Scoring a large number of candidates precisely in several milliseconds is vital for industrial pre-ranking systems. Existing pre-ranking systems primarily adopt the \textbf{two-tower} model since the ``user-item decoupling architecture'' paradigm is able to balance the \textit{efficiency} and \textit{effectiveness}. However, the cost of high efficiency is the neglect of the potential information interaction between user and item towers, hindering the prediction accuracy critically. In this paper, we show it is possible to design a two-tower model that emphasizes both information interactions and inference efficiency. The proposed model, IntTower (short for \textit{Interaction enhanced Two-Tower}), consists of Light-SE, FE-Block and CIR modules. Specifically, lightweight Light-SE module is used to identify the importance of different features and obtain refined feature representations in each tower. FE-Block module performs fine-grained and early feature interactions to capture the interactive signals between user and item towers explicitly and CIR module leverages a contrastive interaction regularization to further enhance the interactions implicitly. Experimental results on three public datasets show that IntTower outperforms the SOTA pre-ranking models significantly and even achieves comparable performance in comparison with the ranking models. Moreover, we further verify the effectiveness of IntTower on a large-scale advertisement pre-ranking system. The code of IntTower is publicly available\footnote{https://github.com/archersama/IntTower}